Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Beispielhafte Implementierung einer modernen Gesundheitsdatenstrategie
AWS bietet Referenzarchitekturen, die Organisationen im Gesundheitswesen nutzen können, um Datenplattformen zu verstehen und aufzubauen, die einen agilen Datenansatz unterstützen. Die folgende Referenzarchitektur veranschaulicht eine Data-Mesh-Architektur
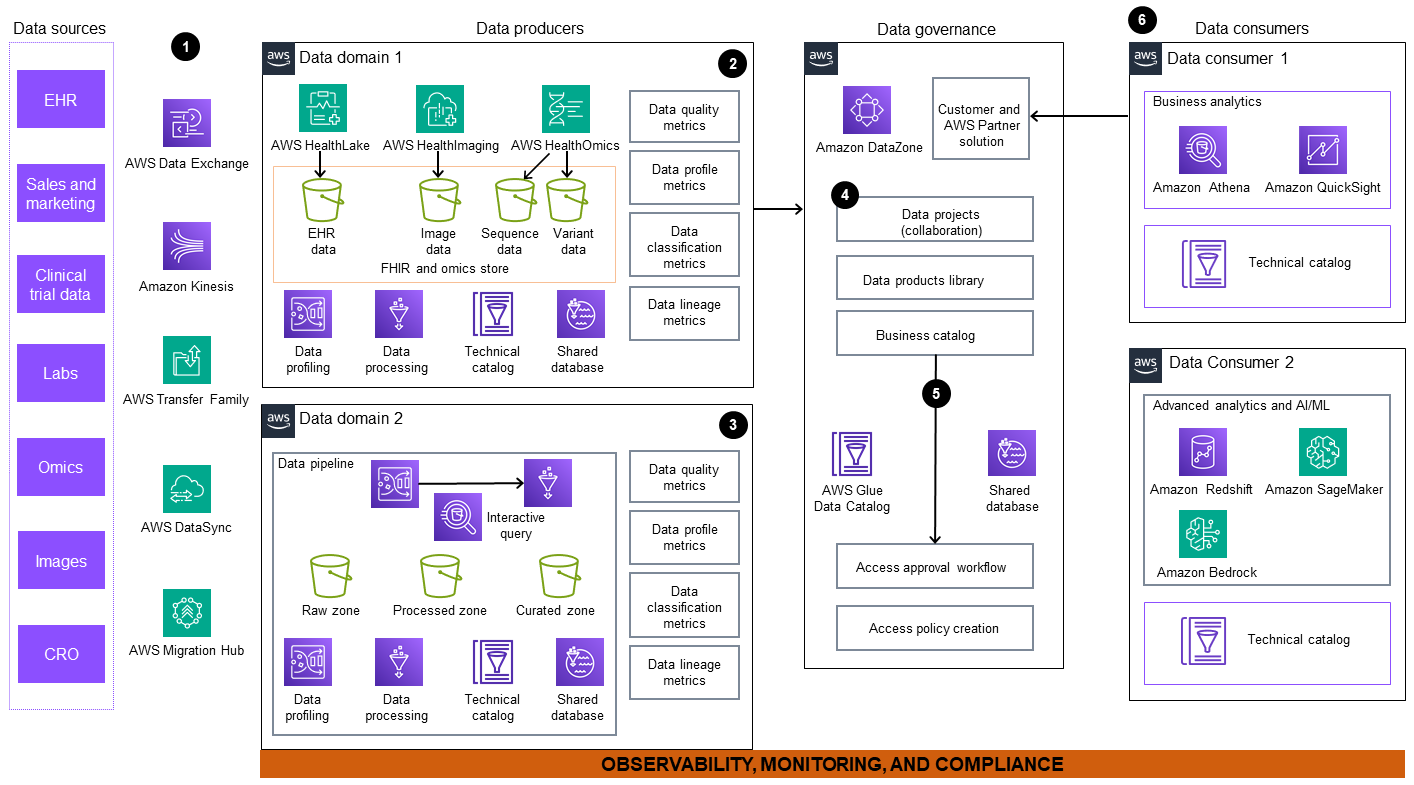
Das Architekturdiagramm umfasst die folgenden Komponenten:
-
Daten werden aus externen und internen Datenquellen aufgenommen. Zu diesen Quellen gehören unter anderem elektronische Patientenakten (EHR), Labore, Sequenzierungseinrichtungen und Bildgebungszentren. AWS bietet eine Reihe von Diensten wie AWS Data Exchange
Amazon Kinesis ,, AWS Transfer Family , AWS DataSyncAWS Migration HubAWS HealthLake , und AWS Glue (ETL). Sie können diese Dienste verwenden, um Ihren internen Datensatz zu migrieren und sowohl interne als auch externe Datensätze zu abonnieren. -
Datendomäne 1 umfasst einen umfassenden Workflow für die Verarbeitung multimodaler patientenorientierter Daten, einschließlich klinischer Daten, Omics- und Bilddaten. Klinische EHR-Daten werden aufgenommen und in einem HealthLake Datenspeicher gespeichert, einem speziell entwickelten verwalteten Dienst für klinische Daten. AWS HealthOmics
, ein speziell für Omics-Daten entwickelter Dienst, kümmert sich um die Speicherung von Sequenzen und Varianten sowie um den Arbeitsablauf. Bilddaten werden aufgenommen und gespeichert in. AWS HealthImaging Diese Daten werden dann in verbrauchsfertige Produkte umgewandelt und auf einem Marktplatz für Unternehmensdaten veröffentlicht, sodass sie allgemein zugänglich und genutzt werden können. -
