Amazon Redshift wird UDFs ab dem 1. November 2025 die Erstellung von neuem Python nicht mehr unterstützen. Wenn Sie Python verwenden möchten UDFs, erstellen Sie das UDFs vor diesem Datum liegende. Bestehendes Python UDFs wird weiterhin wie gewohnt funktionieren. Weitere Informationen finden Sie im Blogbeitrag
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Übersicht über die Schritte des Abfrageplans
Sie können die Schritte von Abfrageplänen anzeigen, indem Sie den Befehls EXPLAIN ausführen. Das folgende Beispiel zeigt eine SQL-Abfrage und erläutert die Ausgabe. Wenn Sie den Abfrageplan von unten nach oben lesen, sehen Sie die einzelnen logischen Operationen, die für die Ausführung der Abfrage verwendet werden. Weitere Informationen finden Sie unter Einen Abfrageplan erstellen und interpretieren.
explain select eventname, sum(pricepaid) from sales, event where sales.eventid = event.eventid group by eventname order by 2 desc;
XN Merge (cost=1002815366604.92..1002815366606.36 rows=576 width=27) Merge Key: sum(sales.pricepaid) -> XN Network (cost=1002815366604.92..1002815366606.36 rows=576 width=27) Send to leader -> XN Sort (cost=1002815366604.92..1002815366606.36 rows=576 width=27) Sort Key: sum(sales.pricepaid) -> XN HashAggregate (cost=2815366577.07..2815366578.51 rows=576 width=27) -> XN Hash Join DS_BCAST_INNER (cost=109.98..2815365714.80 rows=172456 width=27) Hash Cond: ("outer".eventid = "inner".eventid) -> XN Seq Scan on sales (cost=0.00..1724.56 rows=172456 width=14) -> XN Hash (cost=87.98..87.98 rows=8798 width=21) -> XN Seq Scan on event (cost=0.00..87.98 rows=8798 width=21)
Beim Generieren eines Abfrageplans gliedert der Abfrageoptimierer den Plan in Streams, Segmente und Schritte auf. Der Abfrageoptimierer unterbricht den Plan, um die Verteilung der Daten und Abfrage-Workload an die Rechenknoten vorzubereiten. Weitere Informationen zu Segmenten und Schritten finden Sie unter Workflow der Abfrageplanung und -ausführung.
Die folgende Abbildung zeigt die vorhergehende Abfrage und den zugehörigen Abfrageplan. Es zeigt an, wie die beteiligten Abfrageoperationen Schritten zugeordnet werden, die Amazon Redshift zum Generieren von kompiliertem Code für die Rechenknoten-Slices verwendet. Den Operationen in dem Abfrageplan werden mehrere Schritte in Segmenten und manchmal auch mehrere Segmente in den Streams zugeordnet.
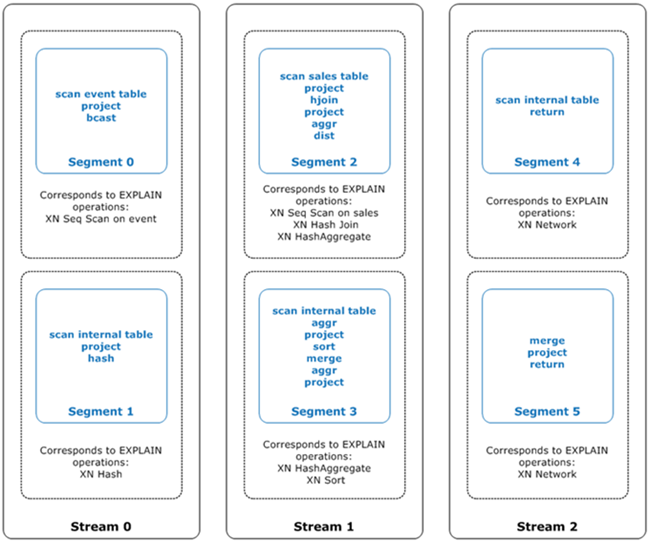
In dieser Abbildung führt der Abfrageoptimierer den Abfrageplan wie folgt aus:
In
Stream 0führt die AbfrageSegment 0mit einem sequenziellen Scanvorgang aus, um die Tabelleeventszu scannen. Die Abfrage wird bisSegment 1mit einem Hash-Vorgang fortgesetzt, um die Hashtabelle für die innere Tabelle in der Verknüpfung zu erstellen.In
Stream 1führt die AbfrageSegment 2mit einem sequenziellen Scanvorgang aus, um die Tabellesaleszu scannen. Es wird mitSegment 2mit einem Hash-Join fortgefahren, um Tabellen zu verknüpfen, bei denen die Join-Spalten nicht sowohl Verteilungsschlüssel als auch Sortierschlüssel sind. Es wird wieder mitSegment 2mit einem Hash-Aggregat fortgefahren, um Ergebnisse zu aggregieren. Dann führt die AbfrageSegment 3mit einem Hash-Aggregatvorgang aus, um unsortierte gruppierte Aggregatfunktionen auszuführen, und einen Sortiervorgang, um die ORDER BY-Klausel und andere Sortiervorgänge auszuwerten.In
Stream 2führt die Abfrage einen Netzwerkvorgang inSegment 4undSegment 5aus, um Zwischenergebnisse zur weiteren Verarbeitung an den Führerknoten zu senden.
Das letzte Segment einer Abfrage gibt die Daten zurück. Wenn der Rückgabesatz aggregiert oder sortiert ist, senden die Rechenknoten jeweils ihren Teil des Zwischenergebnisses an den Führungsknoten. Der Führungsknoten führt dann die Daten zusammen, sodass das Endergebnis an den anfordernden Client zurückgesendet werden kann.
Weitere Hinweise zu EXPLAIN-Operatoren finden Sie unter EXPLAIN.
