Amazon Redshift wird UDFs ab dem 1. November 2025 die Erstellung von neuem Python nicht mehr unterstützen. Wenn Sie Python verwenden möchten UDFs, erstellen Sie das UDFs vor diesem Datum liegende. Bestehendes Python UDFs wird weiterhin wie gewohnt funktionieren. Weitere Informationen finden Sie im Blogbeitrag
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Architektur des Data Warehouse-Systems
In diesem Abschnitt werden die Komponenten der Amazon Redshift Data Warehouse-Architektur erläutert, wie in der folgenden Abbildung dargestellt.
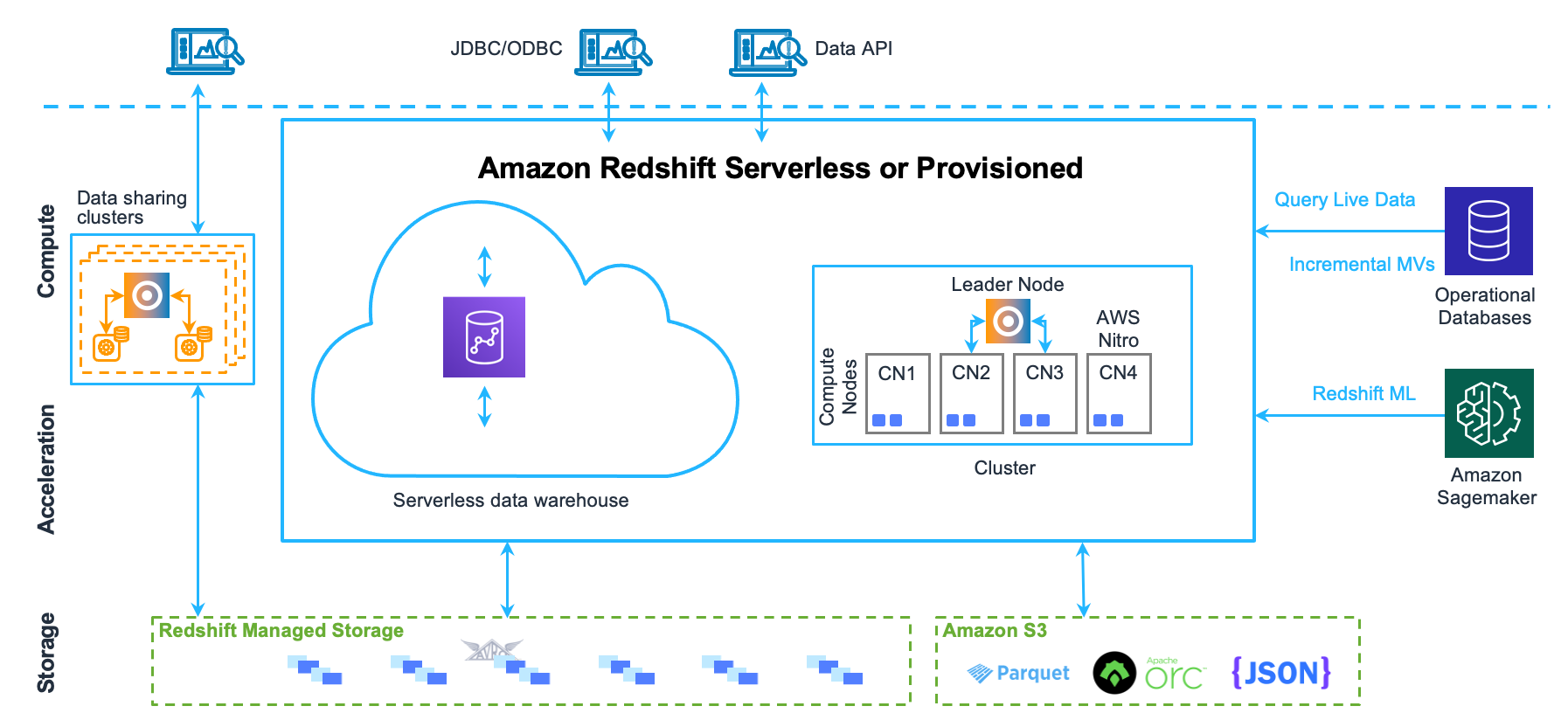
Clientanwendungen
Amazon Redshift lässt sich in verschiedene Datenlade- und ETL-Tools (Extrahieren, Transformieren und Laden) sowie in Business-Intelligence (BI)-Berichterstellungs-, Data-Mining- und Analysetools integrieren. Amazon Redshift basiert auf dem offenen Standard PostgreSQL, sodass die meisten vorhandenen SQL-Client-Anwendungen mit nur wenigen Änderungen funktionieren. Weitere Informationen zu wichtigen Unterschieden zwischen Amazon-Redshift-SQL und PostgreSQL finden Sie unter Amazon Redshift und PostgreSQL.
