Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Säule der Leistungseffizienz
Die Säule der Leistungseffizienz des AWS Well-Architected Framework konzentriert sich darauf, wie die Leistung beim Einlesen oder Abfragen von Daten optimiert werden kann. Die Leistungsoptimierung ist ein inkrementeller und kontinuierlicher Prozess, der Folgendes umfasst:
-
Bestätigung der Geschäftsanforderungen
-
Messung der Workload-Leistung
-
Identifizierung leistungsschwacher Komponenten
-
Abstimmung der Komponenten auf Ihre Geschäftsanforderungen
Der Schwerpunkt Leistungseffizienz enthält anwendungsfallspezifische Richtlinien, anhand derer Sie das richtige Grafikdatenmodell und die richtigen Abfragesprachen finden können. Es enthält auch bewährte Verfahren, die bei der Aufnahme von Daten in Neptune Analytics und der Nutzung von Daten aus Neptune Analytics befolgt werden sollten.
Der Schwerpunkt der Leistungseffizienz konzentriert sich auf die folgenden Schlüsselbereiche:
-
Graphmodellierung
-
Optimierung von Abfragen
-
Richtige Größe des Diagramms
-
Optimierung schreiben
Verstehen Sie die Graphmodellierung für Analysen
Der Leitfaden Applying the AWS Well-Architected Framework for Amazon Neptune befasst sich mit der Graphmodellierung zur Steigerung der Leistungseffizienz. Zu den Modellierungsentscheidungen, die sich auf die Leistung auswirken, gehören die Auswahl der erforderlichen Knoten und Kanten IDs, ihrer Labels und Eigenschaften, die Richtung der Kanten, ob Beschriftungen generisch oder spezifisch sein sollen und allgemein, wie effizient die Abfrage-Engine im Diagramm navigieren kann, um häufig auftretende Abfragen zu verarbeiten.
Diese Überlegungen gelten auch für Neptune Analytics. Es ist jedoch wichtig, zwischen transaktionalen und analytischen Nutzungsmustern zu unterscheiden. Ein Graphmodell, das für Abfragen in einer Transaktionsdatenbank wie einer Neptune-Datenbank effizient ist, muss möglicherweise für Analysen neu gestaltet werden.
Stellen Sie sich zum Beispiel eine Betrugsgrafik in einer Neptune-Datenbank vor, deren Zweck darin besteht, Kreditkartenzahlungen auf betrügerische Muster zu überprüfen. Dieses Diagramm kann Knoten enthalten, die Konten, Zahlungen und Funktionen (wie E-Mail-Adresse, IP-Adresse, Telefonnummer) sowohl des Kontos als auch der Zahlung darstellen. Dieses verknüpfte Diagramm unterstützt Abfragen wie das Durchlaufen eines Pfads mit variabler Länge, der von einer bestimmten Zahlung ausgeht und mehrere Sprünge benötigt, um verwandte Funktionen und Konten zu finden. Die folgende Abbildung zeigt ein solches Diagramm.
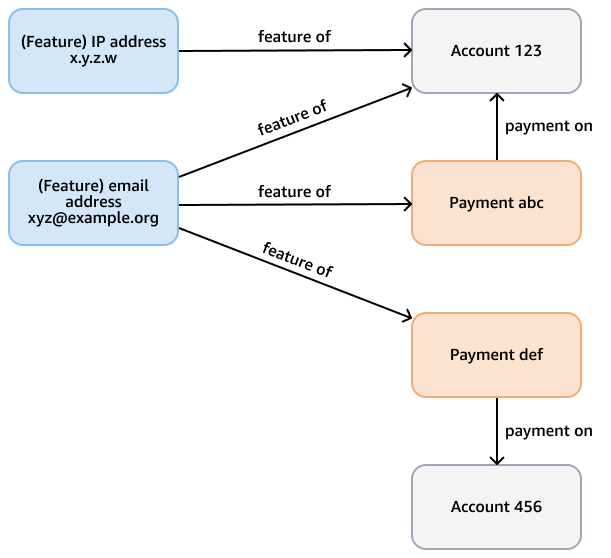
Die Analyseanforderungen könnten spezifischer sein, z. B. das Auffinden von Kontengemeinschaften, die durch ein Feature miteinander verknüpft sind. Zu diesem Zweck können Sie den WCC-Algorithmus (Weakly Connected Components) verwenden. Es ist ineffizient, ihn mit dem Modell aus dem vorherigen Beispiel zu vergleichen, da er mehrere verschiedene Arten von Knoten und Kanten durchqueren muss. Das Modell im nächsten Diagramm ist effizienter. Es verbindet account Knoten mit einer shares feature Kante, wenn die Konten selbst — oder Zahlungen von den Konten — ein gemeinsames Merkmal aufweisen. Account 123Hat zum Beispiel eine E-Mail-Funktion xyz@example.org und Account 456 verwendet dieselbe E-Mail für eine Zahlung (). Payment def

Die Rechenkomplexität von WCC ergibt sich O(|E|logD) aus der Anzahl der Kanten im Graphen und D dem Durchmesser (der Länge des längsten Pfades), der die Knoten verbindet. |E| Da das Transaktionsmodell unwichtige Knoten und Kanten auslässt, werden sowohl die Anzahl der Kanten als auch der Durchmesser optimiert und die Komplexität des WCC-Algorithmus reduziert.
