Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Optionen wiederherstellen
In den folgenden Abschnitten finden Sie zwei Datenbankwiederherstellungsoptionen für SQL Server auf Amazon Elastic Compute Cloud (Amazon EC2), wenn sich Ihre Backups lokal befinden.
Verwenden von Amazon S3
Dieser Ansatz zur Wiederherstellung von SQL Server-Datenbanken verwendet Amazon Simple Storage Service (Amazon S3) -Befehle für die AWS Command Line Interface (AWS CLI) oder die Amazon S3-API, um die Sicherungsdateien direkt in einen S3-Bucket hochzuladen.
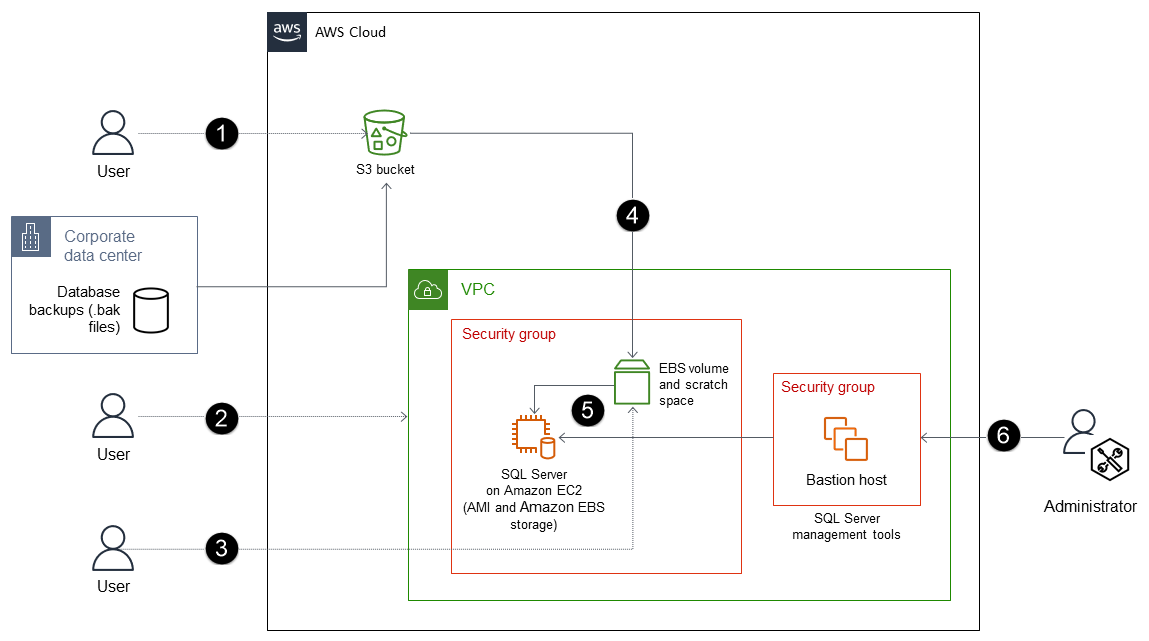
Der Prozess besteht aus den folgenden Schritten:
-
Erstellen Sie einen S3-Bucket (oder verwenden Sie einen vorhandenen Bucket), um die Sicherungsdateien zu speichern, und übertragen Sie Sicherungsdateien (.bak) mithilfe der AWS CLI oder der Amazon S3-API von Ihrer lokalen Datenbank in den S3-Bucket.
-
Stellen Sie SQL Server auf einer EBS-optimierten EC2 Instance mithilfe eines SQL Server Amazon Machine Image (AMI) bereit. Dieses AMI muss EBS-Volumes enthalten, die mit einer Betriebssystempartition, einer DATA-Partition, einer LOG-Partition, tempdb (NVMe) -Speicher und Scratch-Speicherplatz konfiguriert sind.
-
(Optional) Fügen Sie der Instance ein EBS-Volume hinzu, das kein Root-Volume ist. EC2
-
Kopieren Sie die Sicherungsdateien auf das EBS-Volume, das kein Root-Laufwerk ist.
-
Stellen Sie die Sicherungsdateien vom EBS-Volume auf dem SQL Server auf der Instanz wieder her. EC2
-
Verwenden Sie die SQL Server-Verwaltungstools, um Ihre Datenbank zu verwalten.
Nutzung AWS DataSync und Amazon FSx
Dieser Ansatz zur Wiederherstellung der SQL Server-Datenbank verwendet AWS DataSync die Übertragung der Sicherungsdateien an Amazon FSx for Windows File Server.