In Data Domain 2, Amazon Kinesis AWS Glue, und AWS Data Exchange nehmen Rohdaten in eine Datenpipeline auf. Zu den Datenquellen können öffentliche Register, Patientenfernüberwachung und ERP-Programme (Enterprise Resource Planning) gehören. Die Pipeline lädt die Rohdaten in Amazon Simple Storage Service (Amazon S3)
-Buckets. Diese Daten werden bereinigt, kuratiert, transformiert und für die Veröffentlichung als Datenprodukt gespeichert. Amazon Athena bietet eine interaktive Abfrage-Engine, mit der Datenproduzenten Daten mithilfe von SQL transformieren können. AWS Glue DataBrew bietet Funktionen zur visuellen Datentransformation, Normalisierung und Profilerstellung. -
Amazon DataZone
kümmert sich um die Veröffentlichung von Metadaten, kollaborativen Datenprojekten und der Datenproduktbibliothek im zentralen Geschäftskatalog. -
Ein einheitliches Datenanalyseportal ermöglicht die Zusammenarbeit rund um Daten, indem es über eine föderierte Verwaltung einen Überblick über Datenprodukte bietet. Amazon DataZone ermöglicht einen Self-Service-Workflow AWS Glue Data Catalog mit AWS Lake Formation Backed by, sodass Benutzer Daten teilen, suchen, entdecken und eine Nutzungsgenehmigung beantragen können.
-
Datenverbraucher können auf Daten zugreifen, Downstream-Ansichten erstellen und speziell entwickelte Tools wie Amazon Athena, Amazon, Amazon
Redshift QuickSight, Amazon SageMaker AI und Amazon Bedrock verwenden, um Folgendes zu tun: -
Operative Analysen
-
Klinische Informatik
-
Forschung
-
Patienten- und klinisches Engagement
Datenkonsumenten können mithilfe generativer KI auch innovative Anwendungen entwickeln und Datenprodukte im Geschäftskatalog veröffentlichen.
-
Weitere Informationen zur Data-Mesh-Architektur finden Sie unter Was ist ein Data Mesh?