Wenn Sie Neptune Analytics verwenden, gehen Sie von den erforderlichen Algorithmen und analytischen Abfragen aus. Falls erforderlich, gestalten Sie das Modell neu, um diese Abfragen zu optimieren. Sie können das Modell umformen, bevor Sie Daten in das Diagramm laden, oder Abfragen schreiben, die vorhandene Daten im Diagramm ändern.
Optimieren Sie Abfragen
Folgen Sie diesen Empfehlungen, um Neptune Analytics-Abfragen zu optimieren:
-
Verwenden Sie parametrisierte Abfragen und den Abfrageplan-Cache, der standardmäßig aktiviert ist. Wenn Sie den Plan-Cache verwenden, bereitet die Engine die Abfrage für die spätere Verwendung vor — vorausgesetzt, die Abfrage wird in 100 Millisekunden oder weniger abgeschlossen —, wodurch Zeit bei nachfolgenden Aufrufen gespart wird.
-
Führen Sie bei langsamen Abfragen einen Erklärungsplan aus, um Engpässe zu erkennen und entsprechende Verbesserungen vorzunehmen.
-
Wenn Sie die Vektorähnlichkeitssuche verwenden, entscheiden Sie, ob kleinere Einbettungen zu genauen Ähnlichkeitsergebnissen führen. Sie können kleinere Einbettungen effizienter erstellen, speichern und durchsuchen.
-
Folgen Sie den dokumentierten Best Practices für die Verwendung von OpenCypher in Neptune Analytics. Verwenden Sie beispielsweise abgeflachte Maps in einer UNWIND-Klausel und geben Sie nach Möglichkeit Kantenbeschriftungen an.
-
Wenn Sie einen Graphalgorithmus verwenden, sollten Sie sich mit den Eingaben und Ausgaben des Algorithmus, seiner Rechenkomplexität und seiner Funktionsweise im Großen und Ganzen vertraut machen.
-
Bevor Sie einen Graphalgorithmus aufrufen, verwenden Sie eine
MATCHKlausel, um den Eingabeknotensatz zu minimieren. Folgen Sie beispielsweise den Beispielen in der Neptune Analytics-Dokumentation, um Knoten einzuschränken, von denen aus eine Breadth-First-Suche (BFS) durchgeführt werden kann. -
Filtern Sie nach Möglichkeit nach Knoten- und Kantenbeschriftungen. BFS verfügt beispielsweise über Eingabeparameter, um die Durchquerung nach einer bestimmten Knotenbeschriftung (
vertexLabel) oder bestimmten Kantenbeschriftungen () zu filtern.edgeLabels -
Verwenden Sie Begrenzungsparameter, um beispielsweise Ergebnisse einzuschränken
maxDepth. -
Experimentieren Sie mit dem
concurrencyParameter. Versuchen Sie es mit einem Wert von 0, der alle verfügbaren Algorithmus-Threads verwendet, um die Verarbeitung zu parallelisieren. Vergleichen Sie das mit der Single-Thread-Ausführung, indem Sie den Parameter auf 1 setzen. Ein Algorithmus kann in einem einzigen Thread schneller abgeschlossen werden, insbesondere bei kleineren Eingaben, wie z. B. bei Suchanfragen mit oberflächlicher Breite, bei denen Parallelität keine messbare Verkürzung der Ausführungszeit bewirkt und zu Mehraufwand führen kann. -
Wählen Sie zwischen ähnlichen Arten von Algorithmen. Bellman-Ford und Delta-Stepping sind beispielsweise beide Algorithmen mit kürzestem Pfad aus einer einzigen Quelle. Wenn Sie mit Ihrem eigenen Datensatz testen, probieren Sie beide Algorithmen aus und vergleichen Sie die Ergebnisse. Delta-Stepping ist aufgrund seiner geringeren Rechenkomplexität oft schneller als Bellman-Ford. Die Leistung hängt jedoch vom Datensatz und den Eingabeparametern ab, insbesondere vom Parameter.