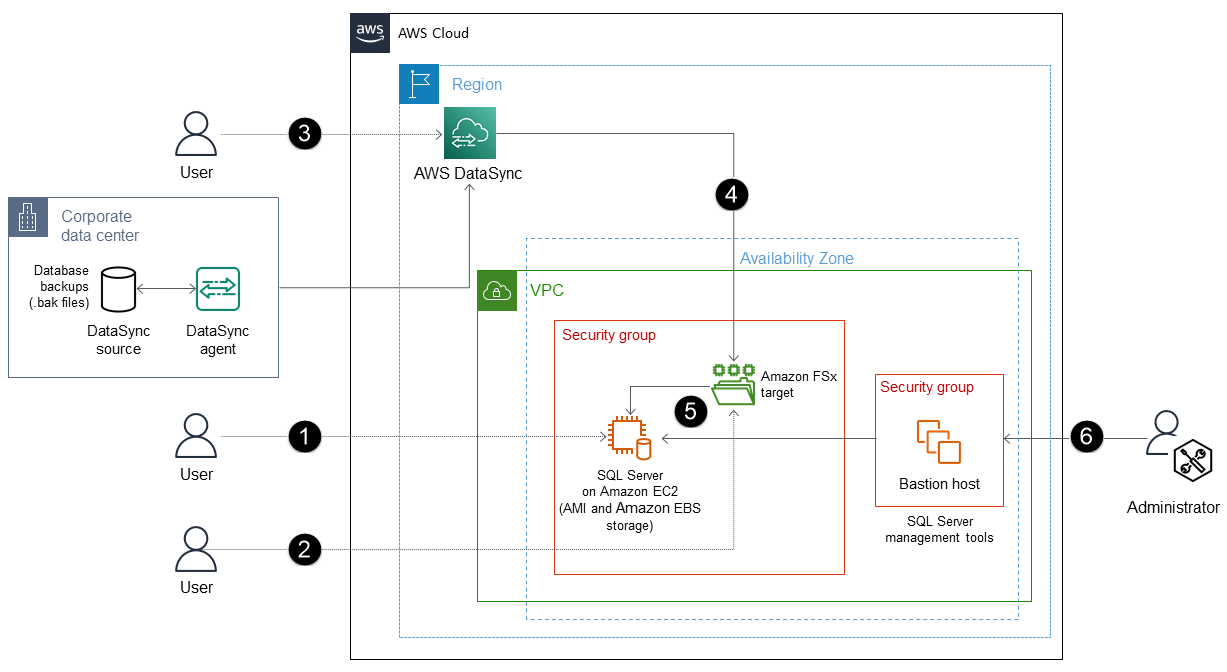
Der Prozess besteht aus den folgenden Schritten:
-
Stellen Sie SQL Server auf einer EBS-optimierten EC2 Instanz mit angehängtem System bereit. Verwenden Sie dazu ein AMI NVMe, das EBS-Volumes enthält, die mit OS, DATA, LOG und tempdb konfiguriert sind. (Sie können beispielsweise die speicheroptimierte
r5d.largeInstanzklasse verwenden.) -
Wird FSx für Windows File Server verwendet, um einen Dateiserver zu erstellen. Dieser kann als temporärer Speicherort zum Herunterladen von SQL Server-Sicherungsdateien (.bak) aus Ihrer lokalen Umgebung verwendet werden.
-
Erstellen Sie einen DataSync Endpunkt und einen Agenten für den FSx Amazon-Dateiserver.
-
DataSync automatisiert die Datensynchronisierung zwischen Ihrem lokalen Speicher und dem FSx Amazon-Dateiserver, ohne dass Amazon S3 erforderlich ist.
-
Stellen Sie die Sicherungsdateien vom FSx Amazon-Dateiserver auf SQL Server auf der EC2 Instance wieder her.
-
Verwenden Sie die SQL Server-Management-Tools, um Ihre Datenbank zu verwalten.
Anmerkung
Amazon EC2 bietet Microsoft SQL Server auf Microsoft Windows Server AMIs
Verwenden von Amazon S3 File Gateway
Sie können Amazon S3 File Gateway
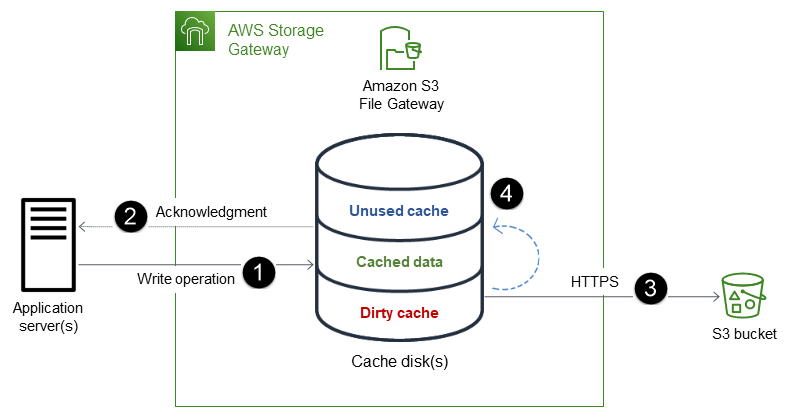
Der Prozess besteht aus den folgenden Schritten:
-
Daten werden auf die lokale Cache-Festplatte des File-Gateways geschrieben.
-
Nachdem die Daten sicher im lokalen Cache gespeichert wurden, bestätigt das File-Gateway den Abschluss des Schreibvorgangs an die Client-Anwendung.
-
Das File-Gateway überträgt Daten asynchron an den S3-Bucket. Es optimiert die Datenübertragung und verwendet HTTPS, um Daten während der Übertragung zu verschlüsseln.
-
Nachdem Daten in den S3-Bucket hochgeladen wurden, verbleiben sie im lokalen Cache des File-Gateways, bis sie gelöscht werden.
