Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verarbeitung von SQL-Abfragen in Amazon Redshift
Amazon Redshift leitet eingegebene SQL-Abfragen an den Parser und den Optimierer weiter, der einen Abfrageplan erstellt. Anschließend übersetzt die Ausführungs-Engine den Abfrageplan in einen ausführbaren Code und sendet diesen zur Ausführung an die Verarbeitungsknoten. Bevor Sie einen Abfrageplan entwerfen, ist es wichtig zu verstehen, wie die Abfrageverarbeitung funktioniert.
Workflow der Abfrageplanung und -ausführung
Das folgende Diagramm bietet einen allgemeinen Überblick über den Arbeitsablauf bei der Planung und Ausführung von Abfragen.
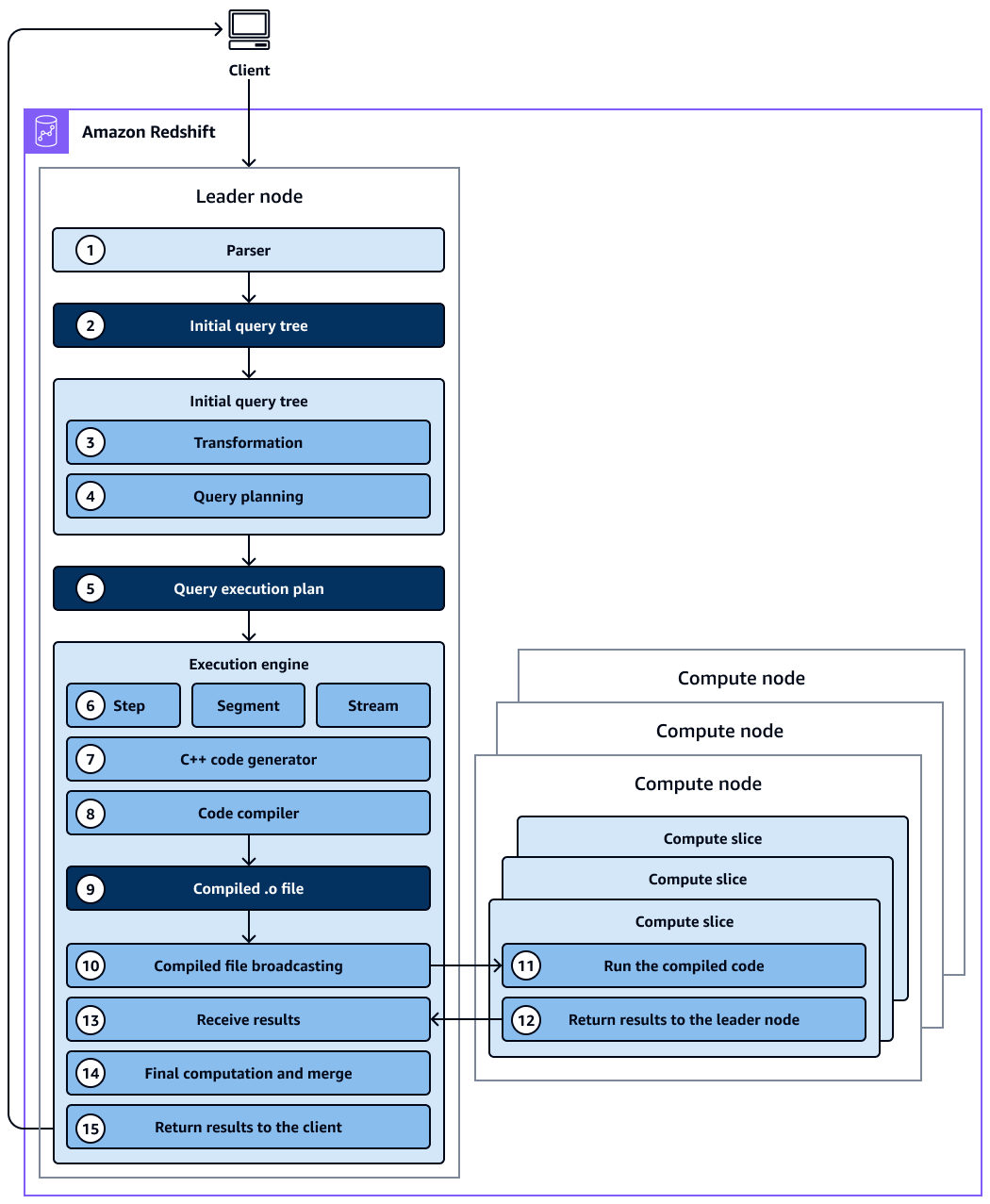
Das Diagramm zeigt den folgenden Workflow:
-
Der Leader-Knoten im Amazon Redshift Redshift-Cluster empfängt die Abfrage und analysiert die SQL-Anweisung.