delta
-
Schreibvorgänge optimieren
Gehen Sie wie folgt vor, um Schreibvorgänge in Neptune Analytics zu optimieren:
-
Suchen Sie nach dem effizientesten Weg, Daten in ein Diagramm zu laden. Wenn Sie Daten aus Amazon S3 laden, verwenden Sie den Massenimport, wenn die Daten größer als 50 GB sind. Verwenden Sie für kleinere Daten das Batch-Laden. Wenn beim Batch-Load out-of-memory Fehler auftreten, sollten Sie erwägen, den m-NCU-Wert zu erhöhen oder die Last in mehrere Anfragen aufzuteilen. Eine Möglichkeit, dies zu erreichen, besteht darin, Dateien auf mehrere Präfixe im S3-Bucket aufzuteilen. Rufen Sie in diesem Fall Batch Load für jedes Präfix separat auf.
-
Verwenden Sie den Massenimport oder den Batch-Loader, um den ersten Satz von Grafikdaten aufzufüllen. Verwenden Sie transaktionale OpenCypher-Operationen zum Erstellen, Aktualisieren und Löschen nur für kleine Änderungen.
-
Verwenden Sie entweder den Massenimport oder den Batch-Loader mit einer Parallelität von 1 (Single-Thread), um Einbettungen in das Diagramm aufzunehmen. Versuchen Sie, Einbettungen mit einer dieser Methoden im Voraus zu laden.
-
Beurteilen Sie die Größe der Vektoreinbettungen, die für eine genaue Ähnlichkeitssuche in Algorithmen zur Suche nach Vektorähnlichkeit erforderlich sind. Verwenden Sie nach Möglichkeit eine kleinere Dimension. Dies führt zu einer schnelleren Ladegeschwindigkeit für Einbettungen.
-
Verwenden Sie bei Bedarf mutierte Algorithmen, um sich algorithmische Ergebnisse zu merken. Der Algorithmus Degree Mutate Centrality ermittelt beispielsweise den Grad jedes Eingabeknotens und schreibt diesen Wert als Eigenschaft des Knotens. Wenn sich die Verbindungen, die diese Knoten umgeben, anschließend nicht ändern, enthält die Eigenschaft das richtige Ergebnis. Der Algorithmus muss nicht erneut ausgeführt werden.
-
Verwenden Sie die administrative Aktion zum Zurücksetzen des Graphen, um alle Knoten, Kanten und Einbettungen zu löschen, falls Sie von vorne beginnen müssen. Das Löschen aller Knoten, Kanten und Einbettungen mithilfe einer OpenCypher-Abfrage ist nicht möglich, wenn Ihr Diagramm groß ist. Eine einzelne Drop-Abfrage für einen großen Datensatz kann zu einer Zeitüberschreitung führen. Mit zunehmender Größe dauert es länger, bis der Datensatz entfernt wird, und die Transaktionsgröße nimmt zu. Im Gegensatz dazu ist die Zeit bis zum Zurücksetzen eines Diagramms in etwa konstant, und die Aktion bietet die Möglichkeit, vor der Ausführung einen Snapshot zu erstellen.
Diagramme in der richtigen Größe
Die Gesamtleistung hängt von der bereitgestellten Kapazität eines Neptune Analytics-Diagramms ab. Die Kapazität wird in Einheiten gemessen, die als speicheroptimierte Neptun-Kapazitätseinheiten (m-) bezeichnet werden. NCUs Stellen Sie sicher, dass Ihr Diagramm ausreichend groß ist, um Ihre Grafikgröße und Abfragen zu unterstützen. Beachten Sie, dass eine höhere Kapazität nicht unbedingt die Leistung einer einzelnen Abfrage verbessert.
Wenn möglich, erstellen Sie das Diagramm, indem Sie Daten aus einer vorhandenen Quelle wie Amazon S3 oder einem vorhandenen Neptune-Cluster oder -Snapshot importieren. Sie können Grenzen für die Mindest- und Höchstkapazität festlegen. Sie können die bereitgestellte Kapazität auch in einem vorhandenen Diagramm ändern.
Überwachen Sie CloudWatch Kennzahlen wieNumQueuedRequestsPerSec,,, undCPUUtilization,,,NumOpenCypherRequestsPerSec,,,GraphStorageUsagePercent,,GraphSizeBytes,,,,,,,,,,,,,,,,,,,, Stellen Sie fest, ob mehr Kapazität benötigt wird, um die Größe und Auslastung Ihres Diagramms zu unterstützen. Weitere Informationen zur Interpretation einiger dieser Kennzahlen finden Sie im Abschnitt Operationelle Exzellenz.
