Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwenden Sie Sicherheit auf Zeilenebene mit benutzerbasierten Regeln, um den Zugriff auf einen Datensatz einzuschränken
| Gilt für: Enterprise Edition |
In der Enterprise Edition von Amazon können Sie den Zugriff auf einen Datensatz einschränken QuickSight, indem Sie die Sicherheit auf Zeilenebene (RLS) für ihn konfigurieren. Sie können diese Konfiguration vor oder nach dem Freigeben des Datasets vornehmen. Wenn Sie einen Datensatz mit RLS für Datensatzbesitzer teilen, können diese trotzdem alle Daten sehen. Wenn Sie ihn mit Lesern teilen, können diese jedoch nur die Daten sehen, die durch die Regeln für den Berechtigungsdatensatz eingeschränkt sind. Durch Hinzufügen der Sicherheit auf Zeilenebene können Sie deren Zugriff genauer steuern.
Anmerkung
Bei der Anwendung von SPICE-Datensätzen auf die Sicherheit auf Zeilenebene kann jedes Feld im Datensatz bis zu 2.047 Unicode-Zeichen enthalten. Felder, die mehr als dieses Kontingent enthalten, werden bei der Aufnahme gekürzt. Weitere Informationen zu SPICE-Datenkontingenten finden Sie unter SPICE-Kontingente für importierte Daten.
Erstellen Sie dazu eine Abfrage oder Datei mit der Spalte UserName oder GroupName (oder mit beiden Spalten). Oder Sie können dazu eine Abfrage oder Datei mit der Spalte UserARN oder GroupARN (oder mit beiden Spalten) erstellen. Dies entspricht weitgehend dem Hinzufügen einer Regel zu diesem Benutzer oder dieser Gruppe. Anschließend können Sie der Abfrage oder der Datei eine Spalte für jedes Feld hinzufügen, für das Sie den Zugriff erteilen oder verhindern wollen. Für jeden Benutzer- oder Gruppennamen, den Sie hinzufügen, fügen Sie die Werte für jedes Feld hinzu. Sie können NULL (kein Wert) verwenden, was "alle Werte" bedeutet. Beispiele für Dataset-Regeln finden Sie unter Erstellen von Dataset-Regeln für die Sicherheit auf Zeilenebene.
Um die Dataset-Regeln anzuwenden, fügen Sie diese dem Dataset als Berechtigungsdaten hinzu. Beachten Sie folgende Punkte:
-
Das Datenset mit den Berechtigungen darf keine Duplikatwerte enthalten. Duplikate werden ignoriert, wenn evaluiert wird, wie die Regeln anzuwenden sind.
-
Jeder angegebene Benutzer oder jede angegebene Gruppen nur die Zeilen, die mit den Feldwerten in den Datenset-Regeln übereinstimmen.
-
Wenn Sie einem Benutzer oder einer Gruppe eine Regel hinzufügen und alle anderen Spalten ohne Wert (NULL) beibehalten, gewähren Sie Zugriff auf alle Daten.
-
Wenn Sie keine Regel für einen Benutzer oder eine Gruppe hinzufügen, sieht dieser Benutzer oder diese Gruppe keine Daten.
-
Der vollständige Satz von Regeldatensätzen, die pro Benutzer angewendet werden, darf 999 nicht überschreiten. Diese Beschränkung gilt für die Gesamtzahl der Regeln, die einem Benutzernamen direkt zugewiesen sind, plus alle Regeln, die dem Benutzer über Gruppennamen zugewiesen werden.
-
Wenn ein Feld ein Komma () enthält, QuickSight behandelt Amazon jedes Wort, das durch ein Komma voneinander getrennt ist, als individuellen Wert im Filter. Beispielsweise wird in
('AWS', 'INC'),AWS,INCals zwei Zeichenfolgen betrachtet:AWSundINC. Um nachAWS,INCzu filtern, setzen Sie die Zeichenfolge im Berechtigungsdatensatz in doppelte Anführungszeichen.Wenn der eingeschränkte Datensatz ein ist SPICE Bei einem Datensatz darf die Anzahl der pro Benutzer angewendeten Filterwerte 192.000 für jedes eingeschränkte Feld nicht überschreiten. Dies gilt für die Gesamtzahl der Filterwerte, die einem Benutzernamen direkt zugewiesen sind, plus alle Filterwerte, die dem Benutzer über Gruppennamen zugewiesen werden.
