Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Architektur für ein skalierbares Web-Crawling-System auf AWS
Das folgende Architekturdiagramm zeigt ein Webcrawler-System, das darauf ausgelegt ist, Umwelt-, Sozial- und Unternehmensführungsdaten (ESG) auf ethische Weise von Websites zu extrahieren. Sie verwenden ein Pythonbasierter Crawler, der für die AWS Infrastruktur optimiert ist. Sie AWS Batch orchestrieren die groß angelegten Crawling-Jobs und verwenden Amazon Simple Storage Service (Amazon S3) für die Speicherung. Downstream-Anwendungen können die Daten aus dem Amazon S3 S3-Bucket aufnehmen und speichern.
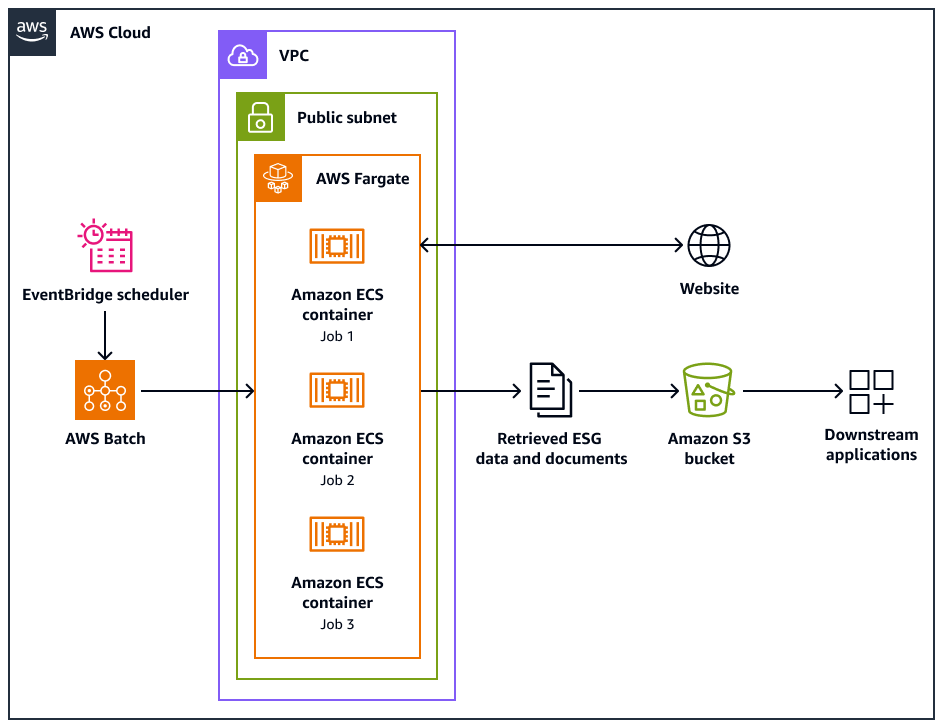
Das Diagramm zeigt den folgenden Workflow:
-
Amazon EventBridge Scheduler initiiert den Crawling-Prozess in einem von Ihnen geplanten Intervall.
-
AWS Batch verwaltet die Ausführung der Webcrawler-Jobs. Die AWS Batch Job-Warteschlange enthält und orchestriert die ausstehenden Crawling-Jobs.
-
Die Web-Crawling-Jobs werden in Amazon Elastic Container Service (Amazon ECS) -Containern auf AWS Fargate ausgeführt. Die Jobs werden in einem öffentlichen Subnetz einer Virtual Private Cloud (VPC) ausgeführt.
-
Der Webcrawler durchsucht die Zielwebsite und ruft ESG-Daten und Dokumente wie PDF-, CSV- oder andere Dokumentdateien ab.
-
Der Webcrawler speichert die abgerufenen Daten und Rohdateien in einem Amazon S3 S3-Bucket.
-
Andere Systeme oder Anwendungen erfassen oder verarbeiten die gespeicherten Daten und Dateien im Amazon S3 S3-Bucket.
Design und Betrieb von Webcrawlern
Einige Websites wurden speziell für die Ausführung auf Desktops oder Mobilgeräten entwickelt. Der Webcrawler ist so konzipiert, dass er die Verwendung eines Desktop-Benutzeragenten oder eines mobilen Benutzeragenten unterstützt. Diese Agenten helfen Ihnen dabei, erfolgreich Anfragen an die Zielwebsite zu stellen.
Nachdem der Webcrawler initialisiert wurde, führt er die folgenden Operationen aus:
-
Der Webcrawler ruft die Methode auf.
setup()Diese Methode ruft die Datei robots.txt ab und analysiert sie.Anmerkung
Sie können den Webcrawler auch so konfigurieren, dass er die Sitemap abruft und analysiert.
-
Der Webcrawler verarbeitet die Datei robots.txt. Wenn in der Datei robots.txt eine Crawlverzögerung angegeben ist, extrahiert der Webcrawler die Crawlverzögerung für den Desktop-Benutzeragenten. Wenn in der Datei robots.txt keine Crawlverzögerung angegeben ist, verwendet der Webcrawler eine zufällige Verzögerung.
