Amazon Redshift wird UDFs ab dem 1. November 2025 die Erstellung von neuem Python nicht mehr unterstützen. Wenn Sie Python verwenden möchten UDFs, erstellen Sie das UDFs vor diesem Datum liegende. Bestehendes Python UDFs wird weiterhin wie gewohnt funktionieren. Weitere Informationen finden Sie im Blogbeitrag
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Anzeigen von Cluster-Leistungsdaten
Mithilfe von Cluster-Metriken in Amazon Redshift können Sie die folgenden gängigen Leistungsaufgaben durchführen:
-
Feststellung, ob die Clustermetriken in einem bestimmten Zeitraum abnorm sind und, falls dies der Fall ist, Identifizierung der Abfragen, die dafür verantwortlich sind.
-
Prüfung, ob sich frühere oder aktuelle Abfragen auf die Clusterleistung auswirken. Wenn Sie eine problematische Abfrage identifizieren, können Sie Einzelheiten dazu anzeigen, einschließlich der Clusterleistung während der Ausführung der Abfrage. Diese Informationen können Ihnen dabei helfen, herauszufinden, warum die Abfrage langsam durchgeführt wurde, und was Sie tun können, um ihre Leistung zu verbessern.
So zeigen Sie Leistungsdaten an:
-
Melden Sie sich bei der an AWS Management Console und öffnen Sie die Amazon Redshift Redshift-Konsole unter https://console.aws.amazon.com/redshiftv2/
. -
Wählen Sie im Navigationsmenü Clusters (Cluster) und dann den Namen eines Clusters aus der Liste aus, um die Details zu dem Cluster aufzurufen. Die Details des Clusters werden angezeigt, u. a. einschließlich der Registerkarten Cluster performance (Cluster-Leistung), Query monitoring (Abfrageüberwachung), Databases (Datenbanken), Datashares, Schedules (Zeitpläne), Maintenance (Wartung) und Properties (Eigenschaften).
-
Wählen Sie die Registerkarte Cluster performance (Cluster-Leistung) für Leistungsinformationen, einschließlich der folgenden, aus:
-
CPU-Nutzung
-
Percentage disk space used (Prozentualer Festplattenspeicherverbrauch)
-
Datenbankverbindungen
-
Gesundheitsstatus
-
Query duration (Abfragedauer)
-
Query throughput (Abfrage Durchsatz)
-
Concurrency scaling activity (Parallelitätsskalierungsaktivität)
Viele weitere Metriken sind verfügbar. Um die verfügbaren Metriken anzuzeigen und die angezeigten auszuwählen, wählen Sie das Preferences (Präferenzen)-Symbol aus.
-
Diagramme der Clusterleistung
Im Folgenden finden Sie einige Beispiele für Diagramme, die in der neuen Amazon-Redshift-Konsole angezeigt werden.
-
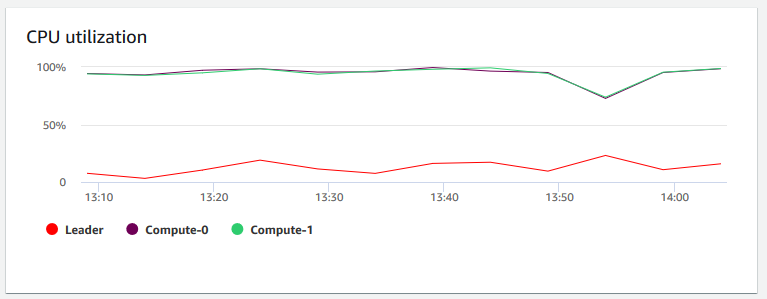
CPU utilization (CPU-Auslastung) – zeigt den Prozentsatz der CPU-Auslastung für alle Knoten (Führungs- und Rechenknoten) an. Um einen Zeitpunkt zu ermitteln, zu dem die Clusterauslastung am niedrigsten ist, bevor die Clustermigration oder andere ressourcenaufwändige Vorgänge geplant wird, überwachen Sie dieses Diagramm, um die CPU-Auslastung pro einzelnem Knoten oder für alle Knoten anzuzeigen.