-
Der Parser erzeugt einen ersten Abfragebaum, der eine logische Darstellung der ursprünglichen Abfrage darstellt.
-
Der Abfrageoptimierer wertet den ursprünglichen Abfragebaum aus, analysiert Tabellenstatistiken, um die Reihenfolge der Verknüpfungen und die Selektivität der Prädikate zu ermitteln, und schreibt die Abfrage bei Bedarf neu, um ihre Effizienz zu maximieren. Manchmal kann eine einzelne Abfrage als mehrere abhängige Anweisungen im Hintergrund geschrieben werden.
-
Der Optimierer erzeugt für diese transformierten Abfragestrukturen einen Abfrageplan, in dem der Ausführungsablauf mit der besten Ausführungsperformance. Der Abfrageplan spezifiziert Ausführungsoptionen wie Ausführungsreihenfolge, Netzwerkoperationen, Verbindungstypen, Verbindungsreihenfolge, Aggregationsoptionen und Datenverteilungen.
-
Ein Abfrageplan enthält Informationen zu den einzelnen Vorgängen, die zum Ausführen einer Abfrage erforderlich sind. Sie können den Befehl
EXPLAINverwenden, um den Abfrageplan anzuzeigen. Der Abfrageplan ist ein grundlegendes Werkzeug für die Analyse und Optimierung komplexer Abfragen. -
Der Abfrageoptimierer sendet den Abfrageplan an die Ausführungs-Engine. Die Ausführungs-Engine überprüft den kompilierten Plan-Cache auf eine Übereinstimmung mit dem Abfrageplan und verwendet den kompilierten Cache (falls gefunden). Andernfalls übersetzt das Ausführungsmodul den Abfrageplan in Schritte, Segmente und Streams:
-
Schritte sind einzelne Operationen, die während der Abfrageausführung stattfinden. Schritte werden durch eine Bezeichnung gekennzeichnet (z. B.
scan,dist,hjoin, odermerge). Ein Schritt ist die kleinste Einheit. Sie können Schritte kombinieren, sodass Rechenknoten eine Abfrage, einen Join oder einen anderen Datenbankvorgang ausführen können. -
Ein Segment bezieht sich auf ein Segment einer Abfrage und kombiniert mehrere Schritte, die von einem einzigen Prozess ausgeführt werden können. Ein Segment ist die kleinste Kompilierungseinheit, die von einem Compute-Node-Slice ausgeführt werden kann. Ein Slice ist die Parallelverarbeitungseinheit in Amazon Redshift.
-
Ein Stream ist eine Sammlung von Segmenten, die über die verfügbaren Compute-Node-Slices aufgeteilt werden. Die Segmente in einem Stream laufen parallel über Knotensegmente. Daher wird derselbe Schritt aus demselben Segment auch parallel in mehreren Schichten ausgeführt.
-
-
Der Codegenerator empfängt den übersetzten Plan und generiert für jedes Segment eine C++-Funktion.
-
Die generierte C++-Funktion wird von der GNU Compiler Collection kompiliert und in eine O (
.o) -Datei konvertiert. -
Der kompilierte Code (O-Datei) wird ausgeführt. Kompilierter Code wird schneller ausgeführt als interpretierter Code und verbraucht auch weniger Rechenkapazität.
-
Die kompilierte O-Datei wird dann an die Rechenknoten gesendet.