-
Der Webcrawler ruft die
crawl()Methode auf, die den Crawling-Prozess initiiert. Wenn URLs sich keine in der Warteschlange befinden, wird die Start-URL hinzugefügt.Anmerkung
Der Crawler fährt fort, bis er die maximale Anzahl an Seiten erreicht hat oder die Crawling-Zeit URLs knapp wird.
-
Der Crawler verarbeitet die. URLs Für jede URL in der Warteschlange prüft der Crawler, ob die URL bereits gecrawlt wurde.
-
Wenn eine URL nicht gecrawlt wurde, ruft der Crawler die Methode wie folgt auf
crawl_url():-
Der Crawler überprüft die Datei robots.txt, um festzustellen, ob er den Desktop-Benutzeragenten zum Crawlen der URL verwenden kann.
-
Falls zulässig, versucht der Crawler, die URL mithilfe des Desktop-Benutzeragenten zu crawlen.
-
Wenn dies nicht erlaubt ist oder wenn der Desktop-Benutzeragent das Crawlen fehlschlägt, überprüft der Crawler die Datei robots.txt, um festzustellen, ob er den mobilen Benutzeragenten zum Crawlen der URL verwenden kann.
-
Falls zulässig, versucht der Crawler, die URL mithilfe des Mobile User Agents zu crawlen.
-
-
Der Crawler ruft die
attempt_crawl()Methode auf, die den Inhalt abruft und verarbeitet. Der Crawler sendet eine GET-Anfrage mit entsprechenden Headern an die URL. Wenn die Anfrage fehlschlägt, verwendet der Crawler die Wiederholungslogik. -
Wenn die Datei im HTML-Format vorliegt, ruft der Crawler die Methode auf.
extract_esg_data()Sie verwendet Beautiful Soupum den HTML-Inhalt zu analysieren. Es extrahiert Umwelt-, Sozial- und Unternehmensführungsdaten (ESG) mithilfe von Stichwort-Matching. Wenn es sich bei der Datei um eine PDF-Datei handelt, ruft der Crawler die Methode auf
save_pdf(). Der Crawler lädt die PDF-Datei herunter und speichert sie im Amazon S3 S3-Bucket. -
Der Crawler ruft die Methode auf
extract_news_links(). Dadurch werden Links zu Nachrichtenartikeln, Pressemitteilungen und Blogbeiträgen gefunden und gespeichert. -
Der Crawler ruft die
extract_pdf_links()Methode auf. Dadurch werden Links zu PDF-Dokumenten identifiziert und gespeichert. -
Der Crawler ruft die
is_relevant_to_sustainable_finance()Methode auf. Dabei wird anhand vordefinierter Stichwörter geprüft, ob sich die Nachrichten oder Artikel auf nachhaltiges Finanzwesen beziehen. -
Nach jedem Crawlversuch implementiert der Crawler mithilfe der
delay()Methode eine Verzögerung. Wenn in der Datei robots.txt eine Verzögerung angegeben wurde, wird dieser Wert verwendet. Andernfalls wird eine zufällige Verzögerung zwischen 1 und 3 Sekunden verwendet. -
Der Crawler ruft die
save_esg_data()Methode auf, um die ESG-Daten in einer CSV-Datei zu speichern. Die CSV-Datei wird im Amazon S3 S3-Bucket gespeichert. -
Der Crawler ruft die
save_news_links()Methode auf, um die News-Links einschließlich Relevanzinformationen in einer CSV-Datei zu speichern. Die CSV-Datei wird im Amazon S3 S3-Bucket gespeichert. -
Der Crawler ruft die
save_pdf_links()Methode zum Speichern der PDF-Links in einer CSV-Datei auf. Die CSV-Datei wird im Amazon S3 S3-Bucket gespeichert.
Batching und Datenverarbeitung
Der Crawling-Prozess wird strukturiert organisiert und durchgeführt. AWS Batch weist die Jobs für jedes Unternehmen so zu, dass sie parallel und stapelweise ausgeführt werden. Jeder Batch konzentriert sich auf die Domain und die Subdomänen eines einzelnen Unternehmens, so wie Sie sie in Ihrem Datensatz identifiziert haben. Jobs im selben Batch werden jedoch sequenziell ausgeführt, sodass die Website nicht mit zu vielen Anfragen überflutet wird. Dies hilft der Anwendung, den Crawling-Workload effizienter zu verwalten und sicherzustellen, dass alle relevanten Daten für jedes Unternehmen erfasst werden.
Durch die Organisation des Webcrawlings in unternehmensspezifische Batches werden die gesammelten Daten containerisiert. Dadurch wird verhindert, dass die Daten eines Unternehmens mit Daten anderer Unternehmen vermischt werden.
Durch Batching kann die Anwendung Daten effizient aus dem Internet sammeln und gleichzeitig eine klare Struktur und Trennung der Informationen auf der Grundlage der Zielunternehmen und ihrer jeweiligen Webdomänen beibehalten. Dieser Ansatz trägt dazu bei, die Integrität und Nutzbarkeit der gesammelten Daten zu gewährleisten, da sie übersichtlich organisiert und den entsprechenden Unternehmen und Domänen zugeordnet sind.