Wenn es sich bei dem eingeschränkten Datensatz um einen Datensatz mit Direktabfrage handelt, variiert die Anzahl der pro Benutzer angewendeten Filterwerte je nach Datenquelle.
Eine Überschreitung des Grenzwerts für den Filterwert kann dazu führen, dass das visuelle Rendern fehlschlägt. Wir empfehlen, Ihrem eingeschränkten Datensatz eine zusätzliche Spalte hinzuzufügen, um die Zeilen auf der Grundlage der ursprünglichen eingeschränkten Spalte in Gruppen zu unterteilen, sodass die Filterliste gekürzt werden kann.
Amazon QuickSight behandelt Leerzeichen als wörtliche Werte. Wenn Sie ein Leerzeichen in einem Feld haben, für das Sie den Zugriff einschränken, gilt die Dataset-Regel für diese Zeilen. Amazon QuickSight behandelt beides NULLs und Leerzeichen (leere Zeichenketten „“) als „keinen Wert“. Eine NULL ist ein leerer Feldwert.
Je nach verwendeter Datenquelle kann eine direkte Abfrage für den Zugriff auf eine Tabelle von Berechtigungen konfiguriert werden. Begriffe, die Leerzeichen enthalten, müssen nicht in Anführungszeichen eingeschlossen werden. Wenn Sie eine direkte Abfrage verwenden, können Sie die Abfrage einfach in der ursprünglichen Datenquelle ändern.
Sie können auch Dataset-Regeln aus einer Textdatei oder einem Arbeitsblatt importieren. Wenn Sie eine CSV-Datei (Datei mit Kommas als Trennzeichen zwischen Werten) verwenden, dürfen Sie keine Leerzeichen in die gegebene Zeile einfügen. Begriffe, die Leerzeichen enthalten, müssen in Anführungszeichen eingeschlossen werden. Wenn Sie dateibasierte Datenset-Regeln verwenden, müssen Sie Änderungen vornehmen, indem Sie die vorhandenen Regeln in den Berechtigungseinstellungen des Datensets überschreiben.
Datasets mit eingeschränktem Zugriff werden im Bildschirm Datasets mit dem Wort RESTRICTED gekennzeichnet.
Untergeordnete Datensätze, die aus einem übergeordneten Datensatz mit aktiven RLS-Regeln erstellt wurden, behalten dieselben RLS-Regeln wie der übergeordnete Datensatz. Sie können dem untergeordneten Datensatz weitere RLS-Regeln hinzufügen, aber Sie können die RLS-Regeln, die der Datensatz vom übergeordneten Datensatz erbt, nicht entfernen.
Untergeordnete Datenmengen, die aus einer übergeordneten Datenmenge mit aktiven RLS-Regeln erstellt wurden, können nur mit einer Direkten Abfrage erstellt werden. Untergeordnete Datensätze, die die RLS-Regeln der übergeordneten Datenmenge erben, werden in SPICE nicht unterstützt.
Sicherheit auf Zeilenebene ist nur bei Feldern mit Textdaten (string, char, varchar usw.) möglich. Sie kann derzeit nicht für Datums- oder numerische Felder verwendet werden. Die Erkennung von Anomalien wird für Datensätze, die Sicherheit auf Zeilenebene (RLS) verwenden, nicht unterstützt.
Erstellen von Dataset-Regeln für die Sicherheit auf Zeilenebene
Führen Sie die folgenden Schritte durch, um eine Berechtigungsdatei oder Abfrage mit Dataset-Regeln zu erstellen.
So erstellen Sie eine Berechtigungsdatei oder Abfrage mit Dataset-Regeln
-
Erstellen Sie eine Datei oder eine Abfrage, die die Dataset-Regeln (Berechtigungen) für die Sicherheit auf Zeilenebene enthält.
Die Reihenfolge der Felder spielt keine Rolle. Allerdings wird bei allen Feldern die Groß-/Kleinschreibung berücksichtigt. Stellen Sie sicher, dass sie genau mit den Feldnamen und Werten übereinstimmen.