Cluster
Zentraler Bestandteil der Infrastruktur des Data Warehouse von Amazon Redshift ist ein Cluster.
Ein Cluster besteht aus einem oder mehreren Datenverarbeitungsknoten. Wird ein Cluster mit zwei oder mehr Datenverarbeitungsknoten bereitgestellt, koordiniert ein zusätzlicher Führungsknoten die Datenverarbeitungsknoten und verarbeitet die externe Kommunikation. Ihre Client-Anwendung interagiert nur mit dem Führungsknoten direkt. Die Datenverarbeitungsknoten sind für externe Anwendungen transparent.
Führungsknoten
Der Führungsknoten verwaltet die Kommunikation mit Client-Programmen sowie die gesamte Kommunikation mit Datenverarbeitungsknoten. Er analysiert und entwickelt Ausführungspläne für Datenbankoperationen, insbesondere die erforderlichen Schritte zum Abrufen von Ergebnissen vor komplexe Abfragen. Auf der Grundlage des Ausführungsplans kompiliert der Führungsknoten Code, verteilt den kompilierten Code auf die Datenverarbeitungsknoten und weist jedem Datenverarbeitungsknoten einen Teil der Daten zu.
Der Führungsknoten verteilt SQL-Anweisungen nur dann an den Datenverarbeitungsknoten, wenn eine Abfrage auf Tabellen verweist, die auf dem Datenverarbeitungsknoten gespeichert sind. Alle anderen Abfragen werden ausschließlich auf dem Führungsknoten ausgeführt. Amazon Redshift wurde entwickelt, um bestimmte SQL-Funktionen nur auf dem Führungsknoten zu implementieren. Eine Abfrage, die eine dieser Funktionen verwendet, gibt einen Fehler zurück, wenn sie auf Tabellen verweist, die sich auf dem Datenverarbeitungsknoten befinden. Weitere Informationen finden Sie unter SQL-Funktionen, die auf dem Führungsknoten unterstützt werden.
Datenverarbeitungsknoten
Der Führungsknoten kompiliert Code für einzelne Elemente des Ausführungsplans und weist den Code einzelnen Datenverarbeitungsknoten zu. Die Datenverarbeitungsknoten führen den kompilierten Code aus und senden Zwischenergebnisse zur endgültigen Aggregation an den Führungsknoten zurück.
Jeder Datenverarbeitungsknoten verfügt über eine eigene dedizierte CPU und eigenen Arbeitsspeicher, die von dem Knotentyp bestimmt werden. Bei zunehmendem Workload können Sie die Rechenkapazität eines Clusters steigern, indem sie die Anzahl der Knoten erhöhen und/oder ein Upgrade des Knotentyps ausführen.
Amazon Redshift bietet verschiedene Knotentypen für Ihre Rechenanforderungen. Details zu den einzelnen Knotentypen finden Sie unter Amazon-Redshift-Cluster im Amazon-Redshift-Verwaltungshandbuch.
