Insurance lake
The insurance data lake provides a method for aggregating end user customer data from a large number of diverse sources, including core systems and third parties, and consolidating it within a single, secure location. The four Cs provide a best practice data lake pattern for creation of your insurance data lake:
-
Collect: Store all of your data in Amazon S3.
-
Cleanse and curate: Validate, map, transform, and log the actions performed on your data.
-
Consume: Derive insights from your data.
-
Comply and secure: Automate your audit and regulatory compliance requirements and secure your data.
Reference architecture
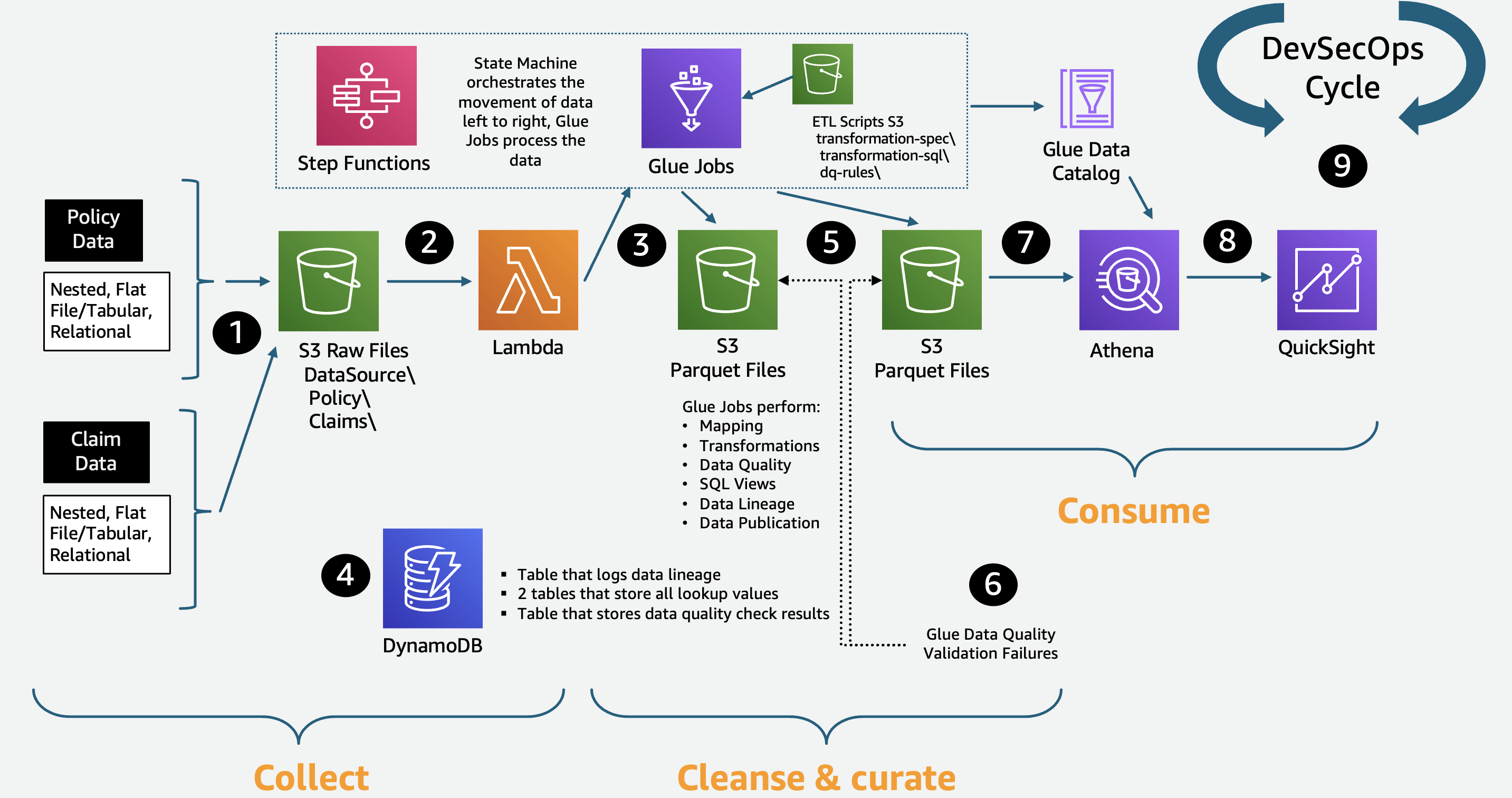
Figure 6: Insurance data lake reference architecture
Architecture description
-
Source data file is dropped into the Collect S3 bucket. Mapping file, transform file, and data quality file are present in the ETL-Scripts S3 bucket .
-
Put Event automatically initiates a Lambda function that reads metadata from the incoming source data, logs all actions, handles any errors, and starts the AWS Step Functions workflow.
-
Step Functions calls PySpark AWS Glue jobs that map the data to your pre-defined data dictionary and perform the transformations and data quality checks for both the Cleanse and Consume layers.
-
Amazon DynamoDB contains lookup values for each source data file as needed by the
lookupandmultilookuptransforms. ETL metadata, such as job audit logs, data lineage output logs, and data quality results, are written here. -
Cleansed and curated data is then written to compressed, partitioned Apache Parquet files in the PySpark code. The PySpark code also creates and updates AWS Glue Data Catalog databases and tables defined by your data dictionary.
-
Source data file validation failures are sent to an S3 Quarantine folder and Data Catalog table, which can populate an exception queue dashboard where a human can review and take appropriate action.
-
SQL queries can be written using the AWS Glue databases and tables.
-
QuickSight dashboards and reports can pull data from the insurance lake on a real-time or scheduled basis.
-
Full DevSecOps (everything as code and everything as automated as possible) can be managed using AWS CodePipeline and related services.