Die Struktur sollte ähnlich einer der folgenden aussehen. Stellen Sie sicher, dass Sie mindestens ein Feld haben, das entweder Benutzer oder Gruppen identifiziert. Sie können beide einbeziehen, aber es wird nur ein einziges benötigt, und es wird jeweils nur eines verwendet. Das Feld, das Sie für Benutzer oder Gruppen verwenden, kann einen beliebigen Namen haben.
Anmerkung
Wenn Sie Gruppen angeben, verwenden Sie nur QuickSight Amazon-Gruppen oder Microsoft AD-Gruppen.
Das folgende Beispiel zeigt eine Tabelle mit Gruppen.
GroupName Region Segment EMEA-Vertrieb EMEA Enterprise, SMB, Startup US-Vertrieb US Enterprise US-Vertrieb US SMB, Startup US-Vertrieb US Startup APAC-Vertrieb APAC Enterprise, SMB Corporate-Reporting APAC-Vertrieb APAC Enterprise, Startup Das folgende Beispiel zeigt eine Tabelle mit Benutzernamen.
UserName Region Segment AlejandroRosalez EMEA Enterprise, SMB, Startup MarthaRivera US Enterprise NikhilJayashankar US SMB, Startup PauloSantos US Startup SaanviSarkar APAC Enterprise, SMB sales-tps@example.com ZhangWei APAC Enterprise, Startup Das folgende Beispiel zeigt eine Tabelle mit Amazon Resource Names (ARNs) für Benutzer und Gruppen.
UserARN GroupARN Region arn:aws:quicksight:us-east-1:123456789012:user/default/Bobarn:aws:quicksight:us-east-1:123456789012:group/default/group-1APAC arn:aws:quicksight:us-east-1:123456789012:user/default/Samarn:aws:quicksight:us-east-1:123456789012:group/default/group-2US Oder wenn Sie eine CSV-Datei verwenden möchten, sollte die Struktur ähnlich wie bei einer der folgenden aussehen.
UserName,Region,Segment AlejandroRosalez,EMEA,"Enterprise,SMB,Startup" MarthaRivera,US,Enterprise NikhilJayashankars,US,SMB PauloSantos,US,Startup SaanviSarkar,APAC,"SMB,Startup" sales-tps@example.com,"","" ZhangWei,APAC-Sales,"Enterprise,Startup"GroupName,Region,Segment EMEA-Sales,EMEA,"Enterprise,SMB,Startup" US-Sales,US,Enterprise US-Sales,US,SMB US-Sales,US,Startup APAC-Sales,APAC,"SMB,Startup" Corporate-Reporting,"","" APAC-Sales,APAC,"Enterprise,Startup"UserARN,GroupARN,Region arn:aws:quicksight:us-east-1:123456789012:user/Bob,arn:aws:quicksight:us-east-1:123456789012:group/group-1,APAC arn:aws:quicksight:us-east-1:123456789012:user/Sam,arn:aws:quicksight:us-east-1:123456789012:group/group-2,USEs folgt ein SQL-Beispiel.
/* for users*/ select User as UserName, Region, Segment from tps-permissions; /* for groups*/ select Group as GroupName, Region, Segment from tps-permissions; -
Erstellen eines Datensatzes für die Datensatzregeln. Damit Sie dieses später einfacher finden können, vergeben Sie einen aussagekräftigen Namen wie beispielsweise
Permissions-Sales-Pipeline.
Regeln Das Markieren von Datensätzen zur Sicherheit auf Zeilenebene
Gehen Sie wie folgt vor, um einen Datensatz entsprechend als Regeldatensatz zu kennzeichnen.
Der Regeldatensatz ist ein Kennzeichen, das Berechtigungsdatensätze, die für die Sicherheit auf Zeilenebene verwendet werden, von regulären Datensätzen unterscheidet. Wenn ein Berechtigungsdatensatz vor dem 31. März 2025 auf einen regulären Datensatz angewendet wurde, wird er auf der Datensatz-Landingpage mit dem Kennzeichen Regeldatensatz gekennzeichnet.
