Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Datenaufbereitung und -bereinigung
Die Datenaufbereitung und -bereinigung ist eine der wichtigsten und zeitaufwändigsten Phasen des Datenlebenszyklus. Das folgende Diagramm zeigt, wie sich die Phase der Datenaufbereitung und -bereinigung in den Lebenszyklus der Automatisierung und Zugriffskontrolle der Datentechnik einfügt.
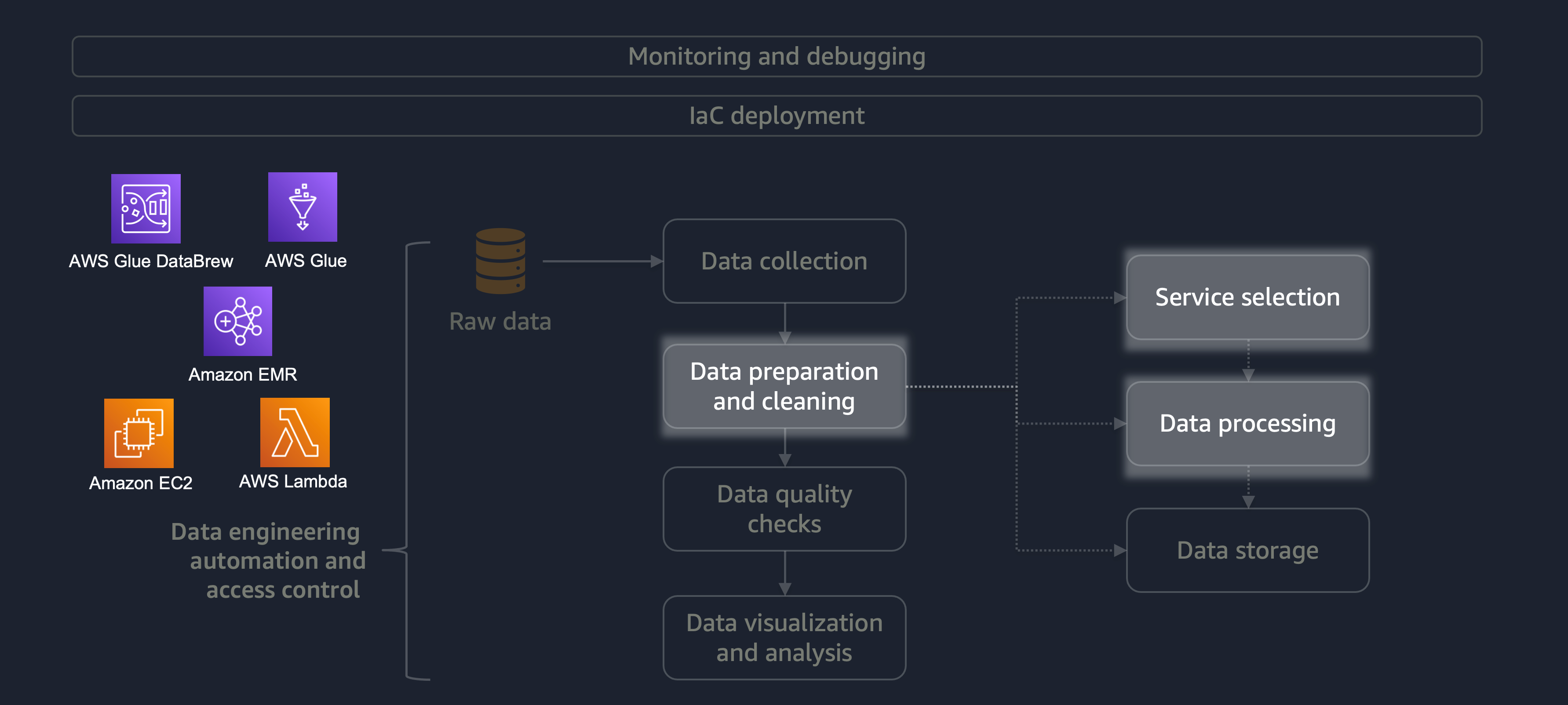
Hier sind einige Beispiele für die Datenaufbereitung oder -bereinigung:
-
Zuordnung von Textspalten zu Codes
-
Leere Spalten werden ignoriert
-
Leere Datenfelder mit
0None, oder füllen'' -
Anonymisierung oder Maskierung personenbezogener Daten (PII)
Wenn Sie einen großen Workload mit einer Vielzahl von Daten haben, empfehlen wir Ihnen, Amazon EMRDataFrame oder mit horizontaler Verarbeitung DynamicFrame zu arbeiten. Darüber hinaus können Sie AWS Glue
Für kleinere Workloads, die keine verteilte Verarbeitung erfordern und in weniger als 15 Minuten abgeschlossen werden können, empfehlen wir die Verwendung von AWS Lambda
Es ist wichtig, den richtigen AWS-Service für die Datenaufbereitung und -bereinigung zu wählen und die Kompromisse zu verstehen, die mit Ihrer Wahl verbunden sind. Stellen Sie sich beispielsweise ein Szenario vor, in dem Sie zwischen AWS Glue und Amazon EMR wählen. DataBrew AWS Glue ist ideal, wenn der ETL-Job selten ist. Ein seltener Job findet einmal am Tag, einmal pro Woche oder einmal im Monat statt. Sie können außerdem davon ausgehen, dass Ihre Dateningenieure im Schreiben von Spark-Code (für Big-Data-Anwendungsfälle) oder im Scripting im Allgemeinen versiert sind. Wenn der Job häufiger ist, kann der ständige Betrieb von AWS Glue teuer werden. In diesem Fall bietet Amazon EMR verteilte Verarbeitungsfunktionen und bietet sowohl eine serverlose als auch eine serverbasierte Version. Wenn Ihre Dateningenieure nicht über die richtigen Fähigkeiten verfügen oder wenn Sie schnell Ergebnisse liefern müssen, DataBrew ist dies eine gute Option. DataBrew kann den Aufwand für die Codeentwicklung reduzieren und den Datenaufbereitungs- und Bereinigungsprozess beschleunigen.