Redshift Managed Storage
Data-Warehouse-Daten werden in einer separaten Speicherschicht gespeichert – Redshift Managed Storage (RMS). RMS bietet die Möglichkeit einer Skalierung Ihres Speichers auf Petabyte mithilfe von Amazon-S3-Speicher. Mit RMS können Sie Rechenleistung und Speicher unabhängig voneinander skalieren und bezahlen. Somit können Sie die Größe des Clusters ausschließlich basierend auf Ihren Datenverarbeitungsanforderungen festlegen. Als Tier-1-Cache wird automatisch ein leistungsstarker lokaler SSD-basierter Speicher verwendet. Durch Optimierungen der Temperatur und des Alters von Datenblöcken sowie der Workload-Muster wird zudem eine hohe Leistung erzielt. Bei Bedarf wird der Speicher automatisch auf Amazon S3 skaliert, ohne dass ein Eingreifen erforderlich ist.
Knoten-Slices
Ein Datenverarbeitungsknoten ist in Slices aufgeteilt. Jedem Slice wird ein Teil des Arbeitsspeichers und des Festplattenspeichers des Knoten zugeordnet. Dort verarbeitet er einen Teil des dem Knoten zugewiesenen Workloads. Der Führungsknoten verwaltet die Verteilung von Daten an die Slices und teilt den Workload für Abfragen oder sonstige Datenbankoperationen auf die Slices auf. Die Slices arbeiten dann parallel, um die Operation abzuschließen.
Die Anzahl an Slices pro Knoten wird durch die Knotengröße des Clusters bestimmt. Weitere Informationen zur Anzahl der Slices für die einzelnen Knotengrößen finden Sie unter About clusters and nodes (Informationen zu Clustern und Knoten) im Amazon-Redshift-Verwaltungshandbuch.
Wenn Sie eine Tabelle erstellen, können Sie optional eine Spalte als Verteilungsschlüssel angeben. Wenn die Tabelle mit Daten geladen wird, werden die Zeilen entsprechend dem für die Tabelle definierten Verteilungsschlüssel an die Knoten-Slices verteilt. Ein guter Verteilungsschlüssel ermöglicht es Amazon Redshift, die parallele Verarbeitung zu verwenden, um effektiv Daten zu laden und Abfragen auszuführen. Informationen zur Auswahl eines Verteilungsschlüssels finden Sie unter Auswahl des besten Verteilungsstils.
Internes Netzwerk
Amazon Redshift nutzt Verbindungen mit hoher Bandbreite, räumliche Nähe und benutzerdefinierte Kommunikationsprotokolle für die Bereitstellung privater Netzwerkkommunikation in Ultrahochgeschwindigkeit zwischen dem Führungsknoten und den Datenverarbeitungsknoten. Die Datenverarbeitungsknoten werden auf einem getrennten, isolierten Netzwerk ausgeführt, auf das Client-Anwendungen niemals direkt zugreifen.
Datenbanken
Ein Cluster umfasst einen oder mehrere Datenbanken. Die Benutzerdaten werden auf den Datenverarbeitungsknoten gespeichert. Ihr SQL-Client kommuniziert mit dem Führungsknoten, der wiederum die Abfrageausführung mit den Datenverarbeitungsknoten koordiniert.
Amazon Redshift ist ein relationales Datenbankmanagementsystem (RDBMS), sodass es mit anderen RDBMS-Anwendungen kompatibel ist. Obwohl es dieselben Funktionen wie ein typisches RDBMS bereitstellt, einschließlich Funktionen zur Online-Transaktionsverarbeitung (Online Transaction Processing, OLTP), wie beispielsweise das Einsetzen und Löschen von Daten, ist Amazon Redshift optimiert für hochperformante Analysen und die Berichterstellung zu sehr großen Datensätzen.
Amazon Redshift basiert auf PostgreSQL. Zwischen Amazon Redshift und PostgreSQL gibt es eine Reihe sehr wichtiger Unterschiede, die Sie berücksichtigen müssen, wenn Sie Ihre Data-Warehouse-Anwendungen entwerfen und entwickeln. Weitere Informationen zu den Unterschieden zwischen Amazon-Redshift-SQL und PostgreSQL finden Sie in Amazon Redshift und PostgreSQL.