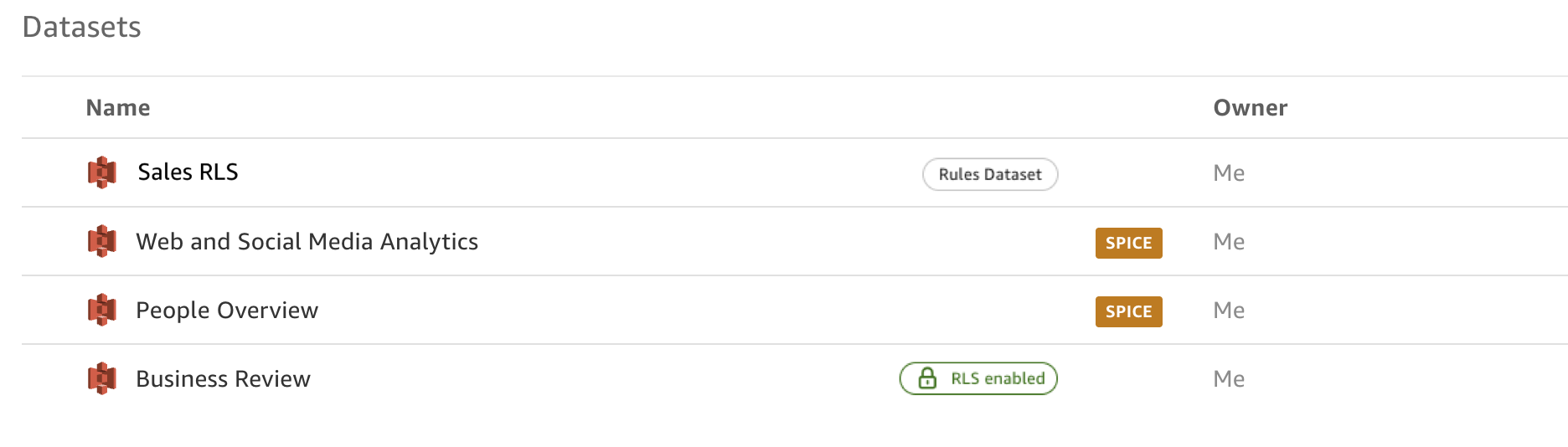
Wenn ein Berechtigungsdatensatz bis zum 31. März 2025 nicht auf einen regulären Datensatz angewendet wurde, wird er als regulärer Datensatz eingestuft. Um ihn als Regeldatensatz zu verwenden, duplizieren Sie den Berechtigungsdatensatz und kennzeichnen Sie ihn bei der Erstellung des Datensatzes in der Konsole als Regeldatensatz. Wählen Sie DATENSATZ BEARBEITEN und wählen Sie unter den Optionen die Option ALS REGELDATENSATZ DUPLIZIEREN aus, wie unten gezeigt.
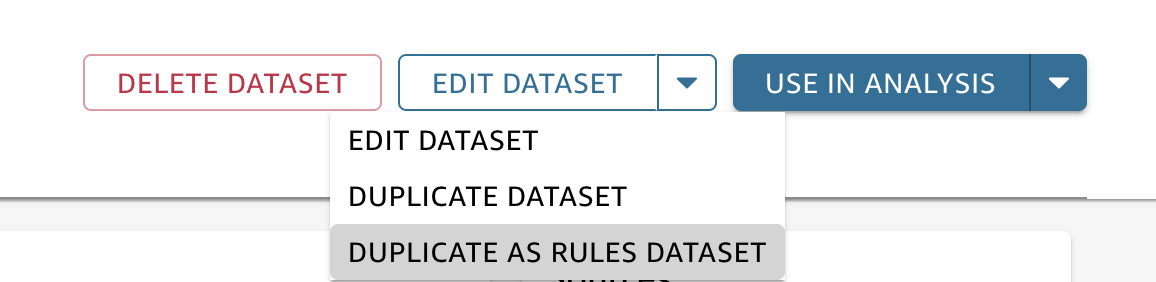
Um ihn erfolgreich als Regeldatensatz zu duplizieren, stellen Sie sicher, dass der ursprüngliche Datensatz Folgendes hat: 1. Erforderliche Spalten für Benutzermetadaten oder Gruppenmetadaten und 2. Nur Spalten vom Typ Zeichenfolge.
