This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Storage and data sharing
In HPC systems, there are two primary data distribution challenges. The first is the distribution of binaries. In financial services, large and complex analytical packages are common. These packages are often 1GB or more in size, and often multiple versions are in use at the same time on the same HPC platform, to support different businesses or back-testing of new models.
In a constrained, on-premises environment, you can mitigate this challenge through relatively infrequent updates to the package and a fixed set of instances. However, in a cloud-based environment, instances are short-lived and the number of instances can be much larger. As a result, multiple packages may be distributed to thousands of instances on an hourly basis as new instances are provisioned and new packages are deployed.
There are a number of possible approaches to this problem. One is to maintain a build
pipeline that incorporates binary packages into the Amazon Machine Images (AMIs). This means
that once the machine has started, it can process a workload immediately because the packages
are already in place. The EC2 Image Builder
Another approach is to update running instances. There are two different methods for this type of update, which are sometimes combined:
-
Pull (or lazy) deployment — In this mode, when a task reaches an instance and it depends on a package that is not in place, the engine pulls it from a central store before it runs the task. This approach minimizes the distribution of packages and saves on local storage because only the minimum set of packages is deployed. However, these benefits are at the expense of delaying tasks in an unpredictable way, such as the introduction of a new instance in the middle of a latency sensitive pricing job. This approach may not be acceptable if large volumes of tasks have to wait for the grid nodes to pull packages from a central store which could struggle to service very large numbers of requests for data.
-
Push deployment — In this mode you can instruct instance engines to proactively get a specific package before they receive a task that depends on it. This approach allows for rolling upgrades and ensures tasks are not delayed by a package update. One challenge with this method is the possibility that new instances (which can be added at any time) might miss a push message, which means you must keep a list of all currently live packages.
In practice, a combination of these approaches is common. Standard analytics packages are pushed because they’re likely to be needed by the majority of tasks. Experimental packages or incremental ‘Delta’ releases are then pulled, perhaps to a smaller set of instances.
It might also be necessary to purge deprecated packages, especially if you deploy experimental packages. In this case, you can use a list of live packages to enable your compute instances to purge any packages that are not in the list and thus are not current.
The following figure shows a cloud-native implementation of these approaches. It uses a
centralized package store in Amazon Simple Storage Service
After the package is in place on Amazon S3, notifications of new releases can be generated either by an operator or as a final step in an automated build pipeline. Compute instances subscribed to an SNS topic (or to multiple topics for different applications) use these messages as a trigger to retrieve packages from Amazon S3. You can also use the same mechanism to distribute delete messages to remove packages, if required.
Note that in some cases it might be possible to pull binaries on-demand from Amazon S3
by using MountPoint for Amazon S3
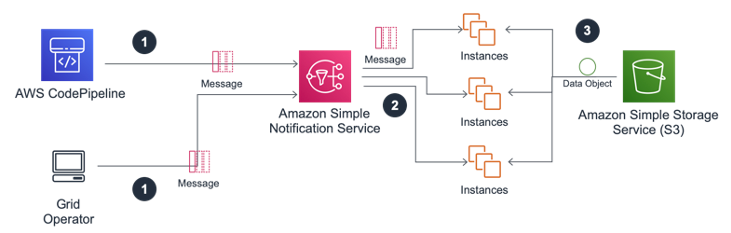
Data distribution architecture using Amazon SNS messages and S3 Object Storage
The second data distribution challenge in HPC is managing data related to the tasks being processed. Typically, this is bi-directional, with data flowing to the engines that support the processing and resulting data passed back to the clients. There are three common approaches for this process:
-
In the first approach, communications are inbound (see the following figure) with all data passing through the grid scheduler along with task data. This is less common because it can cause a performance bottleneck as the cluster grows.

An inbound data distribution approach
-
In another approach, tasks pass through the scheduler, but the data is handled out-of-bounds through a shared, scalable data store or an in-memory data grid (see the following figure). The task data contains a reference to the data’s location and the compute instances can retrieve it as required.
