Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwenden eines benutzerdefinierten Sprachmodells
Sobald Sie Ihr benutzerdefiniertes Sprachmodell erstellt haben, können Sie es in Ihre Transkriptionsanfragen einbeziehen. Beispiele finden Sie in den folgenden Abschnitten.
Die Sprache des Modells, das Sie in Ihre Anforderung aufnehmen, muss mit dem Sprachcode übereinstimmen, den Sie für Ihre Medien angeben. Wenn die Sprachen nicht übereinstimmen, wird Ihr benutzerdefiniertes Sprachmodell nicht auf Ihre Transkription angewendet und es gibt keine Warnungen oder Fehler.
Verwenden eines benutzerdefinierten Sprachmodells in einer Batch-Transkription
Beispiele für die Verwendung eines benutzerdefinierten Sprachmodells mit einer Batch-Transkription finden Sie im Folgenden:
-
Melden Sie sich an der AWS Management Console
an. -
Wählen Sie im Navigationsbereich Transkriptionsaufträge und dann Auftrag erstellen (oben rechts). Dies öffnet die Seite Auftragsdetails angeben.
-
Markieren Sie im Bereich Auftragseinstellungen unter Modelltyp das Feld Benutzerdefiniertes Sprachmodell.
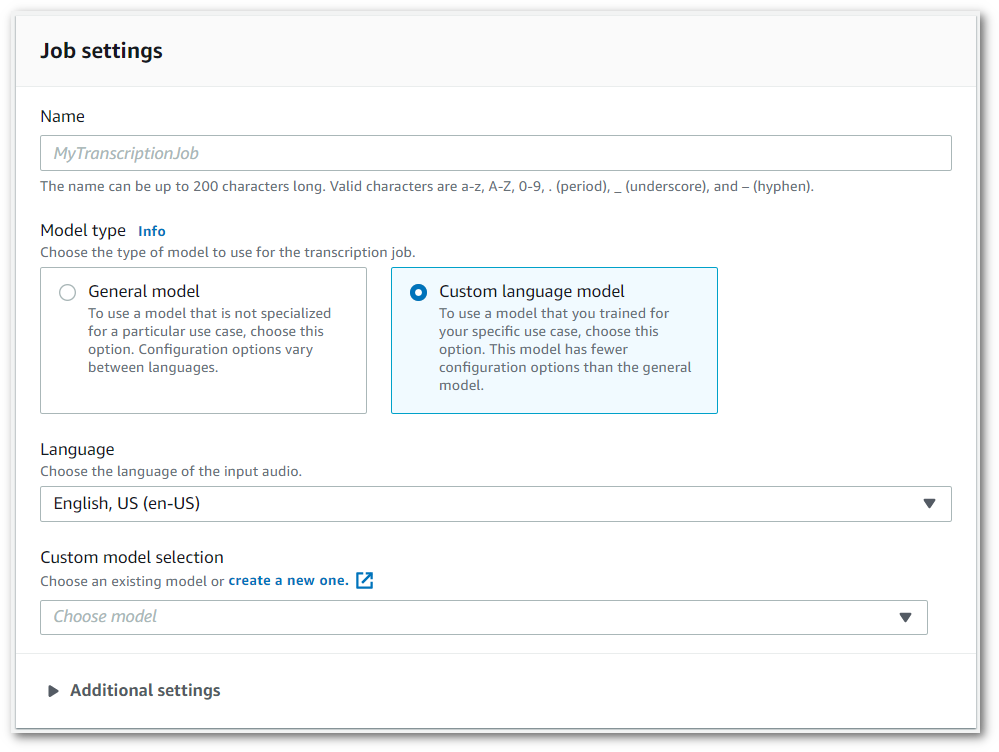
Sie müssen auch eine Eingabesprache aus dem Dropdown-Menü auswählen.
