Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Wichtige Themen in Apache Spark
In diesem Abschnitt werden die grundlegenden Konzepte und Schlüsselthemen von Apache Spark für die Optimierung AWS Glue der Apache Spark-Leistung erläutert. Es ist wichtig, dass Sie sich mit diesen Konzepten und Themen vertraut machen, bevor Sie über Optimierungsstrategien aus der Praxis sprechen.
Architektur
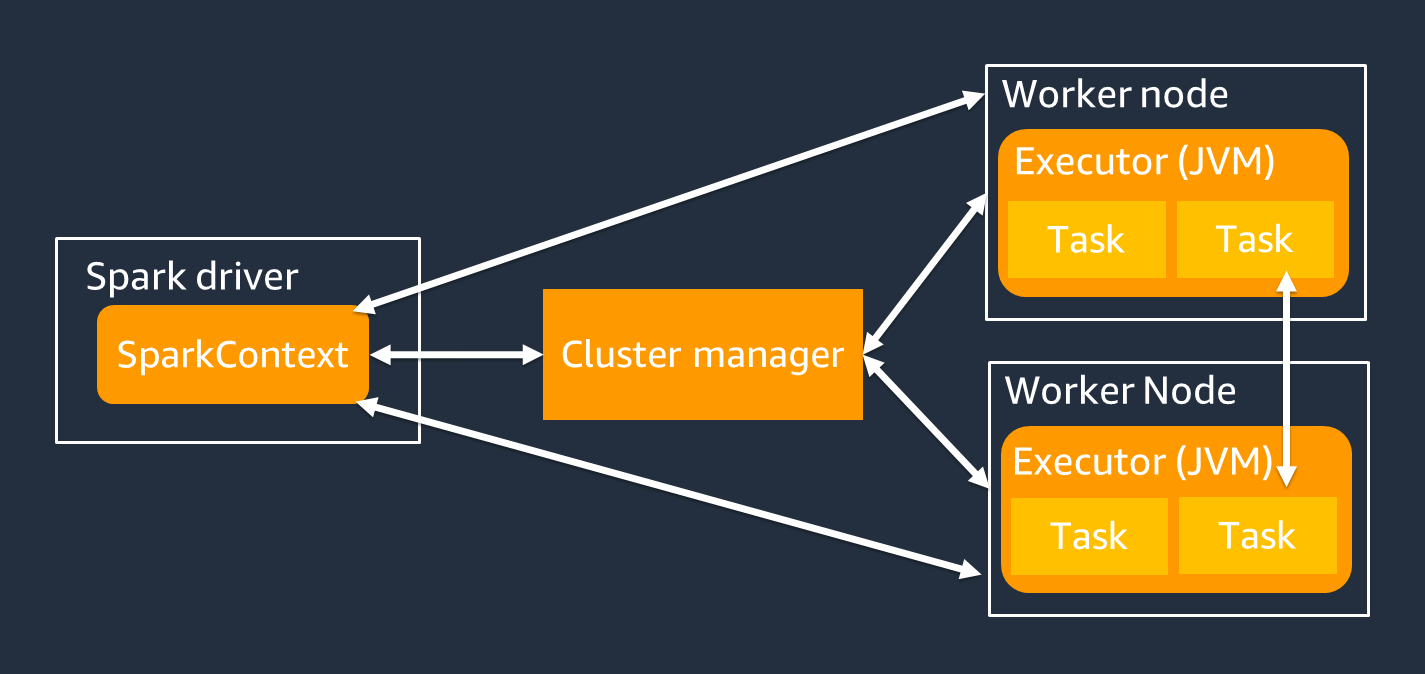
Der Spark-Treiber ist hauptsächlich dafür verantwortlich, Ihre Spark-Anwendung in Aufgaben aufzuteilen, die von einzelnen Workern ausgeführt werden können. Der Spark-Treiber hat die folgenden Aufgaben:
-
Wird
main()in Ihrem Code ausgeführt -
Generierung von Ausführungsplänen
-
Bereitstellung von Spark-Executoren in Verbindung mit dem Clustermanager, der die Ressourcen auf dem Cluster verwaltet
-
Planung von Aufgaben und Anforderung von Aufgaben für Spark-Executoren
-
Verwaltung des Aufgabenfortschritts und der Wiederherstellung
Sie verwenden ein SparkContext Objekt, um mit dem Spark-Treiber für Ihre Jobausführung zu interagieren.
