Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Erkennung von Objekten und Konzepten
Dieser Abschnitt enthält Informationen zur Erkennung von Labels in Bildern und Videos mit Amazon Rekognition Image und Amazon Rekognition Video.
Ein Label oder ein Tag ist ein Objekt oder ein Konzept (einschließlich Szenen und Aktionen), das in einem Bild oder Video anhand seines Inhalts gefunden wird. Ein Bild von Menschen an einem tropischen Strand kann zum Beispiel Etiketten wie Palme (Objekt), Strand (Szene), Laufen (Aktion) und Draußen (Konzept) enthalten.
Etiketten, die von Rekognition-Etikettenerkennungsoperationen unterstützt werden
Anmerkung
Amazon Rekognition macht binäre geschlechtsspezifische Vorhersagen (Mann, Frau, Mädchen usw.), die auf dem physischen Erscheinungsbild einer Person in einem bestimmten Bild basieren. Diese Art von Vorhersage dient nicht dazu, die Geschlechtsidentität einer Person zu kategorisieren, und Sie sollten Amazon Rekognition nicht verwenden, um eine solche Entscheidung zu treffen. Beispielsweise könnte ein männlicher Schauspieler, der für eine Rolle eine langhaarige Perücke und Ohrringe trägt, als weiblich eingestuft werden.
Die Verwendung von Amazon Rekognition für binäre geschlechtsspezifische Vorhersagen eignet sich am besten für Anwendungsfälle, in denen aggregierte Statistiken zur Geschlechterverteilung analysiert werden müssen, ohne bestimmte Benutzer zu identifizieren. Zum Beispiel der Prozentsatz weiblicher Benutzer im Vergleich zu männlichen Benutzern auf einer Social-Media-Plattform.
Wir raten davon ab, anhand von binären Geschlechtervoraussagen Entscheidungen zu treffen, durch sich auf die Rechte, Datenschutz oder Zugriff auf Services von Einzelpersonen auswirken.
Amazon Rekognition sendet Label in englischer Sprache zurück. Sie können Amazon Translate
Das folgende Diagramm zeigt die Reihenfolge der Anrufvorgänge, abhängig von Ihren Zielen für die Nutzung der Amazon Rekognition Image- oder Amazon Rekognition Video Video-Operationen:

Label-Antwortobjekte
Begrenzungsrahmen
Amazon Rekognition Image und Amazon Rekognition Video können die Begrenzungsrahmen für gängige Objektlabels wie z. B. Personen, Fahrzeuge, Möbel, Bekleidung oder Haustiere zurückgeben. Für weniger gängige Objektlabels werden keine Informationen zum Begrenzungsrahmen zurückgegeben. Sie können die Begrenzungsrahmen verwenden, um die genaue Position von Objekten in einem Bild zu finden, Instanzen erkannter Objekte zu zählen oder die Größe eines Objekts mit Begrenzungsrahmen-Dimensionen zu messen.
Zum Beispiel kann Amazon Rekognition Image im folgenden Bild die Anwesenheit einer Person, eines Skateboards, geparkter Autos und andere Informationen erkennen. Amazon Rekognition Image gibt auch den Begrenzungsrahmen für eine erkannte Person und andere erkannte Objekte wie Autos und Räder zurück.

Zuverlässigkeitswert
Amazon Rekognition Video und Amazon Rekognition Image geben in Prozent an, wie viel Zuverlässigkeit Amazon Rekognition in die Richtigkeit jedes erkannten Labels hat.
Übergeordnete Kategorien
Amazon Rekognition Image und Amazon Rekognition Video verwenden eine hierarchische Taxonomie von Ahnen-Labels, um Label zu kategorisieren. Beispiel: Eine Person, die eine Straße überquert, könnte als Fußgänger erkannt werden. Das übergeordnete Label für Fußgänger ist Person. Beide diese Labels werden in der Antwort zurückgegeben. Alle Vorgängerlabels werden zurückgegeben. Jedes Label enthält eine Liste der übergeordneten Labels und andere Vorgängerlabels. Beispiel: Großeltern- und Urgroßeltern-Labels, sofern vorhanden. Sie können die übergeordneten Labels zum Erstellen von Gruppen zusammengehöriger Labels verwenden, und um Abfragen ähnlicher Labels in einem oder mehreren Bildern zuzulassen. Beispiel: Eine Abfrage für alle Fahrzeuge könnte ein Auto von einem Bild und ein Motorrad von einem anderen zurückgeben.