Generative KI
Organisationen im Gesundheitswesen nutzen generative KI für eine Reihe von Anwendungen, von der Automatisierung der Interpretation medizinischer Bilder bis hin zur Generierung von Diagnoseempfehlungen und Behandlungsplänen auf der Grundlage von Bild- und Textdaten. Die Einführung generativer KI beschleunigt die Innovation und steigert die Effizienz im gesamten Versorgungskontinuum. Der neue Fokus auf generative KI hat das Gesundheitswesen gezwungen, seinen Datenfokus auf mehr Formen unstrukturierter Daten auszudehnen, wodurch die Anzahl und Vielfalt der Anwendungsfälle, die KI nutzen kann, zugenommen hat. Im Allgemeinen gibt es vier Muster, aus denen Unternehmen je nach Anwendungsfall wählen können, um generative KI-Lösungen zu implementieren:
-
Prompt Engineering — Beim Prompt Engineering geben Benutzer relevante Daten als Kontext an und leiten so das generative KI-Modell zur Erstellung der gewünschten Inhalte an. Organizations mit einer modernen Strategie für Gesundheitsdaten können sicherstellen, dass die relevanten Daten leicht auffindbar, gemeinsam genutzt und konsumiert werden können.
-
Retrieval Augmented Generation (RAG) — Das RAG-Muster basiert auf schnellem Engineering. Anstatt dass ein Benutzer relevante Daten bereitstellt, fängt ein Programm die Frage oder Eingabe des Benutzers ab. Das Programm durchsucht ein Datenarchiv, um Inhalte abzurufen, die für die Frage oder Eingabe relevant sind. Das Programm speist die gefundenen Daten in das generative KI-Modell ein, um Inhalte zu generieren. Eine moderne Strategie für Gesundheitsdaten ermöglicht die Kuration und Indexierung von Unternehmensdaten. Die Daten können dann durchsucht und als Kontext für Eingabeaufforderungen oder Fragen verwendet werden, was einem großen Sprachmodell (LLM) bei der Generierung von Antworten hilft.
Ihr Unternehmen kann die folgenden beiden Muster verwenden, um die Ergebnisse generativer KI-Modelle auf die Generierung von Inhalten zu konzentrieren, die dem Kontext ihrer Daten entsprechen.
-
Feinabstimmung — Mithilfe dieses Musters kann Ihr Unternehmen noch einen Schritt weiter gehen und generative KI-Modelle anpassen. Dies beinhaltet die Feinabstimmung der Modelle anhand einer kleinen Stichprobe von unternehmensspezifischen Daten. Da der Stichprobenumfang klein ist, bietet dieses Muster ein ausgewogenes Verhältnis zwischen Kosten und Anpassung. Um Verzerrungen bei den Modellausgaben zu vermeiden, sollten Sie einen kleinen Beispieldatensatz verwenden, der so vielfältig und repräsentativ wie möglich für die Datenmuster Ihres Unternehmens ist. Eine moderne Strategie für Gesundheitsdaten unterstützt den effizienten Zugriff auf eine Vielzahl von Daten zur Vorbereitung der Probendatensätze.
-
Erstellen Sie Ihr eigenes Modell — Wenn Ihr Unternehmen Inhalte aus hochspezialisierten, großen Datenmengen generieren muss und die drei vorherigen Muster nicht ausreichen, können Sie Ihre eigenen Modelle erstellen.
Eine moderne Datenstrategie spielt bei generativen KI-Lösungen eine entscheidende Rolle, indem sie sicherstellt, dass die Daten die folgenden Eigenschaften aufweisen:
-
Hochwertige Daten zur Unterstützung der Genauigkeit
-
Daten in Echtzeit oder nahezu in Echtzeit, um sicherzustellen, dass die Modellergebnisse relevant sind
-
Verschiedene Datenmodalitäten aus einer Vielzahl von Datenquellen ermöglichen dem Modell den Zugriff auf angereicherte Datensätze zur Generierung von Inhalten
Das folgende Diagramm zeigt die Implementierung einer modernen Strategie für Gesundheitsdaten, die eine Data-Mesh-Architektur zur Unterstützung generativer KI-Lösungen verwendet.