Um einen neuen Regeldatensatz auf der Konsole zu erstellen, wählen Sie in der Dropdownliste NEUER DATENSATZ die Option NEUER REGELDATENSATZ aus. Wenn Sie einen Regeldatensatz programmgesteuert erstellen, fügen Sie den folgenden Parameter hinzu: UseAs RLS_RULES. Dies ist ein optionaler Parameter, der nur zum Erstellen eines Regeldatensatzes verwendet wird. Sobald ein Datensatz entweder über die Konsole oder programmgesteuert erstellt und entweder als Regeldatenmenge oder reguläre Datenmenge gekennzeichnet wurde, kann er nicht mehr geändert werden.
Sobald Datensätze als Regeldatensätze gekennzeichnet sind, wendet Amazon strenge SPICE-Aufnahmeregeln auf QuickSight sie an. Um die Datenintegrität zu gewährleisten, schlagen SPICE-Erfassungen für Regeldatensätze fehl, wenn ungültige Zeilen oder Zellen vorhanden sind, die Längenbeschränkungen überschreiten. Sie müssen die Aufnahmeprobleme beheben, um eine erfolgreiche Aufnahme erneut starten zu können. Strenge Aufnahmeregeln gelten nur für Regeldatensätze. Bei regulären Datensätzen treten bei der Datensatzaufnahme keine Fehler auf, wenn Zeilen übersprungen oder Zeichenketten gekürzt werden.
Sicherheit auf Zeilenebene anwenden
Gehen Sie wie folgt vor, um die Sicherheit auf Zeilenebene (RLS) anzuwenden. Verwenden Sie dabei eine Datei oder Abfrage als Dataset, das die Regeln für Berechtigungen enthält.
So wenden Sie mithilfe einer Datei oder Abfrage Sicherheit auf Zeilenebene
-
Vergewissern Sie sich, dass Sie die Regeln als neues Dataset hinzugefügt haben. Wenn die Regeln hinzugefügt wurden, aber nicht in der Liste der Datasets angezeigt werden, aktualisieren Sie den Bildschirm.
-
Wählen Sie auf der Seite Datasets (Datensätze) das Dataset aus:
-
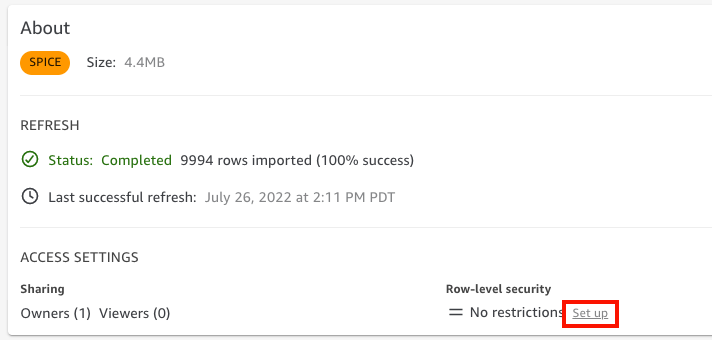
Wählen Sie auf der sich öffnenden Datensatz-Detailseite für Sicherheit auf Zeilenebene die Option Einrichten aus.
-
Wählen Sie auf der daraufhin geöffneten Seite Sicherheit auf Zeilenebene einrichten die Option Benutzerbasierte Regeln aus.
-
Wählen Sie in der erscheinenden Liste der Datasets das Dataset mit den Berechtigungen aus.
Wenn die Berechtigungsdaten nicht in diesem Bildschirm angezeigt werden, kehren Sie zur Seite mit der Dataset-Liste zurück und laden Sie diese erneut.
-
Wählen Sie unter Berechtigungsrichtlinie die Option Zugriff auf Datensatz gewähren aus. Jedes Dataset kann nur ein aktives Dataset mit Berechtigungen enthalten. Wenn Sie ein zweites Dataset mit Berechtigungen hinzufügen, wird das vorhandene überschrieben.
Wichtig
Beim Konfigurieren von Sicherheit auf Zeilenebene gelten für NULL- und leere Zeichenfolgenwerte bestimmte Einschränkungen:
-
Wenn Felder mit beschränktem Zugriff im Dataset NULL-Werte oder leere Zeichenfolgen („“) enthalten, werden die betreffenden Zeilen beim Anwenden der Beschränkungen ignoriert.
