Amazon Redshift wird UDFs ab dem 1. November 2025 die Erstellung von neuem Python nicht mehr unterstützen. Wenn Sie Python verwenden möchten UDFs, erstellen Sie das UDFs vor diesem Datum liegende. Bestehendes Python UDFs wird weiterhin wie gewohnt funktionieren. Weitere Informationen finden Sie im Blogbeitrag
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Spaltenweise Speicherung
In diesem Abschnitt wird die spaltenorientierte Speicherung beschrieben. Dabei handelt es sich um die Methode, mit der Amazon Redshift Tabellendaten effizient speichert.
Die spaltenweise Speicherung für Datenbanktabellen trägt wesentlich zur Optimierung der Leistung analytischer Abfragen bei, da sie die allgemeinen Datenträger-I/O-Anforderungen drastisch reduziert. Die Menge an Daten, die von der Festplatte geladen werden müssen, verringert sich.
Die folgenden Abbildungen zeigen, wie durch die spaltenweise Datenspeicherung Effizienzen erzielt werden und wie sich diese in Effizienzen beim Abrufen von Daten in den Arbeitsspeicher niederschlagen.
Die erste Abbildung zeigt, wie Datensätze aus Datenbanktabellen in der Regel zeilenweise in Datenträgerblöcken gespeichert werden.
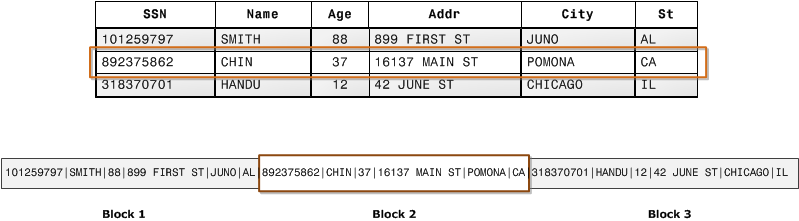
In einer typischen relationalen Datenbanktabelle enthält jede Zeile Feldwerte für einen einzelnen Datensatz. Bei der zeilenweisen Datenbankspeicherung speichern Datenblöcke Werte sequenziell für alle aufeinanderfolgenden Spalten der gesamten Zeile. Wenn die Blockgröße kleiner ist als die Größe eines Datensatzes, nimmt die Speicherung eines vollständigen Datensatzes möglicherweise mehr als einen Block ein. Wenn die Blockgröße größer ist als die Größe eines Datensatzes, nimmt die Speicherung eines vollständigen Datensatzes möglicherweise weniger als einen Block ein, was eine ineffiziente Nutzung von Speicherplatz bedeutet. Bei Anwendungen für die Onlineverarbeitung von Transaktionen (Online Transaction Processing, OLTP) beinhalten die meisten Transaktionen häufiges Lesen und Schreiben aller Werte für ganze Datensätze – in der Regel ein Datensatz oder eine kleine Anzahl an Datensätzen gleichzeitig. Folglich ist die zeilenweise Speicherung optimal für OLTP-Datenbanken geeignet.
Die nächste Abbildung zeigt, wie bei der spaltenweise Speicherung die Werte für alle Spalten sequenziell in Datenträgerblöcken gespeichert werden.
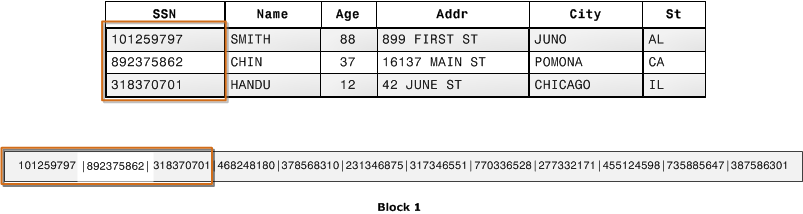
Bei der spaltenweisen Speicherung speichert jeder Datenblock die Werte einer einzelnen Spalte für mehrere Zeilen. Wenn Datensätze im System eintreffen, konvertiert Amazon Redshift die Daten transparent in die spaltenweise Speicherung für alle Spalten.
In diesem vereinfachten Beispiel für die spaltenweise Speicherung enthält jeder Datenblock Spaltenfeldwerte für bis zu dreimal so viele Datensätze wie bei der zeilenbasierten Speicherung. Dies bedeutet, dass zum Lesen derselben Anzahl an Spaltenfeldwerten für dieselbe Anzahl an Datensätzen verglichen mit der zeilenweisen Speicherung ein Drittel der I/O-Operationen erforderlich ist. In der Praxis ist die Speichereffizienz bei der Verwendung von Tabellen mit einer sehr hohen Anzahl an Spalten und Zeilen noch größer.
Ein weiterer Vorteil besteht darin, dass Blockdaten ein speziell für den Spaltendatentyp ausgewähltes Komprimierungsschema verwenden können, da alle Blöcke denselben Datentyp beinhalten. Dadurch werden der benötigte Speicherplatz und I/O weiter reduziert. Weitere Informationen zu Komprimierungsverschlüsselungen basierend auf Datentypen erhalten Sie unter Kompressionskodierungen.
Die Einsparungen an Speicherplatz für Daten auf der Festplatte gelten auch für das Abrufen und Speichern dieser Daten im Arbeitsspeicher. Da bei vielen Datenbankoperationen der Zugriff auf bzw. die Arbeit mit nur einer kleinen Anzahl an Spalten gleichzeitig erforderlich ist, lässt sich Speicherplatz einsparen, indem nur Blöcke für Spalten abgerufen werden, die Sie für eine Abfrage tatsächlich benötigen. Während OLTP-Transaktionen in der Regel die meisten Spalten in einer Zeile für eine kleine Anzahl an Datensätzen umfassen, lesen Data Warehouse-Abfragen in der Regel nur einige wenige Spalten für eine sehr große Anzahl an Zeilen. Dies bedeutet, dass zum Lesen derselben Anzahl an Spaltenfeldwerten für dieselbe Anzahl an Zeilen ein Bruchteil der I/O-Operationen erforderlich ist. Es wird nur ein Bruchteil des Arbeitsspeichers verwendet, der für die Verarbeitung zeilenweiser Blöcke erforderlich wäre. In der Praxis sind die Effizienzgewinne bei der Verwendung von Tabellen mit einer sehr hohen Anzahl an Spalten und Zeilen proportional größer. Nehmen wir beispielsweise an, eine Tabelle hat 100 Spalten. Eine Abfrage, die fünf Spalten verwendet, muss nur etwa fünf Prozent der in der Tabelle enthaltenen Daten lesen. Diese Einsparungen wiederholen sich bei großen Datenbanken für möglicherweise Milliarden oder sogar Billionen an Datensätzen. Im Gegensatz dazu würde eine zeilenweise Datenbank ebenfalls die Blöcke mit den 95 nicht benötigten Spalten lesen.
Typische Datenbankblock-Größen reichen von 2 KB bis 32 KB. Amazon Redshift verwendet eine Blockgröße von 1 MB. Dies ist effizienter und sorgt für eine weitere Reduzierung der Zahl der I/O-Anforderungen, die für das Laden von Datenbanken oder andere Operationen im Zusammenhang mit einer Abfrageausführung erforderlich sind.
