Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwenden von Hinweisen zum Beitritt in Spark SQL
Mit Spark 3.0 können Sie den gewünschten Join-Algorithmus angeben Spark zur Laufzeit zu verwenden. Die Join-Strategie gibt HinweiseBROADCAST,MERGE,SHUFFLE_HASH, undSHUFFLE_REPLICATE_NL, instruct Spark die angedeutete Strategie auf jede angegebene Beziehung anzuwenden, wenn sie mit einer anderen Beziehung verknüpft wird. In diesem Abschnitt werden die Hinweise zur Verbindungsstrategie ausführlich behandelt.
ÜBERTRAGUNG
Bei einem Broadcast-Hash-Join ist einer der Datensätze deutlich kleiner als der andere. Da der kleinere Datensatz in den Arbeitsspeicher passt, wird er an alle Executoren im Cluster übertragen. Nach der Übertragung der Daten wird ein Standard-Hash-Join durchgeführt. Ein Broadcast-Hash-Join erfolgt in zwei Schritten:
-
Broadcast — Der kleinere Datensatz wird an alle Executoren innerhalb des Clusters gesendet.
-
Hash-Join — Der kleinere Datensatz wird für alle Executoren gehasht und dann mit dem größeren Datensatz verknüpft.
Es gibt keine Oder-Operation. sort merge Beim Verbinden großer Faktentabellen mit Tabellen mit kleineren Dimensionen, die für eine Star-Schema-Verknüpfung verwendet werden, ist Broadcast Hash der schnellste Join-Algorithmus. Das folgende Beispiel zeigt, wie ein Broadcast-Hash-Join funktioniert. Die Join-Seite mit dem Hinweis wird übertragen, unabhängig von der in der spark.sql.autoBroadcastJoinThreshold Eigenschaft angegebenen Größenbeschränkung. Wenn beide Seiten des Joins Broadcast-Hinweise enthalten, wird die Seite mit der kleineren Größe (basierend auf Statistiken) übertragen. Der Standardwert für die spark.sql.autoBroadcastJoinThreshold Eigenschaft ist 10 MB. Dadurch wird die maximale Größe in Byte für eine Tabelle konfiguriert, die bei der Ausführung eines Joins an alle Worker-Knoten gesendet wird.
Die folgenden Beispiele enthalten die Abfrage, den physischen EXPLAIN Plan und die Zeit, die für die Ausführung der Abfrage benötigt wurde. Die Abfrage benötigt weniger Verarbeitungszeit, wenn Sie den BROADCASTJOIN Hinweis verwenden, um einen Broadcast-Join zu erzwingen, wie im zweiten EXPLAIN Beispielplan gezeigt.
SQL Query : select table1.id,table1.col,table2.id,table2.int_col from table1 join table2 on table1.id = table2.id == Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- SortMergeJoin [id#80L], [id#95L], Inner :- Sort [id#80L ASC NULLS FIRST], false, 0 : +- Exchange hashpartitioning(id#80L, 36), ENSURE_REQUIREMENTS, [id=#725] : +- Filter isnotnull(id#80L) : +- Scan ExistingRDD[id#80L,col#81] +- Sort [id#95L ASC NULLS FIRST], false, 0 +- Exchange hashpartitioning(id#95L, 36), ENSURE_REQUIREMENTS, [id=#726] +- Filter isnotnull(id#95L) +- Scan ExistingRDD[id#95L,int_col#96L] Number of records processed: 799541 Querytime : 21.87715196 seconds
SQL Query : select /*+ BROADCASTJOIN(table1)*/ table1.id,table1.col,table2.id,table2.int_col from table1 join table2 on table1.id = table2.id Physical Plan == AdaptiveSparkPlan isFinalPlan=false\n +- BroadcastHashJoin [id#271L], [id#286L], Inner, BuildLeft, false :- BroadcastExchange HashedRelationBroadcastMode(List(input[0, bigint, false]),false), [id=#955] : +- Filter isnotnull(id#271L) : +- Scan ExistingRDD[id#271L,col#272] +- Filter isnotnull(id#286L) +- Scan ExistingRDD[id#286L,int_col#287L] Number of records processed: 799541 Querytime : 15.35717314 seconds
MERGE
Der Shuffle Sort Merge-Join wird bevorzugt, wenn beide Datensätze groß sind und nicht in den Arbeitsspeicher passen. Wie der Name schon sagt, umfasst diese Verknüpfung die folgenden drei Phasen:
-
Shuffle-Phase — Beide Datensätze in der Join-Abfrage werden gemischt.
-
Sortierphase — Die Datensätze werden auf beiden Seiten nach dem Join-Schlüssel sortiert.
-
Zusammenführungsphase — Beide Seiten der Join-Bedingung werden auf der Grundlage des Join-Schlüssels iteriert.
Die folgende Abbildung zeigt eine DAG-Visualisierung (Directed Acyclic Graph) eines Shuffle Sort Merge-Joins. Beide Tabellen werden in den ersten beiden Phasen gelesen. In der nächsten Phase (Stufe 17) werden sie gemischt, sortiert und am Ende zusammengeführt.