-
Maintenance mode (Wartungsmodus) – zeigt mithilfe der Indikatoren
OnundOffan, ob sich der Cluster zu einem bestimmten Zeitpunkt im Wartungsmodus befindet. Sie können den Zeitpunkt sehen, zu dem der Cluster gewartet wird. Sie können diese Zeit dann mit Operationen korrelieren, die mit dem Cluster durchgeführt werden, um seine zukünftigen Ausfallzeiten für wiederkehrende Ereignisse abzuschätzen.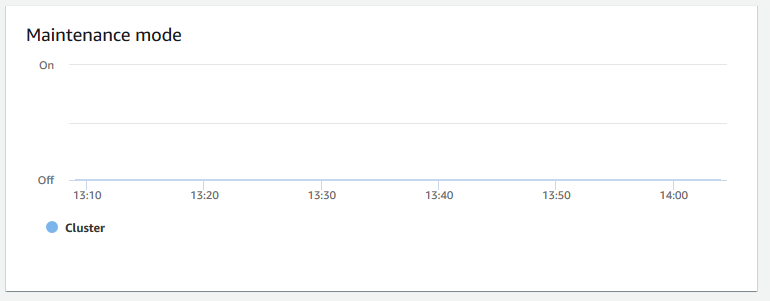
-
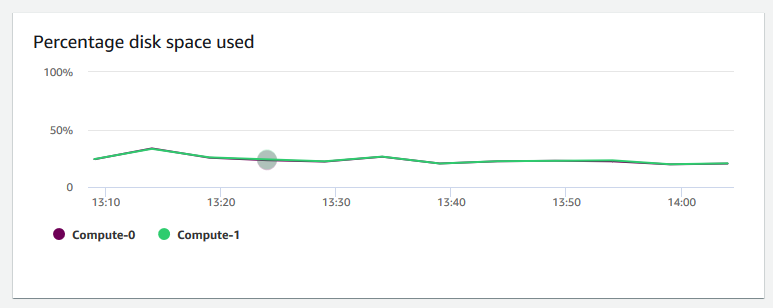
Percentage disk space used (Prozentualer Speicherplatzverbrauch) – zeigt den Anteil des verwendeten Speicherplatzes pro Rechenknoten (nicht für den Cluster als Ganzes) an. Sie können dieses Diagramm untersuchen, um die Datenträgerauslastung zu überwachen. Wartungsvorgänge wie VACUUM und COPY verwenden temporären Zwischenspeicher für ihre Sortiervorgänge. Eine Spitze in der Datenträgernutzung ist daher zu erwarten.
-
Read throughput (Lesedurchsatz) – zeigt die durchschnittliche Zahl der Megabyte an, die pro Sekunde vom Datenträger gelesen werden. Sie können dieses Diagramm auswerten, um den entsprechenden physischen Aspekt des Clusters zu überwachen. Dieser Durchsatz beinhaltet nicht den Netzwerkdatenverkehr zwischen den Instances im Cluster und dessen Volume.
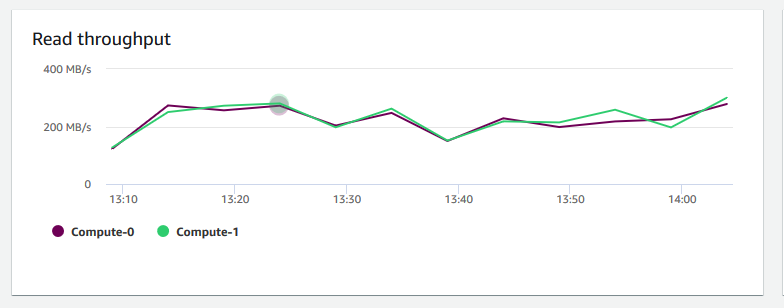
-
Leselatenz — Zeigt die durchschnittliche Zeit an, die für I/O Festplattenlesevorgänge pro Millisekunde benötigt wird. Sie können die Reaktionszeiten für die zurückzugebenden Daten anzeigen. Wenn die Latenz hoch ist, bedeutet dies, dass der Absender mehr Zeit im Leerlauf verbringt (keine neuen Pakete sendet), was Geschwindigkeit des Durchsatzanstiegs verringert.