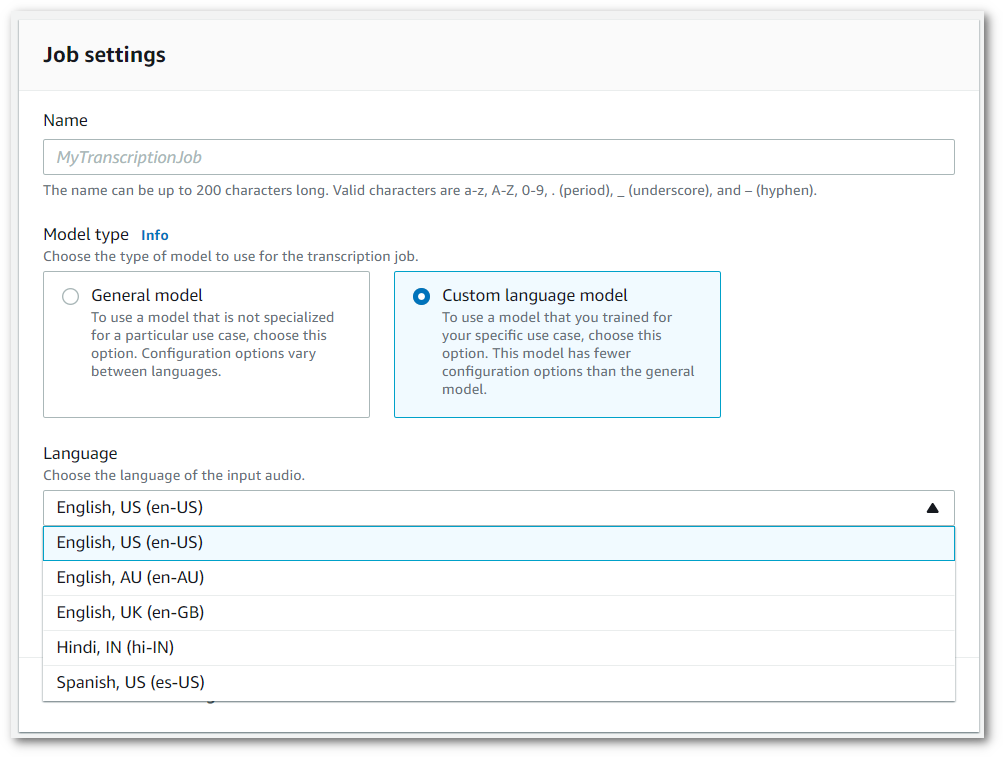
-
Wählen Sie unter Auswahl des benutzerdefinierten Modells ein vorhandenes benutzerdefiniertes Sprachmodell aus dem Dropdown-Menü aus oder erstellen Sie ein neues Modell.
Fügen Sie den Amazon S3 Speicherort Ihrer Eingabedatei im Eingabedatenbereich hinzu.
-
Wählen Sie Weiter für weitere Konfigurationsoptionen.
Wählen Sie Auftrag erstellen, um Ihren Transkriptionsauftrag auszuführen.
In diesem Beispiel werden der start-transcription-jobModelSettings Parameter mit dem VocabularyName Unterparameter verwendet. Weitere Informationen erhalten Sie unter StartTranscriptionJob und ModelSettings.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --language-codeen-US\ --model-settings LanguageModelName=my-first-language-model
Hier ist ein weiteres Beispiel, in dem der start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://my-first-model-job.json
Die Datei my-first-model-job.json enthält den folgenden Anfragetext.
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputBucketName": "amzn-s3-demo-bucket", "OutputKey": "my-output-files/", "LanguageCode": "en-US", "ModelSettings": { "LanguageModelName": "my-first-language-model" } }
In diesem Beispiel wird mithilfe des AWS SDK für Python (Boto3) ModelSettings Arguments für die Methode start_transcription_jobStartTranscriptionJob und ModelSettings.
Weitere Beispiele für die Verwendung der AWS SDKs, einschließlich funktionsspezifischer, szenarienspezifischer und serviceübergreifender Beispiele, finden Sie im Kapitel. Codebeispiele für Amazon Transcribe mit AWS SDKs
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-transcription-job" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'amzn-s3-demo-bucket', OutputKey = 'my-output-files/', LanguageCode = 'en-US', ModelSettings = { 'LanguageModelName': 'my-first-language-model' } ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
Verwenden eines benutzerdefinierten Sprachmodells in einer Streaming-Transkription
Beispiele für die Verwendung eines benutzerdefinierten Sprachmodells mit einer Streaming-Transkription finden Sie im Folgenden:
-
Melden Sie sich beim AWS Management Console
an. -
Wählen Sie im Navigationsbereich Echtzeit-Streaming aus. Blättern Sie nach unten zu Anpassungen und erweitern Sie dieses Feld, falls es minimiert ist.
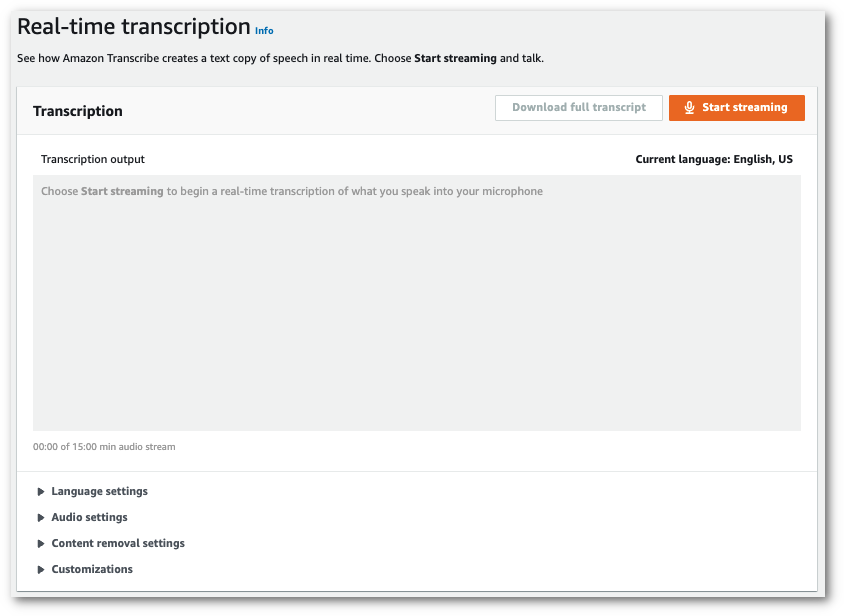
-
Aktivieren Sie die Option Benutzerdefiniertes Sprachmodell und wählen Sie ein Modell aus dem Dropdown-Menü.