Hinweis: Einige der Stufen in diesem Bild werden als übersprungen angezeigt, da diese Schritte in früheren Phasen abgeschlossen wurden. Diese Daten wurden für die Verwendung in diesen Phasen zwischengespeichert oder dauerhaft gespeichert. |
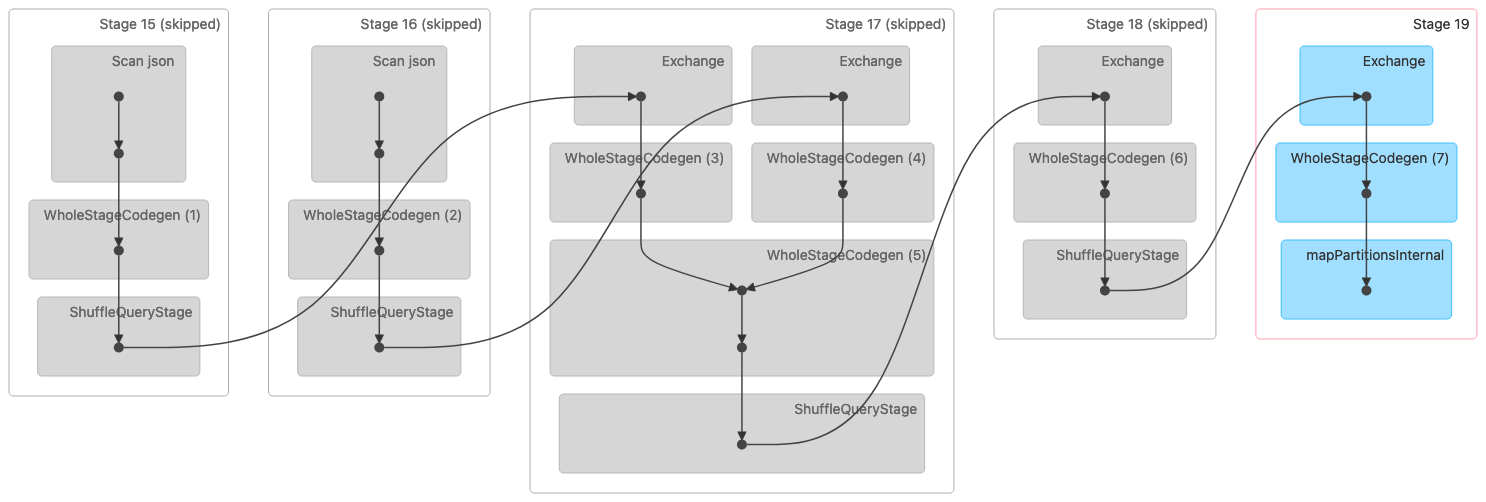
Im Folgenden finden Sie einen physischen Plan, der auf einen Sort Merge-Join hinweist.
== Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- SortMergeJoin [id#320L], [id#335L], Inner :- Sort [id#320L ASC NULLS FIRST], false, 0 : +- Exchange hashpartitioning(id#320L, 36), ENSURE_REQUIREMENTS, [id=#1018] : +- Filter isnotnull(id#320L) : +- Scan ExistingRDD[id#320L,col#321] +- Sort [id#335L ASC NULLS FIRST], false, 0 +- Exchange hashpartitioning(id#335L, 36), ENSURE_REQUIREMENTS, [id=#1019] +- Filter isnotnull(id#335L) +- Scan ExistingRDD[id#335L,int_col#336L]
SHUFFLE_HASH
Der Shuffle Hash Join funktioniert, wie der Name schon sagt, durch Mischen beider Datensätze. Dieselben Schlüssel von beiden Seiten landen in derselben Partition oder Aufgabe. Nachdem die Daten gemischt wurden, wird der kleinste der beiden Datensätze in Buckets gehasht, und dann wird innerhalb der Partition ein Hash-Join durchgeführt. Ein Shuffle-Hash-Join unterscheidet sich von einem Broadcast-Hash-Join, da nicht der gesamte Datensatz übertragen wird. Ein Shuffle-Hash-Join ist in zwei Phasen unterteilt:
-
Shuffle-Phase — Beide Datensätze werden gemischt.
-
Hash-Join-Phase — Die kleinere Seite der Daten wird gehasht, gebündelt und anschließend mit der größeren Seite in allen Partitionen per Hash-Join verknüpft.
Bei Shuffle-Hash-Joins innerhalb der Partitionen ist keine Sortierung erforderlich. Die folgende Abbildung zeigt die Phasen des Shuffle-Hash-Joins. Die Daten werden zunächst gelesen, dann gemischt, und dann wird ein Hash erstellt und für den Join verwendet.
Standardmäßig wählt der Optimierer den Shuffle-Hash-Join, wenn der Broadcast-Hash-Join nicht verwendet werden kann. Basierend auf dem Schwellenwert für den Broadcast-Hash-Join (spark.sql.autoBroadcastJoinThreshold) und der Anzahl der ausgewählten Shuffle-Partitionen (spark.sql.shuffle.partitions) verwendet er den Shuffle-Hash-Join, wenn die einzelne Partition des logischen SQL klein genug ist, um eine lokale Hashtabelle zu erstellen.
SHUFFLE_REPLICATE_NL
Der Shuffle-and-Replicate Nested Loop-Join, auch als Cartesian Product-Join bekannt, funktioniert sehr ähnlich wie ein Broadcast-Hash-Join, außer dass der Datensatz nicht übertragen wird.
In diesem Join-Algorithmus bezieht sich Shuffle nicht auf einen echten Shuffle, da Datensätze mit denselben Schlüsseln nicht an dieselbe Partition gesendet werden. Stattdessen wird die gesamte Partition aus beiden Datensätzen über das Netzwerk kopiert. Wenn die Partitionen aus den Datensätzen verfügbar sind, wird ein Nested Loop-Join ausgeführt. Wenn es in jeder Partition eine X Anzahl von Datensätzen in der ersten und eine Y Anzahl von Datensätzen in der zweiten Datenmenge gibt, wird jeder Datensatz in der zweiten Datenmenge mit jedem Datensatz in der ersten Datenmenge verknüpft. Dies wird in jeder Partition X × Y mehrmals in einer Schleife fortgesetzt.
