Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Migrieren Sie Daten mithilfe AWS Cloud von Starburst auf die
Antony Prasad Thevaraj und Suresh Veeragoni, Amazon Web Services
Shaun Van Staden, keiner
Übersicht
Starburst hilft Ihnen dabei, Ihre Datenmigration zu Amazon Web Services (AWS) zu beschleunigen, indem es eine Abfrage-Engine für Unternehmen bereitstellt, die bestehende Datenquellen in einem einzigen Zugriffspunkt zusammenführt. Sie können Analysen für mehrere Datenquellen durchführen, um wertvolle Erkenntnisse zu gewinnen, bevor Sie Migrationspläne fertigstellen. Ohne die business-as-usual Analytik zu unterbrechen, können Sie die Daten mithilfe der Starburst-Engine oder einer speziellen ETL-Anwendung (Extrahieren, Transformieren und Laden) migrieren.
Voraussetzungen und Einschränkungen
Voraussetzungen
Ein aktiver AWS-Konto
Eine virtuelle private Cloud (VPC)
Ein Amazon Elastic Kubernetes Service (Amazon EKS) -Cluster
Eine Amazon Elastic Compute Cloud (Amazon EC2) Auto Scaling Scaling-Gruppe
Eine Liste der aktuellen System-Workloads, die migriert werden müssen
Netzwerkkonnektivität von AWS zu Ihrer lokalen Umgebung
Architektur
Referenzarchitektur
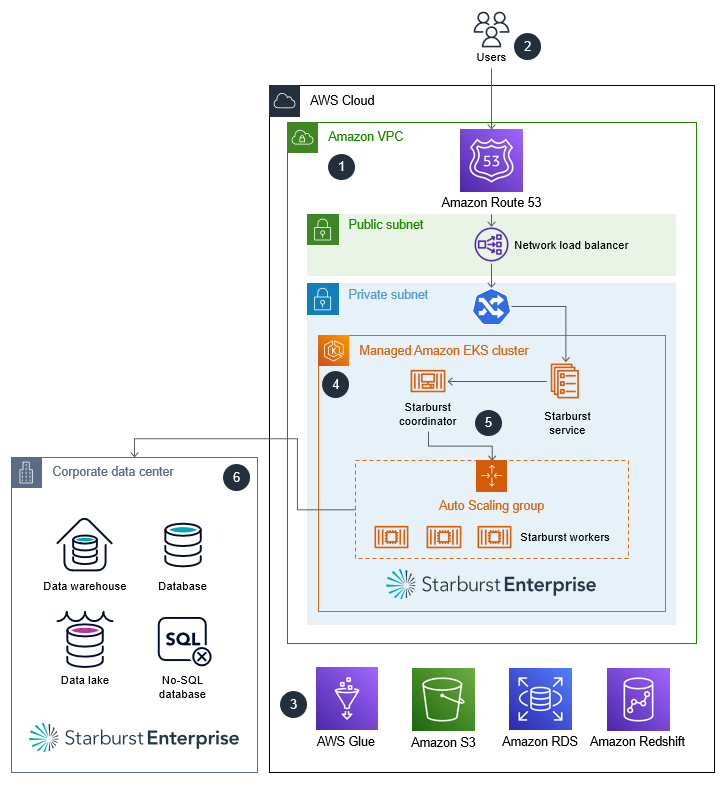
Das folgende Architekturdiagramm auf hoher Ebene zeigt den typischen Einsatz von Starburst Enterprise in: AWS Cloud
Der Starburst Enterprise-Cluster läuft in Ihrem. AWS-Konto
Ein Benutzer authentifiziert sich mithilfe des Lightweight Directory Access Protocol (LDAP) oder Open Authorization (OAuth) und interagiert direkt mit dem Starburst-Cluster.
Starburst kann eine Verbindung zu verschiedenen AWS Datenquellen herstellen, z. B. AWS Glue Amazon Simple Storage Service (Amazon S3), Amazon Relational Database Service (Amazon RDS) und Amazon Redshift. Starburst bietet föderierte Abfragefunktionen für alle Datenquellen in der AWS Cloud, vor Ort oder in anderen Cloud-Umgebungen.
Sie starten Starburst Enterprise in einem Amazon EKS-Cluster mithilfe von Helm-Diagrammen.
Starburst Enterprise verwendet Amazon EC2 Auto Scaling Scaling-Gruppen und Amazon EC2 Spot-Instances, um die Infrastruktur zu optimieren.
Starburst Enterprise stellt eine direkte Verbindung zu Ihren vorhandenen lokalen Datenquellen her, um Daten in Echtzeit zu lesen. Wenn Sie eine bestehende Starburst Enterprise-Bereitstellung in dieser Umgebung haben, können Sie außerdem Ihren neuen Starburst-Cluster im direkt mit diesem vorhandenen Cluster verbinden. AWS Cloud
Beachten Sie bitte Folgendes:
Starburst ist keine Datenvirtualisierungsplattform. Es handelt sich um eine SQL-basierte MPP-Abfrage-Engine (Massively Parallel Processing), die die Grundlage einer umfassenden Data-Mesh-Strategie für Analysen bildet.