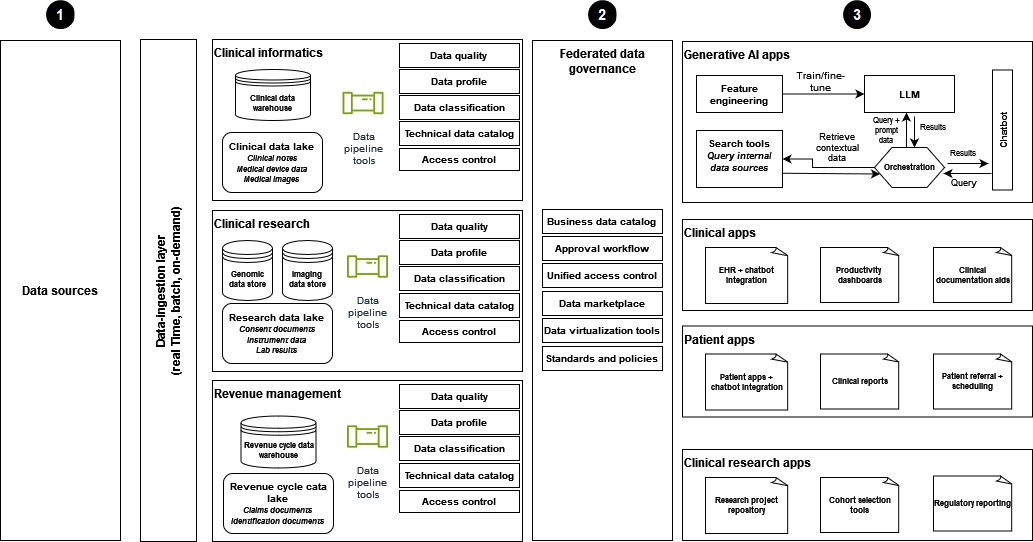
-
Die Daten stammen aus verschiedenen Datenquellen in den Bereichen Klinische Informatik, klinische Forschung und Revenue Management, und die Daten werden der Gesundheitsorganisation zur Verfügung gestellt.
-
Eine föderierte Datenverwaltung trägt dazu bei, eine strenge Zugriffskontrolle für die gemeinsame Nutzung von Daten und einen einheitlichen Zugriff sicherzustellen.
-
Zu den Datenverbrauchern gehören:
-
Generative KI-Anwendungen, insbesondere solche, die Daten zum Trainieren und zur Feinabstimmung LLMs verwenden. Diese Anwendungen nutzen Unternehmensdaten für Q&A-Chatbots, um die betriebliche Effizienz und die Erfahrungen von Patienten und Anbietern zu verbessern.
-
Klinische Anwendungen, die mit Tools wie in die elektronische Patientenakte integrierten Chatbots, Produktivitäts-Dashboards und Dokumentationshilfen ausgestattet sind.
-
Patientenorientierte Anwendungen zur Verbesserung der Patientenerfahrung. Diese Anwendungen bieten Chatbot-Interaktionen, klinische Berichte und effiziente Überweisungs- und Planungsprozesse.
-
Klinische Forschung mit einem Repositorium für Forschungsprojekte und Anwendungen für Kohortenanalysen und regulatorische Berichterstattung.
-
Mit dieser Architektur können sich die Beteiligten in Ihrer Organisation auf die Kuratierung und Verwaltung der Daten konzentrieren, die sie aus anderen Quellen sammeln, und gleichzeitig ihre eigenen Daten dem Rest der Organisation zugänglich machen. Sie können Tools verwenden, die auf der föderierten Datenverwaltungsebene verfügbar sind, um Metadaten zu definieren, Workflows für die Zugriffsgenehmigung zu verwalten und Richtlinien zu definieren und durchzusetzen. Darüber hinaus bietet die föderierte Data-Governance-Ebene eine zentrale Zugriffskontrolle. Dadurch wird eine Umgebung geschaffen, in der eine Vielzahl von Datenquellen kuratiert und hochwertige Datenbestände mit einer bestimmten Häufigkeit aktualisiert werden können, um die Relevanz aufrechtzuerhalten. AWS bietet eine umfassende Palette von Funktionen, um Ihren generativen KI-Anforderungen gerecht zu werden. Amazon Bedrock