-
Jeder Rechenknoten besteht aus mehreren Compute-Slices. Die Compute Slices führen die Abfragesegmente parallel aus. Amazon Redshift nutzt die Vorteile der optimierten Netzwerkkommunikation, des Speichers und der Festplattenverwaltung, um Zwischenergebnisse von einem Abfrageplanschritt zum nächsten weiterzuleiten. Dies trägt auch dazu bei, die Ausführung von Abfragen zu beschleunigen. Berücksichtigen Sie dabei Folgendes:
-
Die Schritte 6, 7, 8, 9, 10 und 11 werden einmal für jeden Stream ausgeführt.
-
Die Engine erstellt die ausführbaren Segmente für einen Stream und sendet diese Segmente an die Rechenknoten.
-
Nachdem die Segmente eines vorherigen Streams fertiggestellt wurden, generiert die Engine die Segmente für den nächsten Stream. Dies ermöglicht der Engine eine Analyse des jeweiligen vorangehenden Streams, beispielsweise, ob die Operationen datenträgerbasiert waren, und eine Optimierung der Generierung der Segmente für den nächsten Stream.
-
-
Nachdem die Rechenknoten fertig sind, senden sie die Abfrageergebnisse zur endgültigen Verarbeitung an den Leader-Knoten zurück. Der Leader-Knoten führt die Daten zu einem einzigen Ergebnissatz zusammen und kümmert sich um alle erforderlichen Sortierungs- oder Aggregationsvorgänge.
-
Der Leader-Knoten gibt die Ergebnisse an den Client zurück.
Das folgende Diagramm zeigt den Ausführungsablauf von Streams, Segmenten, Schritten und Compute-Node-Slices. Beachten Sie Folgendes:
-
Die Schritte in einem Segment werden sequentiell ausgeführt.
-
Segmente in einem Stream laufen parallel.
-
Streams werden sequentiell ausgeführt.
-
Compute Node Slices laufen parallel.
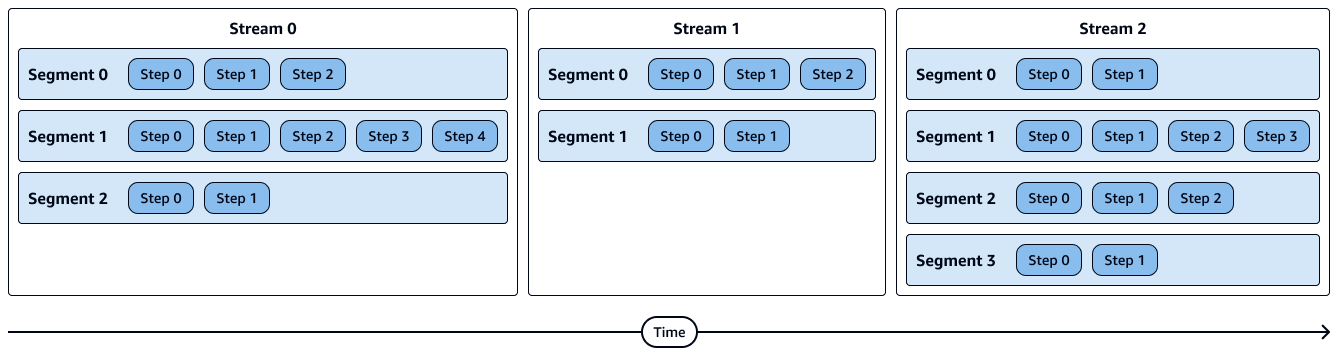
Das folgende Diagramm zeigt eine visuelle Darstellung von Streams, Segmenten und Schritten. Jedes Segment enthält mehrere Schritte, und jeder Stream enthält mehrere Segmente.
