Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Datenlebenszyklus
Um eine Datenpipeline aufzubauen, müssen Sie zunächst Daten aus einer externen oder internen Datenquelle wie einem Dateiserver, einer Datenbank, einem Speicher-Bucket oder aus einem API-Aufruf in AWS aufnehmen. Die aufgenommenen Daten werden möglicherweise transformiert, beispielsweise anonymisiert, Spalten gelöscht oder Daten bereinigt.
Dieser Abschnitt bietet einen Überblick über die Phasen des Datenlebenszyklusprozesses, wie in der folgenden Abbildung dargestellt.
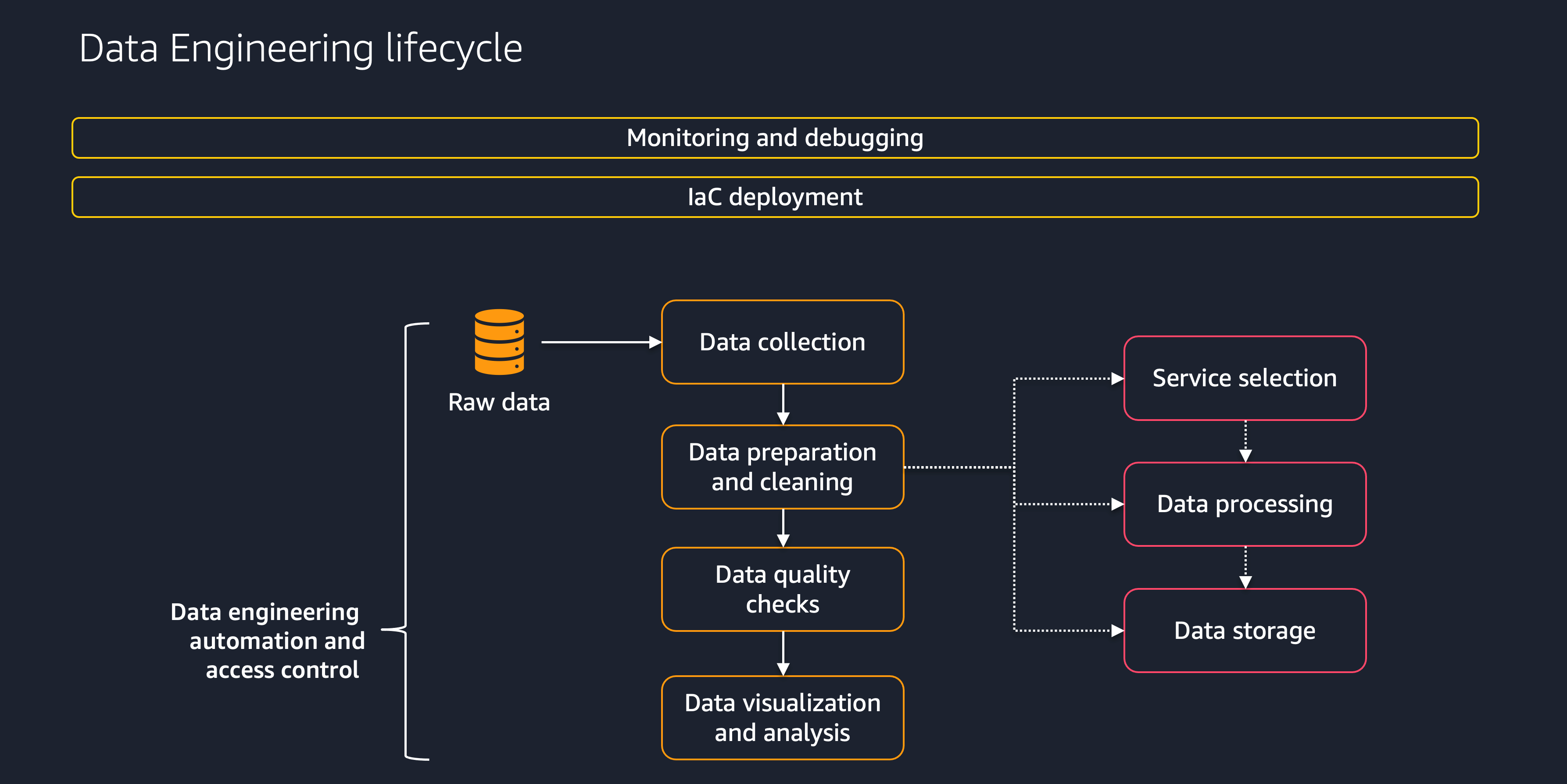
Zu diesen Phasen gehören die folgenden:
-
Datenerfassung
-
Datenaufbereitung und Reinigung
-
Prüfungen der Datenqualität
-
Datenvisualisierung und -analyse
-
Überwachung und Debugging
-
IaC-Bereitstellung
-
Automatisierung und Zugriffskontrolle