Ein Spark-Executor ist ein Worker, der Daten speichert und Aufgaben ausführt, die vom Spark-Treiber übergeben werden. Die Anzahl der Spark-Executoren steigt und fällt mit der Größe Ihres Clusters.
Anmerkung
Ein Spark-Executor hat mehrere Steckplätze, sodass mehrere Aufgaben parallel verarbeitet werden können. Spark unterstützt standardmäßig eine Aufgabe für jeden virtuellen CPU-Kern (vCPU). Wenn ein Executor beispielsweise über vier CPU-Kerne verfügt, kann er vier Aufgaben gleichzeitig ausführen.
Belastbarer verteilter Datensatz
Spark erledigt die komplexe Aufgabe, große Datenmengen über Spark-Executoren hinweg zu speichern und zu verfolgen. Wenn Sie Code für Spark-Jobs schreiben, müssen Sie sich keine Gedanken über die Speicherdetails machen. Spark bietet die Resilient Distributed Dataset (RDD) -Abstraktion, bei der es sich um eine Sammlung von Elementen handelt, die parallel bearbeitet und auf die Spark-Executoren des Clusters aufgeteilt werden können.
Die folgende Abbildung zeigt den Unterschied darin, wie Daten im Speicher gespeichert werden, wenn ein Python-Skript in seiner typischen Umgebung ausgeführt wird und wenn es im Spark-Framework (PySpark) ausgeführt wird.
![Python-Wert [1,2,3 N], Apache Spark rdd = sc.parallelize [1,2,3 N].](images/store-data-memory.png)
-
Python — Beim Schreiben
val = [1,2,3...N]in ein Python-Skript bleiben die Daten im Speicher des einzelnen Computers, auf dem der Code ausgeführt wird. -
PySpark— Spark bietet die RDD-Datenstruktur zum Laden und Verarbeiten von Daten, die über den Speicher verteilt sind, auf mehreren Spark-Executoren. Sie können ein RDD mit Code wie dem generieren
rdd = sc.parallelize[1,2,3...N], und Spark kann Daten automatisch auf mehrere Spark-Executoren verteilen und im Speicher speichern.In vielen AWS Glue Jobs verwenden RDDs Sie Through und Spark. AWS Glue DynamicFramesDataFrames Dabei handelt es sich um Abstraktionen, mit denen Sie das Schema der Daten in einer RDD definieren und mit diesen zusätzlichen Informationen Aufgaben auf höherer Ebene ausführen können. Da sie RDDs intern verwendet werden, werden Daten im folgenden Code transparent verteilt und auf mehrere Knoten geladen:
-
DynamicFrame
dyf= glueContext.create_dynamic_frame.from_options( 's3', {"paths": [ "s3://<YourBucket>/<Prefix>/"]}, format="parquet", transformation_ctx="dyf" ) -
DataFrame
df = spark.read.format("parquet") .load("s3://<YourBucket>/<Prefix>")
-
Ein RDD hat die folgenden Funktionen:
-
RDDs bestehen aus Daten, die in mehrere Teile unterteilt sind, die als Partitionen bezeichnet werden. Jeder Spark-Executor speichert eine oder mehrere Partitionen im Speicher, und die Daten werden auf mehrere Executoren verteilt.
-
RDDs sind unveränderlich, was bedeutet, dass sie nach ihrer Erstellung nicht mehr geändert werden können. Um a zu ändern DataFrame, können Sie Transformationen verwenden, die im folgenden Abschnitt definiert werden.
-
RDDs replizieren Sie Daten auf allen verfügbaren Knoten, sodass sie nach Knotenausfällen automatisch wiederhergestellt werden können.