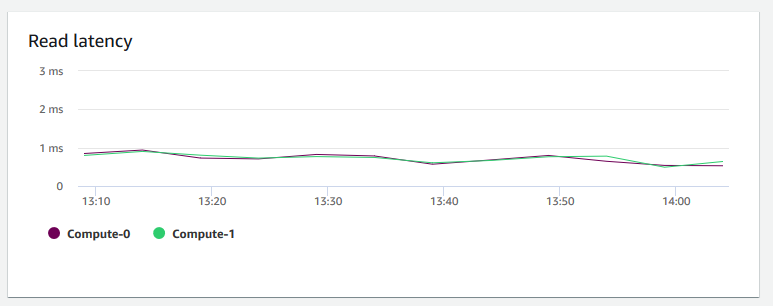
-
Write throughput (Schreibdurchsatz) – zeigt die durchschnittliche Zahl der Megabyte an, die pro Sekunde auf den Datenträger geschrieben werden. Sie können diese Metrik auswerten, um den entsprechenden physischen Aspekt des Clusters zu überwachen. Dieser Durchsatz beinhaltet nicht den Netzwerkdatenverkehr zwischen den Instances im Cluster und dessen Volume.
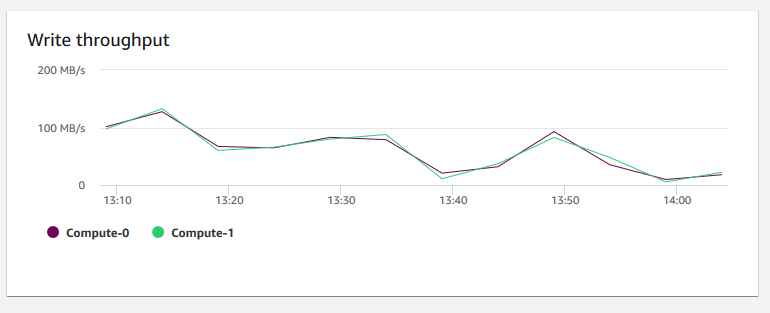
-
Schreiblatenz — Zeigt die durchschnittliche Zeit in Millisekunden an, die für Schreibvorgänge auf der Festplatte benötigt wird. I/O Sie können die Zeit für die Rückgabe der Schreibbestätigung auswerten. Wenn die Latenz hoch ist, bedeutet dies, dass der Absender mehr Zeit im Leerlauf verbringt (keine neuen Pakete sendet), was Geschwindigkeit des Durchsatzanstiegs verringert.
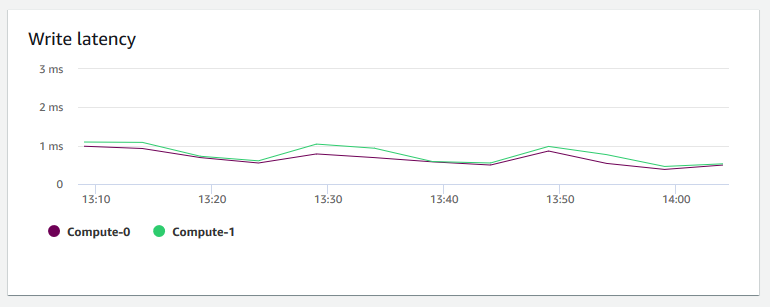
-
Database connections (Datenbankverbindungen) – zeigt die Anzahl der Datenbankverbindungen zu einem Cluster an. Sie können dieses Diagramm verwenden, um zu sehen, wie viele Verbindungen mit der Datenbank hergestellt werden, und um einen Zeitpunkt zu ermitteln, zu dem die Clusterauslastung am niedrigsten ist.
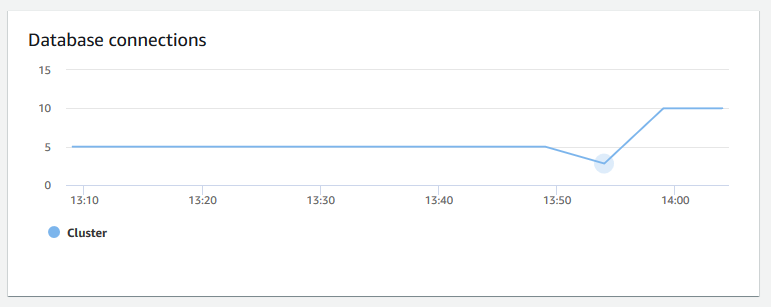
-
Total table count (Gesamtanzahl der Tabellen) – zeigt die Anzahl der Benutzertabellen an, die zu einem bestimmten Zeitpunkt innerhalb eines Clusters geöffnet sind. Sie können die Clusterleistung überwachen, wenn die Anzahl geöffneter Tabellen hoch ist.
