Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
rank
Die Funktion rank berechnet den Rang eines Messwertes oder einer Dimension im Vergleich zu den angegebenen Partitionen. Es zählt jedes Element, auch Duplikate, einmal und vergibt einen Rang "mit Leerstellen", um doppelte Werte auszugleichen.
Syntax
Die Klammern sind erforderlich. Welche Argumente optional sind, erfahren Sie in den folgenden Beschreibungen.
rank ([ sort_order_field ASC_or_DESC, ... ],[ partition_field, ... ])
Argumente
- Sortierreihenfolge-Feld
-
Einer oder mehrere aggregierte Messwerte und Dimensionen, nach denen Sie die Daten sortieren möchten, getrennt durch Kommas. Sie können aufsteigend (
ASC) oder absteigend (DESC) sortieren.Jedes Feld in der Liste ist in {} eingeschlossen (geschweifte Klammern), wenn es mehr als ein Wort umfasst. Die gesamte Liste ist in [ ] (eckige Klammern) eingeschlossen.
- partition field
-
(Optional) Eine oder mehrere Dimensionen, nach denen Sie die Daten partitionieren möchten, getrennt durch Kommas.
Jedes Feld in der Liste ist in {} eingeschlossen (geschweifte Klammern), wenn es mehr als ein Wort umfasst. Die gesamte Liste ist in [ ] (eckige Klammern) eingeschlossen.
- calculation level (Berechnungsebene)
-
(Optional) Gibt die zu verwendende Berechnungsebene an:
-
PRE_FILTER– Vorfilterberechnungen werden vor den Datensatzfiltern berechnet. -
PRE_AGG– Voraggregatberechnungen werden berechnet, bevor die Aggregationen und Top- und Bottom-N-Filter auf die Visuals angewendet werden. -
POST_AGG_FILTER– (Standard) Tabellenberechnungen werden berechnet, wenn die Visuals angezeigt werden.
Dieser Wert wird standardmäßig auf
POST_AGG_FILTEReingestellt, wenn er leer ist. Weitere Informationen finden Sie unter Verwenden von ebenenspezifischen Berechnungen in Amazon QuickSight. -
Beispiel
Das folgende Beispiel ordnet max(Sales), basierend auf einer absteigenden Sortierung, nach State und City innerhalb des State von WA. Alle Städte mit demselben max(Sales) erhalten den gleichen Rang, aber der nächste Rang enthält die Anzahl aller bereits vorhandenen Ränge. Wenn sich beispielsweise drei Städte die gleiche Rangfolge teilen, wird die vierte Stadt auf Rang 4 eingestuft.
rank ( [max(Sales) DESC], [State, City] )
Das folgende Beispiel ordnet max(Sales), basierend auf einer aufsteigenden Sortierung nach State. Alle Staaten mit demselben max(Sales) erhalten den gleichen Rang, aber der nächste Rang enthält die Anzahl aller bereits vorhandenen Ränge. Wenn sich beispielsweise drei Staaten die gleiche Rangfolge teilen, wird der vierte Staat auf Rang 4 eingestuft.
rank ( [max(Sales) ASC], [State] )
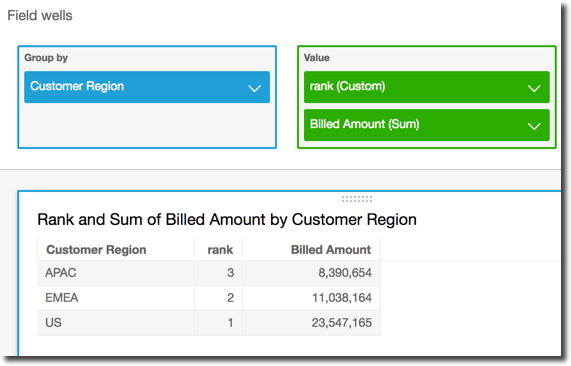
Das folgende Beispiel ordnet Customer Region nach der Summe Billed
Amount. Die Felder in der Tabellenberechnung befinden sich in den Feldbereichen der Visualisierung.
rank( [sum({Billed Amount}) DESC] )
Der folgende Screenshot zeigt die Ergebnisse des Beispiels zusammen mit der Summe Billed Amount, sodass Sie sehen können, wie jede Region eingeordnet ist.