Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
CQRS-Muster
Das CQRS-Muster (Command Query Responsibility Segregation) trennt die Datenmutation oder den Befehlsteil eines Systems vom Abfrageteil. Sie können das CQRS-Muster verwenden, um Aktualisierungen und Abfragen voneinander zu trennen, wenn sie unterschiedliche Anforderungen an Durchsatz, Latenz oder Konsistenz haben. Das CQRS-Muster unterteilt die Anwendung in zwei Teile — die Befehlsseite und die Abfrageseite —, wie in der folgenden Abbildung dargestellt. Die Befehlsseite verarbeitetcreate, und Anfragen. update delete Die Abfrageseite führt den query Teil mithilfe der Read Replicas aus.
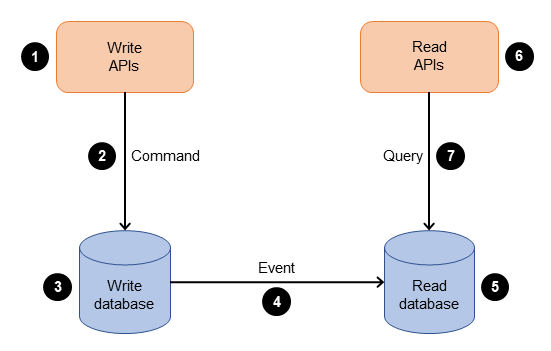
Das Diagramm zeigt den folgenden Prozess:
-
Das Unternehmen interagiert mit der Anwendung, indem es Befehle über eine API sendet. Befehle sind Aktionen wie das Erstellen, Aktualisieren oder Löschen von Daten.
-
Die Anwendung verarbeitet den eingehenden Befehl auf der Befehlsseite. Dies beinhaltet die Validierung, Autorisierung und Ausführung des Vorgangs.
-
Die Anwendung speichert die Daten des Befehls in der Schreibdatenbank (Befehlsdatenbank).
-
Nachdem der Befehl in der Schreibdatenbank gespeichert wurde, werden Ereignisse ausgelöst, um die Daten in der Lesedatenbank (Abfrage) zu aktualisieren.
-
Die Lesedatenbank (Abfrage) verarbeitet die Daten und speichert sie. Lesedatenbanken sind so konzipiert, dass sie für bestimmte Abfrageanforderungen optimiert werden können.
-
Das Unternehmen interagiert mit Read APIs , um Anfragen an die Abfrageseite der Anwendung zu senden.
-
Die Anwendung verarbeitet die eingehende Anfrage auf der Abfrageseite und ruft die Daten aus der gelesenen Datenbank ab.
Sie können das CQRS-Muster implementieren, indem Sie verschiedene Kombinationen von Datenbanken verwenden, darunter:
-
Verwenden von Datenbanken des relationalen Datenbankmanagementsystems (RDBMS) sowohl für die Befehls- als auch für die Abfrageseite. Schreibvorgänge werden an die Primärdatenbank weitergeleitet, und Lesevorgänge können an Lesereplikate weitergeleitet werden. Beispiel: Amazon RDS Read Replicas
-
Verwendung einer RDBMS-Datenbank für die Befehlsseite und einer NoSQL-Datenbank für die Abfrageseite. Beispiel: Modernisieren Sie ältere Datenbanken mithilfe von Event
Sourcing und CQRS mit AWS DMS -
Verwendung von NoSQL-Datenbanken sowohl für die Befehls- als auch für die Abfrageseite. Beispiel: Einen CQRS-Eventspeicher mit Amazon DynamoDB erstellen
-
Verwenden einer NoSQL-Datenbank für die Befehlsseite und einer RDBMS-Datenbank für die Abfrageseite, wie im folgenden Beispiel beschrieben.
In der folgenden Abbildung wird ein NoSQL-Datenspeicher wie DynamoDB verwendet, um den Schreibdurchsatz zu optimieren und flexible Abfragefunktionen bereitzustellen. Dadurch wird eine hohe Schreibskalierbarkeit bei Workloads mit klar definierten Zugriffsmustern erreicht, wenn Sie Daten hinzufügen. Eine relationale Datenbank wie Amazon Aurora bietet komplexe Abfragefunktionen. Ein DynamoDB-Stream sendet Daten an eine Lambda-Funktion, die die Aurora-Tabelle aktualisiert.
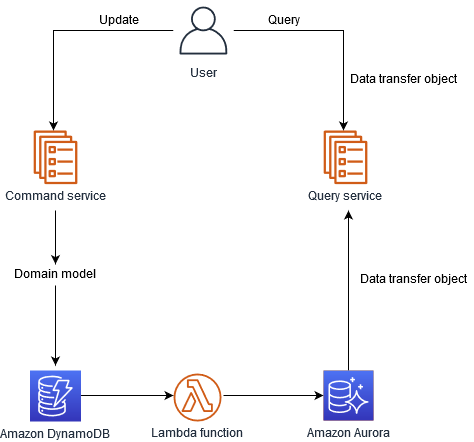
Die Implementierung des CQRS-Musters mit DynamoDB und Aurora bietet die folgenden Hauptvorteile:
-
DynamoDB ist eine vollständig verwaltete NoSQL-Datenbank, die umfangreiche Schreibvorgänge verarbeiten kann, und Aurora bietet eine hohe Leseskalierbarkeit für komplexe Abfragen auf der Abfrageseite.
-
DynamoDB bietet Zugriff auf Daten mit niedriger Latenz und hohem Durchsatz, wodurch es sich ideal für die Bearbeitung von Befehls- und Aktualisierungsvorgängen eignet, und die Aurora-Leistung kann für komplexe Abfragen fein abgestimmt und optimiert werden.
-
Sowohl DynamoDB als auch Aurora bieten serverlose Optionen, sodass Ihr Unternehmen für Ressourcen nur nutzungsabhängig bezahlen kann.
-
DynamoDB und Aurora sind vollständig verwaltete Services, die den betrieblichen Aufwand für die Verwaltung von Datenbanken, Backups und Skalierbarkeit reduzieren.
In folgenden Fällen sollten Sie die Verwendung des CQRS-Musters in Betracht ziehen:
-
Sie haben das database-per-service Muster implementiert und möchten Daten aus mehreren Microservices zusammenführen.
-
Für Ihre Lese- und Schreib-Workloads gelten unterschiedliche Anforderungen in Bezug auf Skalierung, Latenz und Konsistenz.
-
Eventuelle Konsistenz ist für die Leseabfragen akzeptabel.
Wichtig
Das CQRS-Muster führt in der Regel letztendlich zu einer Konsistenz zwischen den Datenspeichern.