Wenn Starburst im Rahmen einer Migration bereitgestellt wird, ist es direkt mit der vorhandenen lokalen Infrastruktur verbunden.
Starburst bietet mehrere integrierte Unternehmens- und Open-Source-Konnektoren, die die Konnektivität zu einer Vielzahl von Altsystemen erleichtern. Eine vollständige Liste der Konnektoren und ihrer Funktionen finden Sie unter Konnektoren
im Starburst Enterprise-Benutzerhandbuch. Starburst kann Daten in Echtzeit aus lokalen Datenquellen abfragen. Dies verhindert Unterbrechungen des regulären Geschäftsbetriebs während der Datenmigration.
Wenn Sie von einer bestehenden lokalen Starburst Enterprise-Bereitstellung migrieren, können Sie einen speziellen Konnektor, Starburst Stargate, verwenden, um Ihren Starburst Enterprise-Cluster direkt mit Ihrem lokalen Cluster zu verbinden. AWS Dies bietet zusätzliche Leistungsvorteile, wenn Geschäftsanwender und Datenanalysten Abfragen aus der Umgebung in Ihre lokale Umgebung zusammenführen. AWS Cloud
Allgemeiner Überblick über die Prozesse
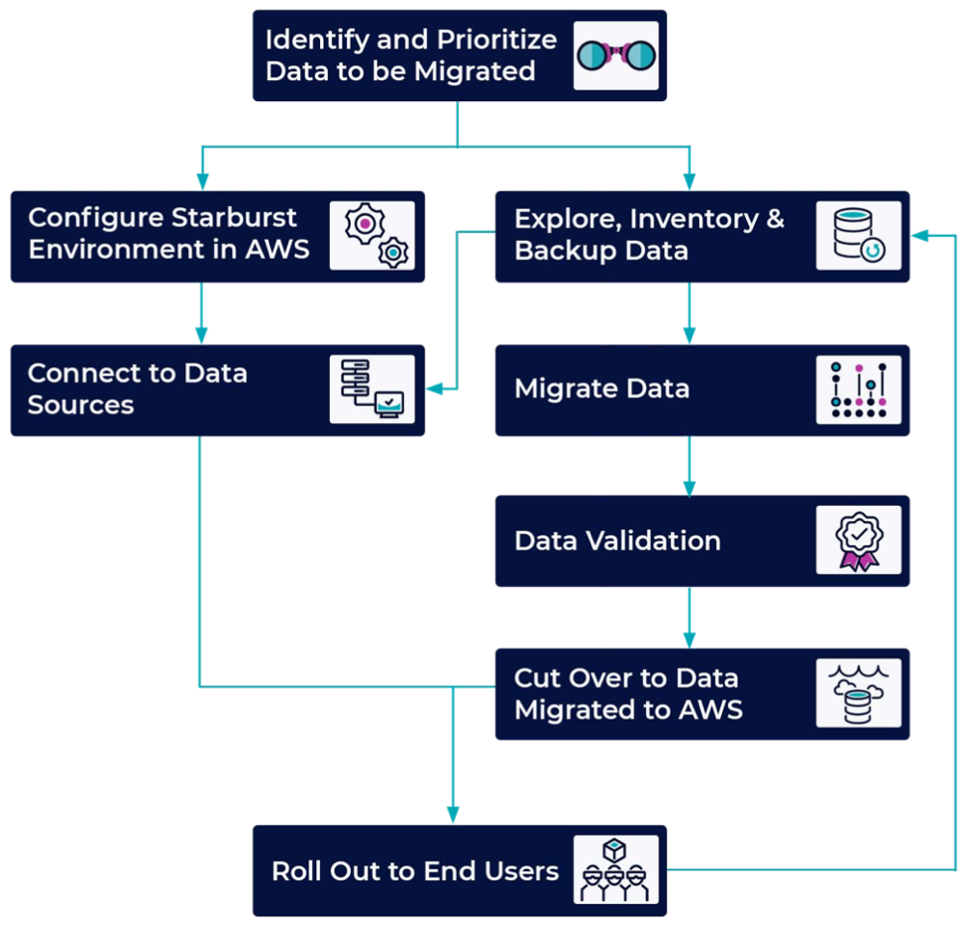
Mit Starburst können Sie Datenmigrationsprojekte beschleunigen, da Starburst Einblicke in all Ihre Daten ermöglicht, bevor Sie sie migrieren. Die folgende Abbildung zeigt den typischen Prozess für die Datenmigration mithilfe von Starburst.
