Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Umfang und Genauigkeit von Dokumenten — im jeweiligen Bereich
Wir haben die prädiktive Leistung von Deep-Ensembles mit dem während des Tests angewandten Dropout, dem MC-Dropout und einer naiven Softmax-Funktion verglichen, wie in der folgenden Grafik dargestellt. Nach der Inferenz wurden die Prognosen mit den höchsten Unsicherheiten auf verschiedenen Ebenen fallengelassen, sodass sich eine verbleibende Datenabdeckung ergab, die zwischen 10 und 100% lag. Wir gingen davon aus, dass das Deep Ensemble unsichere Vorhersagen effizienter identifizieren würde, da es besser in der Lage ist, epistemische Unsicherheiten zu quantifizieren, d. h. Regionen in den Daten zu identifizieren, in denen das Modell weniger Erfahrung hat. Dies sollte sich in einer höheren Genauigkeit für unterschiedliche Datenerfassungsgrade niederschlagen. Für jedes tiefe Ensemble verwendeten wir 5 Modelle und wendeten 20 Mal Inferenz an. Für den MC-Dropout haben wir die Inferenz für jedes Modell 100 Mal angewendet. Wir haben für jede Methode den gleichen Satz von Hyperparametern und die gleiche Modellarchitektur verwendet.
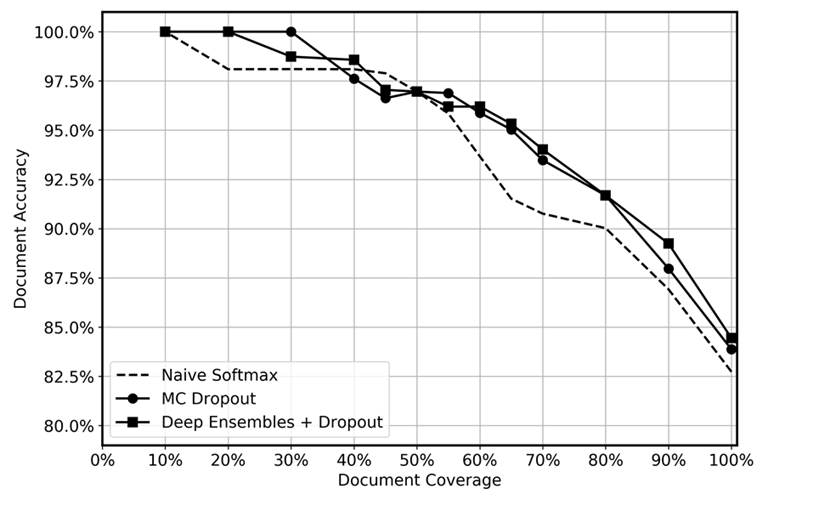
Die Grafik scheint einen leichten Vorteil der Verwendung von Deep-Ensembles und MC-Dropout im Vergleich zu naiven Softmax-Programmen aufzuzeigen. Dies ist im Bereich der Datenabdeckung von 50 bis 80% am deutlichsten. Warum ist das nicht größer? Wie im Abschnitt über tiefe Ensembles erwähnt, liegt die Stärke tiefer Ensembles in den unterschiedlichen Verlustverläufen. In dieser Situation verwenden wir vortrainierte Modelle. Obwohl wir das gesamte Modell feinabstimmen, wird die überwältigende Mehrheit der Gewichte anhand des vortrainierten Modells initialisiert, und nur einige versteckte Ebenen werden nach dem Zufallsprinzip initialisiert. Daher gehen wir davon aus, dass das Vortraining großer Modelle aufgrund der geringen Diversifizierung zu einem übertriebenen Selbstvertrauen führen kann. Unseres Wissens wurde die Wirksamkeit tiefer Ensembles bisher nicht in Transfer-Learning-Szenarien getestet, und wir halten dies für ein spannendes Gebiet für future Forschungen.