Nach Abschluss der Verarbeitung werden die Daten aus dem ETL-Prozess auf AWS gespeichert. Die Wahl des Speichers hängt davon ab, mit welcher Art von Daten Sie es zu tun haben. Sie könnten beispielsweise mit nicht-relationalen Daten wie Grafikdaten, Schlüssel-Wert-Paardaten, Bildern, Textdateien oder relationalen strukturierten Daten arbeiten.
Wie in der folgenden Abbildung dargestellt, können Sie die folgenden AWS-Services für die Datenspeicherung verwenden:
-
Amazon S3
speichert unstrukturierte oder halbstrukturierte Daten (z. B. Apache Parquet-Dateien, Bilder und Videos). -
Amazon Neptune
speichert Diagrammdatensätze, die Sie mit SPARQL oder GREMLIN abfragen können. -
Amazon Keyspaces (für Apache Cassandra)
speichert Datensätze, die mit Apache Cassandra kompatibel sind. -
Amazon Aurora
speichert relationale Datensätze. -
Amazon DynamoDB
speichert Schlüsselwert- oder Dokumentdaten in einer NoSQL-Datenbank. -
Amazon Redshift
speichert Workloads für strukturierte Daten in einem Data Warehouse.
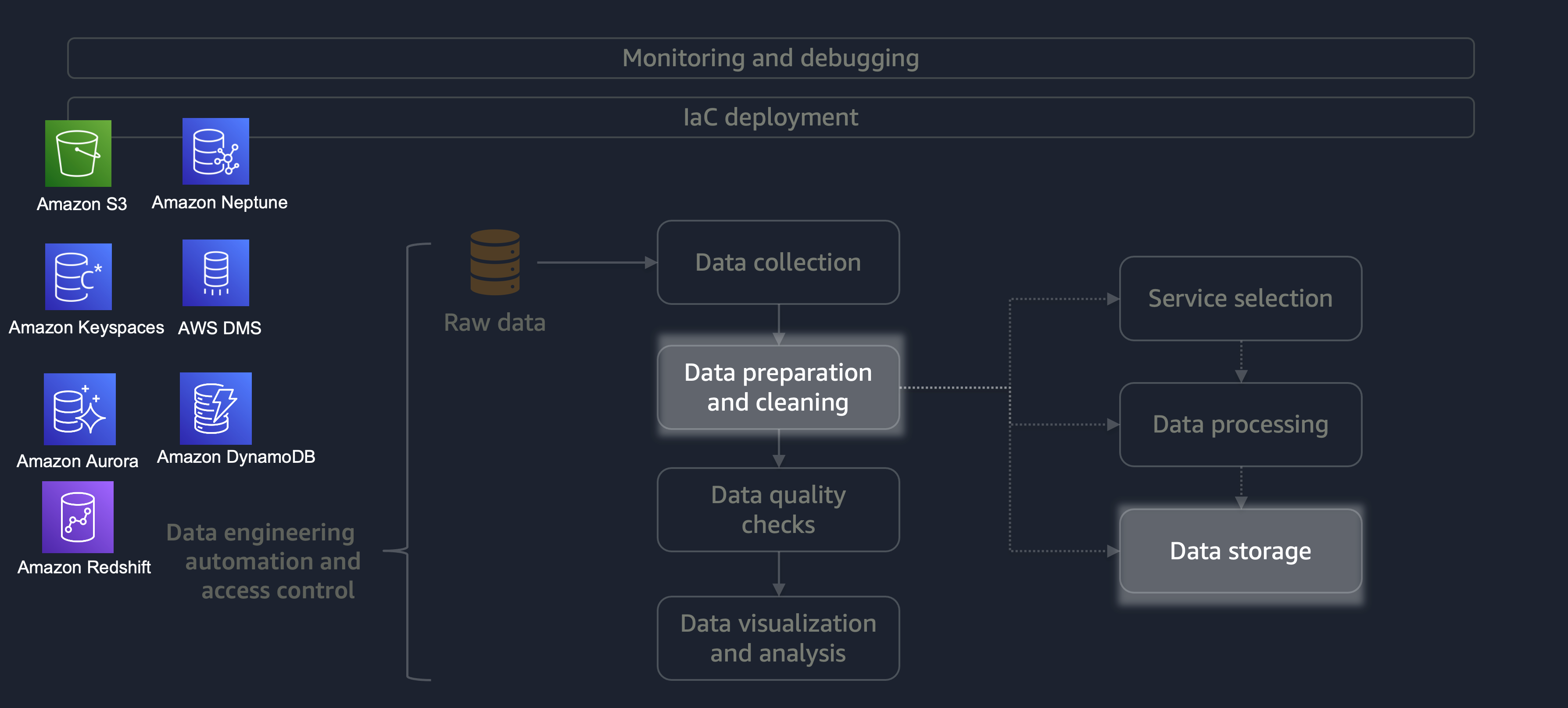
Wenn Sie den richtigen Dienst mit den richtigen Konfigurationen verwenden, können Sie Ihre Daten auf die effizienteste und effektivste Weise speichern. Dadurch wird der Aufwand für das Abrufen von Daten minimiert.