Faule Bewertung
RDDs unterstützt zwei Arten von Operationen: Transformationen, bei denen aus einem vorhandenen Datensatz ein neuer Datensatz erstellt wird, und Aktionen, bei denen ein Wert an das Treiberprogramm zurückgegeben wird, nachdem eine Berechnung für den Datensatz ausgeführt wurde.
-
Transformationen — Da sie unveränderlich RDDs sind, können Sie sie nur mithilfe einer Transformation ändern.
mapIst beispielsweise eine Transformation, bei der jedes Datensatzelement eine Funktion durchläuft und eine neue RDD zurückgibt, die die Ergebnisse darstellt. Beachten Sie, dass diemapMethode keine Ausgabe zurückgibt. Spark speichert die abstrakte Transformation für die future, anstatt Sie mit dem Ergebnis interagieren zu lassen. Spark reagiert erst auf Transformationen, wenn Sie eine Aktion aufrufen. -
Aktionen — Mithilfe von Transformationen erstellen Sie Ihren logischen Transformationsplan. Um die Berechnung zu starten, führen Sie eine Aktion wie
write,countshow, oder aus.collectAlle Transformationen in Spark sind faul, da sie ihre Ergebnisse nicht sofort berechnen. Stattdessen erinnert sich Spark an eine Reihe von Transformationen, die auf einige Basisdatensätze angewendet wurden, z. B. auf Amazon Simple Storage Service (Amazon S3) -Objekte. Die Transformationen werden nur berechnet, wenn für eine Aktion ein Ergebnis an den Treiber zurückgegeben werden muss. Dieses Design ermöglicht es Spark, effizienter zu arbeiten. Stellen Sie sich beispielsweise die Situation vor, in der ein durch die
mapTransformation erstellter Datensatz nur für eine Transformation verwendet wird, die die Anzahl der Zeilen erheblich reduziert, wiereducez. Sie können dann den kleineren Datensatz, der beide Transformationen durchlaufen hat, an den Treiber übergeben, anstatt den größeren zugewiesenen Datensatz zu übergeben.
Terminologie der Spark-Anwendungen
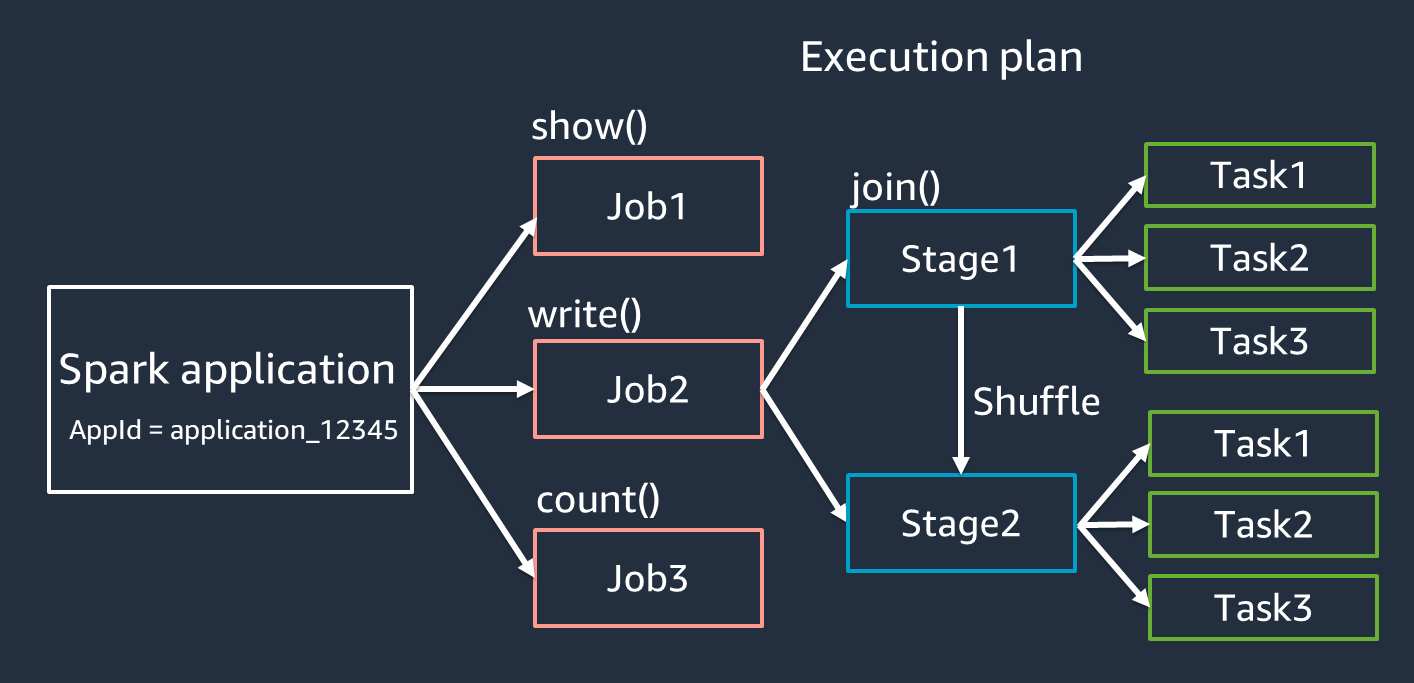
In diesem Abschnitt wird die Terminologie von Spark-Anwendungen behandelt. Der Spark-Treiber erstellt einen Ausführungsplan und steuert das Verhalten von Anwendungen in verschiedenen Abstraktionen. Die folgenden Begriffe sind wichtig für die Entwicklung, das Debugging und die Leistungsoptimierung mit der Spark-Benutzeroberfläche.