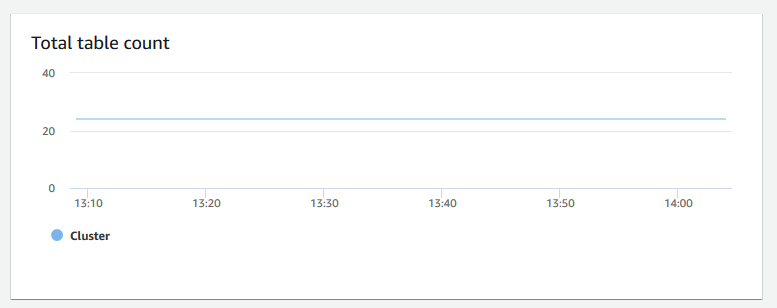
-
Health status (Integritätsstatus) – zeigt den Zustand des Clusters als
HealthyoderUnhealthyan. Wenn der Cluster eine Verbindung zu seiner Datenbank herstellen kann und eine einfache Abfrage erfolgreich ausführt, gilt der Cluster als fehlerfrei. Andernfalls ist der Cluster fehlerhaft. Ein fehlerhafter Status kann auftreten, wenn die Auslastung der Cluster-Datenbank sehr hoch ist, oder falls ein Konfigurationsproblem mit einer Datenbank auf dem Cluster vorliegt.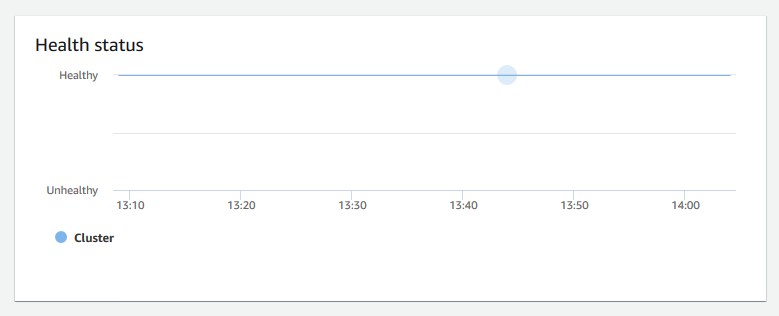
-
Query duration (Abfragedauer) – zeigt die durchschnittliche Zeit für das Abschließen einer Abfrage in Mikrosekunden an. Sie können die Daten in diesem Diagramm vergleichen, um die I/O Leistung innerhalb des Clusters zu messen und gegebenenfalls die zeitaufwändigsten Abfragen zu optimieren.
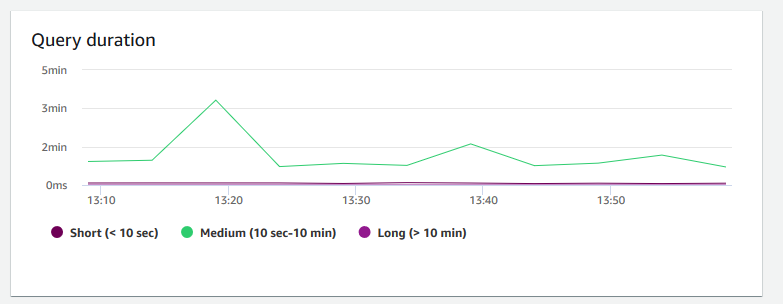
-
Query throughput (Abfragedurchsatz) – zeigt die durchschnittliche Anzahl abgeschlossener Abfragen pro Sekunde an. Sie können Daten in diesem Diagramm analysieren, um die Datenbankleistung zu messen und die Fähigkeit des Systems zu charakterisieren, ein Mehrbenutzer-Workload auf ausgewogene Weise zu unterstützen.