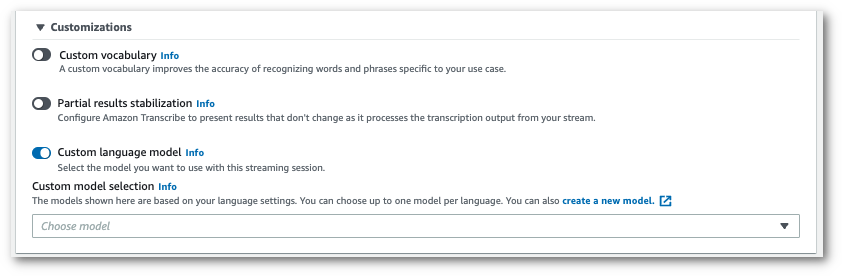
Fügen Sie alle anderen Einstellungen hinzu, die Sie auf Ihren Stream anwenden möchten.
-
Jetzt können Sie Ihren Stream transkribieren. Wählen Sie Streaming starten und beginnen Sie zu sprechen. Um Ihr Diktat zu beenden, wählen Sie Streaming beenden.
In diesem Beispiel wird eine HTTP/2-Anfrage erstellt, die Ihr benutzerdefiniertes Sprachmodell enthält. Weitere Informationen zur Verwendung von HTTP/2-Streaming mit finden Sie Amazon Transcribe unter. Einrichten eines HTTP/2-Streams Weitere Informationen zu spezifischen Parametern und Headern finden Sie Amazon Transcribe unter. StartStreamTranscription
POST /stream-transcription HTTP/2 host: transcribestreaming.us-west-2.amazonaws.com X-Amz-Target: com.amazonaws.transcribe.Transcribe.StartStreamTranscriptionContent-Type: application/vnd.amazon.eventstream X-Amz-Content-Sha256:stringX-Amz-Date:20220208T235959Z Authorization: AWS4-HMAC-SHA256 Credential=access-key/20220208/us-west-2/transcribe/aws4_request, SignedHeaders=content-type;host;x-amz-content-sha256;x-amz-date;x-amz-target;x-amz-security-token, Signature=stringx-amzn-transcribe-language-code:en-USx-amzn-transcribe-media-encoding:flacx-amzn-transcribe-sample-rate:16000x-amzn-transcribe-language-model-name:my-first-language-modeltransfer-encoding: chunked
Parameterdefinitionen finden Sie in der API-Referenz. Parameter, die allen AWS API-Vorgängen gemeinsam sind, sind im Abschnitt Allgemeine Parameter aufgeführt.
In diesem Beispiel wird eine vorsignierte URL erstellt, die Ihr benutzerdefiniertes Sprachmodell auf einen WebSocket Stream anwendet. Für eine bessere Lesbarkeit werden Zeilenumbrüche hinzugefügt. Weitere Informationen zur Verwendung von WebSocket Streams mit finden Sie Amazon Transcribe unterEinen WebSocket Stream einrichten. Weitere Einzelheiten zu den Parametern finden Sie unter StartStreamTranscription.
GET wss://transcribestreaming.us-west-2.amazonaws.com:8443/stream-transcription-websocket? &X-Amz-Algorithm=AWS4-HMAC-SHA256 &X-Amz-Credential=AKIAIOSFODNN7EXAMPLE%2F20220208%2Fus-west-2%2Ftranscribe%2Faws4_request &X-Amz-Date=20220208T235959Z &X-Amz-Expires=300&X-Amz-Security-Token=security-token&X-Amz-Signature=string&X-Amz-SignedHeaders=content-type%3Bhost%3Bx-amz-date &language-code=en-US&media-encoding=flac&sample-rate=16000&language-model-name=my-first-language-model
Parameterdefinitionen finden Sie in der API-Referenz. Parameter, die allen AWS API-Vorgängen gemeinsam sind, sind im Abschnitt Allgemeine Parameter aufgeführt.