-
Anwendung — Basiert auf einer Spark-Sitzung (Spark-Kontext). Identifiziert durch eine eindeutige ID wie
<application_XXX>. -
Jobs — Basierend auf den Aktionen, die für ein RDD erstellt wurden. Ein Job besteht aus einer oder mehreren Phasen.
-
Stufen — Basierend auf den für ein RDD erstellten Shuffles. Eine Phase besteht aus einer oder mehreren Aufgaben. Shuffle ist der Mechanismus von Spark zur Umverteilung von Daten, sodass sie auf RDD-Partitionen unterschiedlich gruppiert werden. Bestimmte Transformationen, wie z. B.
join(), erfordern einen Shuffle. Die Zufallswiedergabe wird in der Übung zur Optimierung der Zufallswiedergabe optimieren ausführlicher behandelt. -
Aufgaben — Eine Aufgabe ist die von Spark geplante Mindestverarbeitungseinheit. Aufgaben werden für jede RDD-Partition erstellt, und die Anzahl der Aufgaben entspricht der maximalen Anzahl gleichzeitiger Ausführungen in der Phase.
Anmerkung
Aufgaben sind das Wichtigste, was bei der Optimierung der Parallelität berücksichtigt werden muss. Die Anzahl der Aufgaben skaliert mit der Anzahl der RDD
Parallelism
Spark parallelisiert Aufgaben zum Laden und Transformieren von Daten.
Stellen Sie sich ein Beispiel vor, in dem Sie eine verteilte Verarbeitung von Zugriffsprotokolldateien (benanntaccesslog1 ... accesslogN) auf Amazon S3 durchführen. Das folgende Diagramm zeigt den Ablauf der verteilten Verarbeitung.

-
Der Spark-Treiber erstellt einen Ausführungsplan für die verteilte Verarbeitung auf viele Spark-Executoren.
-
Der Spark-Treiber weist jedem Executor auf der Grundlage des Ausführungsplans Aufgaben zu. Standardmäßig erstellt der Spark-Treiber RDD-Partitionen (jede entspricht einer Spark-Aufgabe) für jedes S3-Objekt ().
Part1 ... NAnschließend weist der Spark-Treiber jedem Executor Aufgaben zu. -
Jede Spark-Aufgabe lädt das zugewiesene S3-Objekt herunter und speichert es im Speicher der RDD-Partition. Auf diese Weise laden mehrere Spark-Executoren ihre zugewiesene Aufgabe herunter und verarbeiten sie parallel.