Kategorien
Amazon Rekognition Image und Amazon Rekognition Video geben Informationen zu Labelkategorien zurück. Label sind Teil von Kategorien, in denen einzelne Label auf der Grundlage gemeinsamer Funktionen und Kontexte gruppiert werden, z. B. „Fahrzeuge und Autos“ und „Lebensmittel und Getränke“. Eine Labelkategorie kann eine Unterkategorie einer übergeordneten Kategorie sein.
Aliasnamen
Amazon Rekognition Image und Amazon Rekognition Video senden nicht nur Label sondern geben auch alle Aliase zurück, die mit dem Label verknüpft sind. Aliase sind Label mit derselben Bedeutung oder Label, die visuell mit dem zurückgesandten Hauptlabel austauschbar sind. Beispielsweise ist „Handy“ ein Alias für „Mobiltelefon“.
In früheren Versionen gab Amazon Rekognition Image Aliase wie „Handy“ in derselben Liste von Hauptlabelnamen zurück, die „Mobiltelefon“ enthielten. Amazon Rekognition Image gibt jetzt „Handy“ in einem Feld mit dem Namen „Aliase“ und „Mobiltelefon“ in der Liste der Hauptlabelnamen zurück. Wenn Ihre Anwendung auf den Strukturen basiert, die von einer früheren Version von Rekognition zurückgegeben wurden, müssen Sie möglicherweise die aktuelle Antwort, die von den Bild- oder Videolabelerkennungsoperationen zurückgegeben wurde, in die vorherige Antwortstruktur umwandeln, in der alle Label und Aliase als Hauptlabel zurückgegeben werden.
Wenn Sie die aktuelle Antwort von der DetectLabels API (für die Erkennung von Etiketten in Bildern) in die vorherige Antwortstruktur umwandeln müssen, finden Sie das Codebeispiel unter. Transformation der DetectLabels Antwort
Wenn Sie die aktuelle Antwort von der GetLabelDetection API (zur Erkennung von Bezeichnungen in gespeicherten Videos) in die vorherige Antwortstruktur umwandeln müssen, finden Sie das Codebeispiel unterTransformation der Antwort GetLabelDetection .
Bildeigenschaften