-
Innerhalb des Datasets mit den Berechtigungen werden NULL-Werte und leere Zeichenfolgen gleich behandelt. Weitere Informationen können Sie der folgenden Tabelle entnehmen.
-
Um zu verhindern, dass versehentlich vertrauliche Informationen preisgegeben werden, QuickSight überspringt Amazon leere RLS-Regeln, die allen Zugriff gewähren. Eine leere RLS-Regel tritt auf, wenn alle Spalten einer Zeile keinen Wert haben. QuickSight RLS behandelt NULL, leere Zeichenfolgen („“) oder leere, durch Kommas getrennte Zeichenketten (z. B. „,,,“) als keinen Wert.
-
Nach dem Überspringen leerer Regeln gelten weiterhin andere, nicht leere RLS-Regeln.
-
Wenn ein Berechtigungsdatensatz nur leere Regeln enthält und alle Regeln übersprungen wurden, hat niemand Zugriff auf Daten, die durch diesen Berechtigungsdatensatz eingeschränkt sind.
-
Regeln für UserName, Region GroupName, Segment Erteileter Zugriff AlejandroRosalez, EMEA-Vertrieb, EMEA, „Unternehmen, KMU, Startup“ Zugriff auf alle EMEA Enterprise-, SMB- und Startup-Werte sales-tps@example.com, Corporate-Reporting,"","" Zugriff auf alle Zeilen Der Benutzer oder die Gruppe verfügt über keine Eingabe Kein Zugriff auf Zeilen “”,“”,“”,“” Übersprungen; es werden keine Zeilen angezeigt, wenn alle anderen Regeln leer sind. NULL,““,““,NULL Übersprungen; es werden keine Zeilen angezeigt, wenn alle anderen Regeln leer sind. Jeder Benutzer, für den Sie Ihr Dashboard freigegeben haben, kann alle darin enthaltenen Daten sehen, sofern der Zugriff auf das Dataset nicht durch Dataset-Regeln beschränkt wird.
-
-
Wählen Sie Apply data set (Datensatz anwenden), um Ihre Änderungen zu speichern. Wählen Sie dann auf der Seite Datensatzregel speichern? Anwenden und aktivieren aus. Änderungen an Berechtigungen werden sofort für die vorhandenen Benutzer übernommen.
-
(Optional) Wenn Sie Berechtigungen entfernen möchten, entfernen Sie zunächst die Dataset-Regeln aus dem Dataset.
Vergewissern Sie sich, dass die Dataset-Regeln entfernt wurden. Wählen Sie dann das Dataset mit den Berechtigungen aus und klicken Sie auf Remove data set (Datensatz entfernen).
Um Berechtigungen zu überschreiben, wählen Sie ein neues Dataset mit Berechtigungen aus und wenden Sie dieses an. Sie können denselben Datensatznamen verwenden. Stellen Sie jedoch sicher, dass Sie die neuen Berechtigungen auf dem Bildschirm Berechtigungen anwenden, um diese Berechtigungen zu aktivieren. SQL-Abfragen werden dynamisch aktualisiert, sodass sie außerhalb von Amazon verwaltet werden können QuickSight. Bei Abfragen werden die Berechtigungen aktualisiert, wenn der Cache für direkte Abfragen automatisch aktualisiert wird.
Wenn Sie ein dateibasiertes Dataset mit Berechtigungen löschen, bevor Sie es aus dem Ziel-Dataset entfernt haben, können zugriffsbeschränkte Benutzer nicht mehr auf das Dataset zugreifen. Während sich das Dataset in diesem Zustand befindet, bleibt es als RESTRICTED gekennzeichnet. Wenn Sie jedoch den Bildschirm Permissions dieses Datasets anzeigen, können Sie sehen, dass keine Dataset-Regeln ausgewählt sind.
Um dieses Problem zu beheben, legen Sie neue Dataset-Regeln fest. Das Erstellen eines Datasets mit demselben Namen reicht dazu nicht aus. Sie müssen das neue Dataset mit Berechtigungen auf dem Bildschirm Permissions auswählen. Diese Einschränkung gilt nicht für direkte SQL-Abfragen.