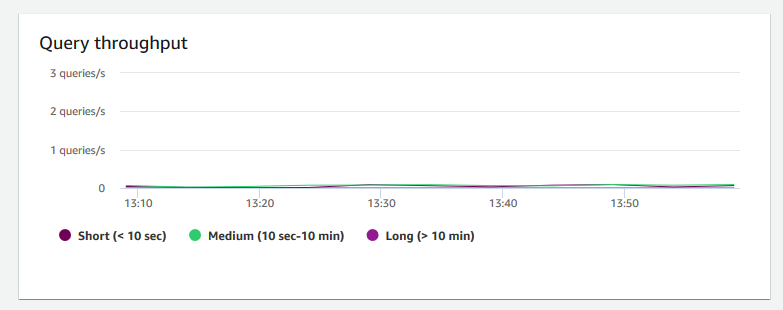
-
Query duration per WLM queue (Abfragedauer pro WLM-Warteschlange) – zeigt die durchschnittliche Zeit für das Abschließen einer Abfrage in Mikrosekunden an. Sie können die Daten in diesem Diagramm vergleichen, um die I/O Leistung pro WLM-Warteschlange zu messen und gegebenenfalls die zeitaufwändigsten Abfragen zu optimieren.
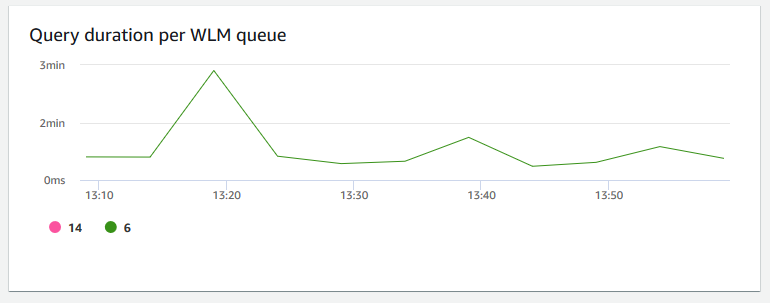
-
Query throughput per WLM queue (Abfragedurchsatz pro WLM-Warteschlange) – zeigt die durchschnittliche Anzahl abgeschlossener Abfragen pro Sekunde an. Sie können Daten in diesem Diagramm analysieren, um die Datenbankleistung pro WLM-Warteschlange zu messen.
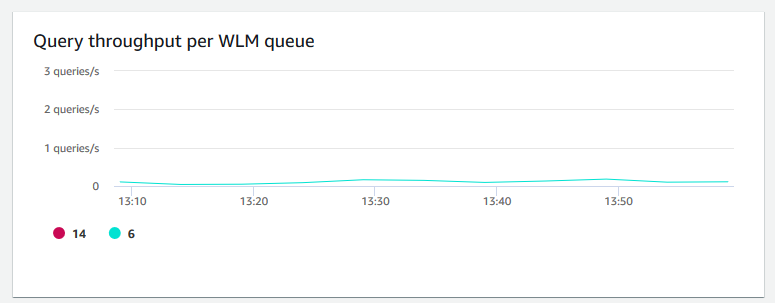
-
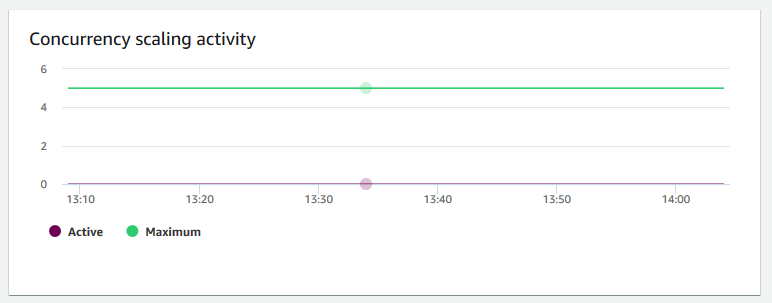
Concurrency scaling activity (Nebenläufigkeitsskalierungsaktivität) – zeigt die Anzahl der aktiven Nebenläufigkeitsskalierungs-Cluster an. Bei aktivierter Nebenläufigkeitsskalierung fügt Amazon Redshift automatisch zusätzliche Cluster-Kapazität hinzu, wenn diese benötigt wird, um eine gestiegene Zahl von gleichzeitigen Leseabfragen zu verarbeiten.