Rollen
Die folgenden Rollen sind in der Regel erforderlich, um eine Migration mit Starburst abzuschließen:
Cloud-Administrator — Verantwortlich für die Bereitstellung von Cloud-Ressourcen für die Ausführung der Starburst Enterprise-Anwendung
Starburst-Administrator — Verantwortlich für die Installation, Konfiguration, Verwaltung und Unterstützung der Starburst-Anwendung
Dateningenieur — Verantwortlich für:
Migration der Altdaten in die Cloud
Erstellung semantischer Ansichten zur Unterstützung von Analysen
Lösungs- oder Systemeigentümer — Verantwortlich für die Implementierung der Gesamtlösung
Tools
AWS-Services
Amazon Elastic Compute Cloud (Amazon EC2) bietet skalierbare Rechenkapazität in der AWS Cloud. Sie können so viele virtuelle Server wie nötig nutzen und sie schnell nach oben oder unten skalieren.
Mit Amazon Elastic Kubernetes Service (Amazon EKS) können Sie Kubernetes ausführen, AWS ohne dass Sie Ihre eigene Kubernetes-Steuerebene oder Knoten installieren oder verwalten müssen.
Andere Tools
Helm — Helm
ist ein Paketmanager für Kubernetes, der Sie bei der Installation und Verwaltung von Anwendungen auf Ihrem Kubernetes-Cluster unterstützt. Starburst Enterprise
— Starburst Enterprise ist eine SQL-basierte MPP-Abfrage-Engine (Massively Parallel Processing), die die Grundlage einer umfassenden Data-Mesh-Strategie für Analysen bildet. Starburst Stargate
— Starburst Stargate verknüpft Kataloge und Datenquellen in einer Starburst Enterprise-Umgebung, z. B. einen Cluster in einem lokalen Rechenzentrum, mit den Katalogen und Datenquellen in einer anderen Starburst Enterprise-Umgebung, z. B. einem Cluster in der. AWS Cloud
Epen
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Identifizieren und priorisieren Sie Ihre Daten. | Identifizieren Sie die Daten, die Sie verschieben möchten. Große, lokale Altsysteme können neben Daten, die Sie migrieren möchten, auch Daten enthalten, die Sie aus Compliance-Gründen nicht verschieben möchten oder die nicht verschoben werden können. Wenn Sie mit einem Dateninventar beginnen, können Sie Prioritäten setzen, auf welche Daten Sie zuerst abzielen sollten. Weitere Informationen finden Sie unter Erste Schritte mit der automatisierten Portfolioerkennung. | Dateningenieur, DBA |
Erkunden, inventarisieren und sichern Sie Ihre Daten. | Überprüfen Sie die Qualität, Quantität und Relevanz der Daten für Ihren Anwendungsfall. Sichern oder erstellen Sie nach Bedarf einen Snapshot der Daten und stellen Sie die Zielumgebung für die Daten fertig. | Dateningenieur, DBA |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Konfigurieren Sie Starburst Enterprise in der AWS Cloud. | Richten Sie Starburst Enterprise in einem verwalteten Amazon EKS-Cluster ein, während die Daten katalogisiert werden. Weitere Informationen finden Sie unter Deployment with Kubernetes | AWS-Administrator, App-Entwickler |
Connect Starburst mit den Datenquellen. | Nachdem Sie die Daten identifiziert und Starburst Enterprise eingerichtet haben, verbinden Sie Starburst mit den Datenquellen. Starburst liest Daten direkt aus der Datenquelle als SQL-Abfrage. Weitere Informationen finden Sie in der Starburst Enterprise-Referenzdokumentation. | AWS-Administrator, App-Entwickler |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Erstellen und betreiben Sie die ETL-Pipelines. | Beginnen Sie mit dem Datenmigrationsprozess. Diese Aktivität kann gleichzeitig mit der business-as-usual Analyse erfolgen. Für die Migration können Sie ein Drittanbieterprodukt oder Starburst verwenden. Starburst ist in der Lage, Daten aus verschiedenen Quellen sowohl zu lesen als auch zu schreiben. Weitere Informationen finden Sie in der Starburst Enterprise-Referenzdokumentation. | Dateningenieur |
Validieren Sie die Daten. | Nachdem die Daten migriert wurden, validieren Sie die Daten, um sicherzustellen, dass alle erforderlichen Daten verschoben wurden und intakt sind. | Dateningenieur, DevOps Ingenieur |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Überschneide die Daten. | Nach Abschluss der Datenmigration und -validierung können Sie die Daten überarbeiten. Dies beinhaltet das Ändern der Datenverbindungslinks in Starburst. Anstatt auf die lokalen Quellen zu verweisen, verweisen Sie auf die neuen Cloud-Quellen und aktualisieren die semantischen Ansichten. Weitere Informationen finden Sie unter Connectors | Dateningenieur, Cutover-Leiter |
Für Benutzer verfügbar machen. | Datenkonsumenten beginnen, mit den migrierten Datenquellen zu arbeiten. Dieser Prozess ist für die Analytics-Endbenutzer unsichtbar. | Leiter der Umstellung, Dateningenieur |
Zugehörige Ressourcen
AWS Marketplace
Starburst-Dokumentation
Andere Dokumentation AWS