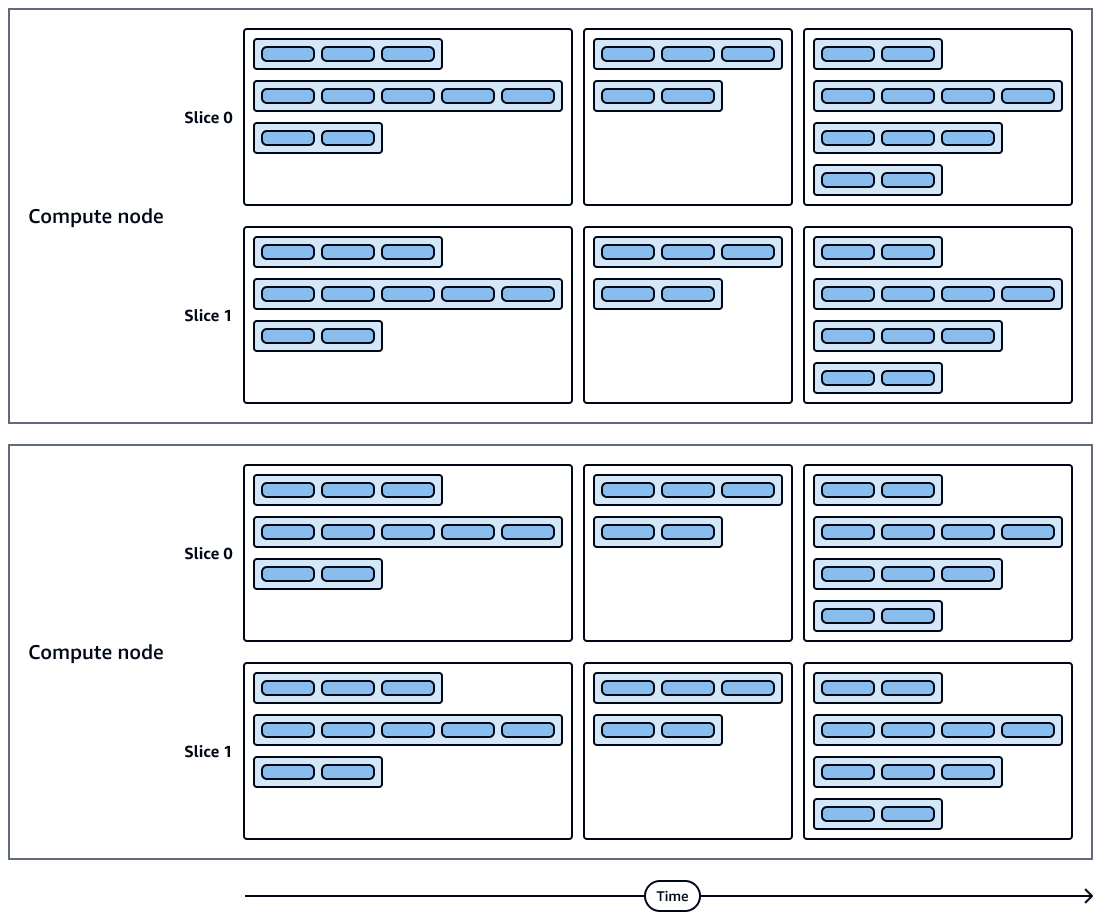
Das folgende Diagramm zeigt eine visuelle Darstellung der Abfrageausführungen und der Berechnung von Node-Slices. Jeder Rechenknoten enthält mehrere Bereiche, Streams, Segmente und Schritte.
Weitere Überlegungen
Wir empfehlen Ihnen, bei der Abfrageverarbeitung Folgendes zu beachten:
-
Im Cache zwischengespeicherter kompilierter Code wird von mehreren Sitzungen auf demselben Cluster gemeinsam genutzt, sodass nachfolgende Ausführungen derselben Abfrage schneller sind, oft sogar mit unterschiedlichen Parametern.
-
Wenn Sie Ihre Abfragen vergleichen, empfehlen wir, immer die Zeiten für die zweite Ausführung einer Abfrage zu vergleichen, da die erste Ausführungszeit den Aufwand für die Kompilierung des Codes beinhaltet. Weitere Informationen finden Sie unter Leistungsfaktoren für Abfragen im Leitfaden Best Practices für Amazon Redshift für Abfragen.
-
Die Rechenknoten könnten bei Bedarf während der Abfrageausführung einige Daten an den Leader-Knoten zurückgeben. Wenn Sie beispielsweise eine Unterabfrage mit einer
LIMITKlausel haben, wird das Limit auf den Leader-Knoten angewendet, bevor die Daten zur weiteren Verarbeitung im Cluster neu verteilt werden.