Weitere Informationen zur anfänglichen Anzahl von Partitionen und zur Optimierung finden Sie im Abschnitt Aufgaben parallelisieren.
Catalyst-Optimierer
Intern verwendet Spark eine Engine namens Catalyst Optimizer
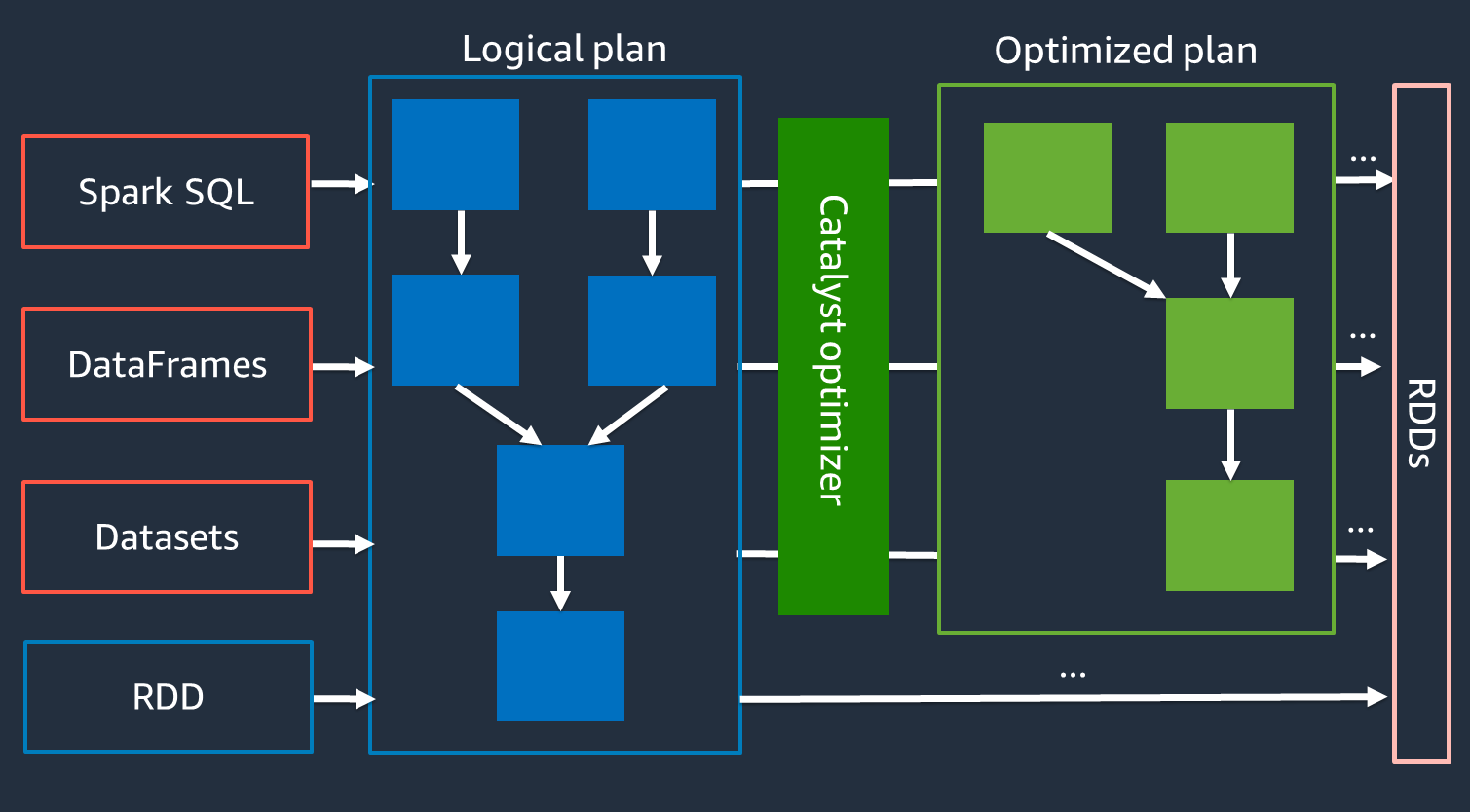
Da der Catalyst-Optimierer nicht direkt mit der RDD-API zusammenarbeitet, APIs sind die High-Level-RDD-APIs im Allgemeinen schneller als die Low-Level-RDD-API. Bei komplexen Verknüpfungen kann der Catalyst-Optimierer die Leistung erheblich verbessern, indem er den Job-Ausführungsplan optimiert. Sie können den optimierten Plan Ihres Spark-Jobs auf der Registerkarte SQL der Spark-Benutzeroberfläche sehen.