Amazon Rekognition Image gibt Informationen zur Bildqualität (Schärfe, Helligkeit und Kontrast) für das gesamte Bild zurück. Schärfe und Helligkeit werden auch für den Vordergrund und den Hintergrund des Bildes zurückgegeben. Bildeigenschaften können auch verwendet werden, um dominante Farben des gesamten Bildes, des Vordergrunds, des Hintergrunds und von Objekten mit Begrenzungsrahmen zu erkennen.

Das Folgende ist ein Beispiel für die ImageProperties Daten, die in der Antwort auf eine DetectLabels Operation für das nachfolgende Bild enthalten sind:
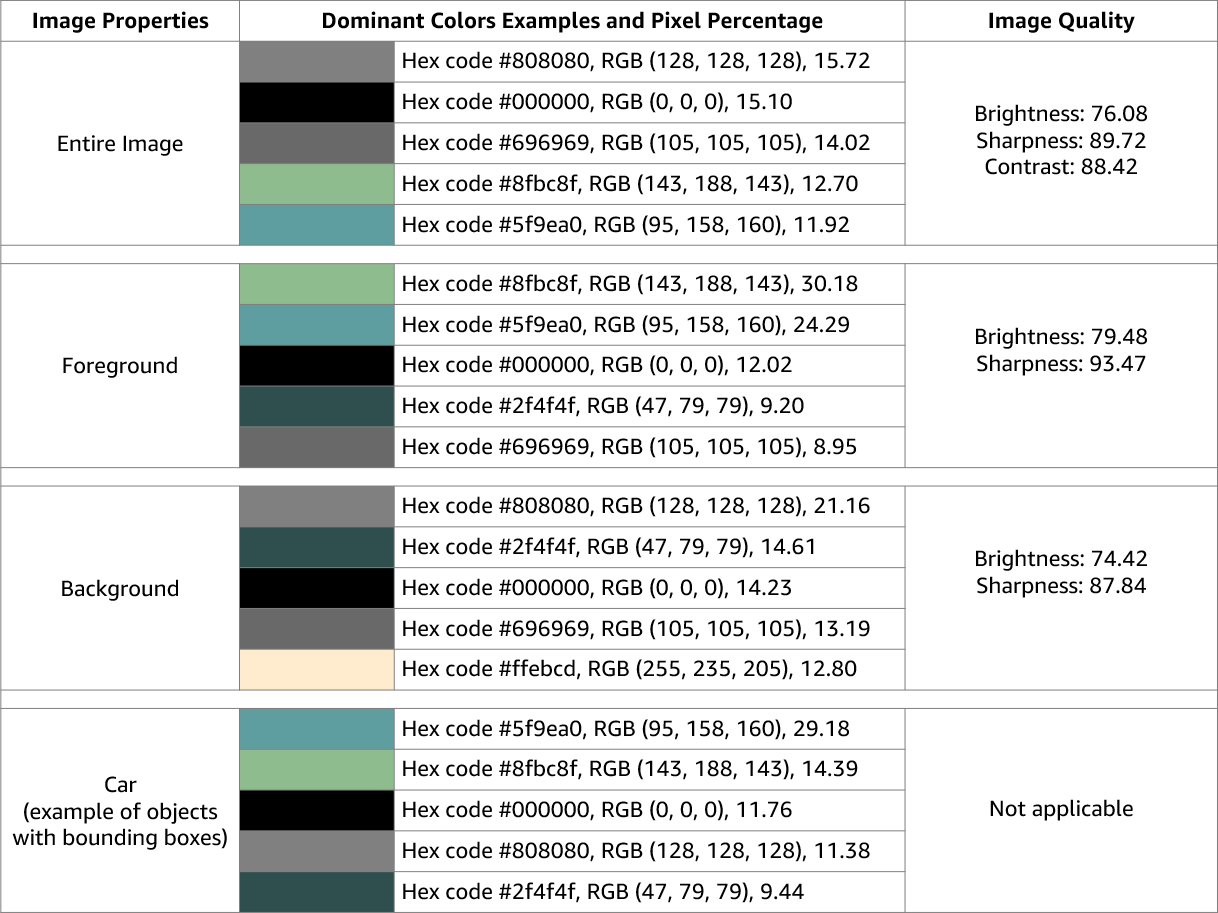
Bildeigenschaften sind für Amazon Rekognition Video nicht verfügbar.
Modellversion
Amazon Rekognition Image und Amazon Rekognition Video geben beide die Version des Label-Erkennungsmodells zurück, mit dem Labels in einem Bild oder einem gespeicherten Video erkannt wurden.
Einschluss- und Ausschlussfilter
Sie können die Ergebnisse filtern, die von Amazon-Rekognition-Image- und Amazon-Rekognition-Video-Labelerkennungsoperationen zurückgegeben werden. Filtern Sie die Ergebnisse, indem Sie Filterkriterien für Label und Kategorien angeben. Labelfilter können inklusiv oder exklusiv sein.
Weitere Informationen zur Filterung der mit DetectLabels erzielten Ergebnisse finden Sie unter Erkennen von Labels in einem Bild.
Weitere Informationen zur Filterung der durch GetLabelDetection erzielten Ergebnisse finden Sie unter Erkennen von Labels in einem Video.
Ergebnisse sortieren und aggregieren
Die Ergebnisse bestimmter Amazon-Rekognition-Video-Operationen können nach Zeitstempeln und Videosegmenten sortiert und aggregiert werden. Beim Abrufen der Ergebnisse eines Auftrags zur Labelerkennung oder Inhaltsmoderation können Sie mit GetLabelDetection bzw. GetContentModeration die SortBy- und AggregateBy-Argumente verwenden, um anzugeben, wie Ihre Ergebnisse zurückgegeben werden sollen. Sie können SortBy mit TIMESTAMP oder NAME (Labelnamen) und TIMESTAMPS oder SEGMENTS mit dem AggregateBy Argument verwenden.