Adaptive Abfrageausführung
Der Catalyst-Optimierer führt die Laufzeitoptimierung mithilfe eines Prozesses namens Adaptive Query Execution durch. Adaptive Query Execution verwendet Laufzeitstatistiken, um den Ausführungsplan der Abfragen erneut zu optimieren, während Ihr Job ausgeführt wird. Adaptive Query Execution bietet mehrere Lösungen für Performance-Probleme, darunter das Zusammenführen von Partitionen nach dem Zufälligen Zusammenführen, das Konvertieren von Sort-Merge-Join in Broadcast-Join und die Optimierung von Skew-Joins, wie in den folgenden Abschnitten beschrieben.
Adaptive Query Execution ist in AWS Glue 3.0 und höher verfügbar und in AWS Glue 4.0 (Spark 3.3.0) und höher standardmäßig aktiviert. Adaptive Query Execution kann spark.conf.set("spark.sql.adaptive.enabled",
"true") in Ihrem Code ein- und ausgeschaltet werden.
Zusammenführung von Partitionen nach dem Shuffle-Modus
Diese Funktion reduziert die Anzahl der RDD-Partitionen (Zusammenführung) nach jedem Shuffle auf der Grundlage der Ausgabestatistiken. map Es vereinfacht die Einstellung der Shuffle-Partitionsnummer bei der Ausführung von Abfragen. Sie müssen keine Shuffle-Partitionsnummer festlegen, die zu Ihrem Datensatz passt. Spark kann zur Laufzeit die richtige Shuffle-Partitionsnummer auswählen, wenn Sie eine ausreichend große anfängliche Anzahl von Shuffle-Partitionen haben.
Das Zusammenführen von Post-Shuffle-Partitionen ist aktiviert, wenn sowohl als auch spark.sql.adaptive.enabled auf true gesetzt sind. spark.sql.adaptive.coalescePartitions.enabled Weitere Informationen finden Sie in der Apache Spark-Dokumentation.
Sort-Merge-Join in Broadcast-Join konvertieren
Diese Funktion erkennt, wenn Sie zwei Datensätze mit wesentlich unterschiedlicher Größe verbinden, und verwendet auf der Grundlage dieser Informationen einen effizienteren Verbindungsalgorithmus. Weitere Informationen finden Sie in der Apache Spark-Dokumentation
Optimierung von Skew-Joins
Datenverzerrung ist einer der häufigsten Engpässe bei Spark-Jobs. Es beschreibt eine Situation, in der Daten auf bestimmte RDD-Partitionen (und folglich auf bestimmte Aufgaben) verschoben werden, was die Gesamtverarbeitungszeit der Anwendung verzögert. Dadurch kann die Leistung von Verbindungsvorgängen häufig beeinträchtigt werden. Mit der Funktion zur Optimierung von Schrägverknüpfungen werden Verzerrungen bei Sort-Merge-Verknüpfungen dynamisch behandelt, indem schiefe Aufgaben in etwa gleich große Aufgaben aufgeteilt (und bei Bedarf repliziert) werden.
Diese Funktion ist aktiviert, wenn sie auf „true“ gesetzt ist. spark.sql.adaptive.skewJoin.enabled Weitere Informationen finden Sie in der Apache Spark-Dokumentation