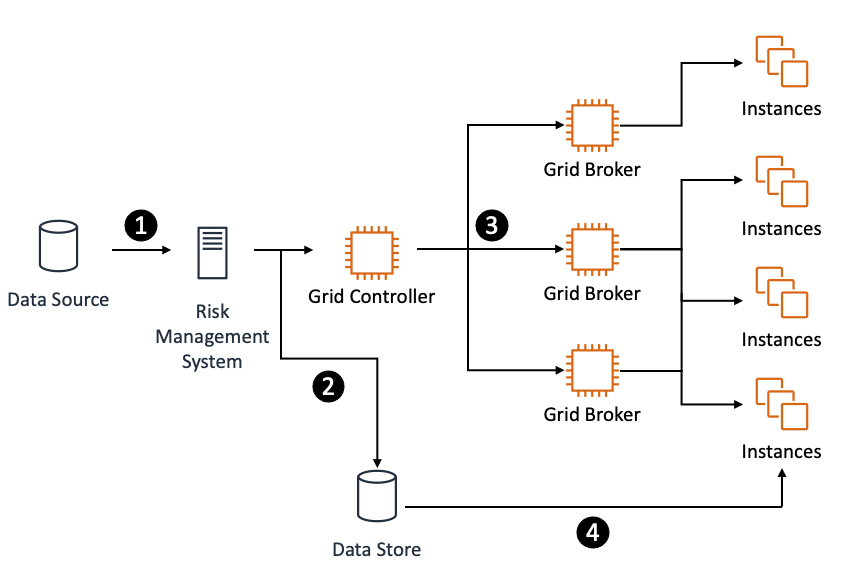
An out-of-bounds data distribution approach
-
Finally, some schedulers support a direct data transfer (DDT) approach. In this model the scheduler grid broker allocates compute instances which then communicate directly with the client. This architecture can work well, especially with very short running tasks with little data. However, in a hybrid model, with thousands of engines running on AWS that need to access a single, on-premises client, this can present challenges to on-premises firewall rules, or to the availability of ephemeral ports on the client host.
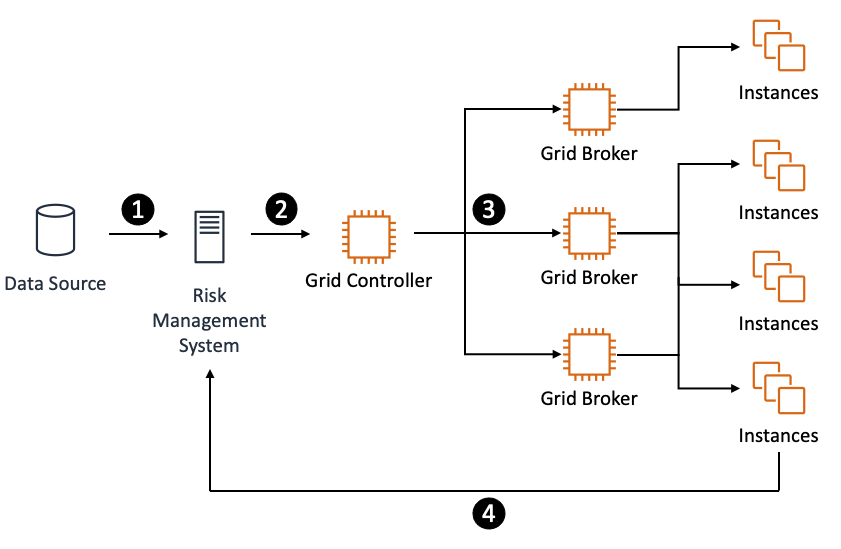
DDT (direct data transfer) data distribution approach
All of these approaches can be enhanced with caches located as close as possible to, or hosted on, the compute instances. Such caches help to minimize the distribution of data, especially if a significantly similar set is required for many calculations. Some schedulers support a form of data-aware scheduling that tries to ensure that tasks that require a specific dataset are scheduled to instances that already have that dataset. This cannot be guaranteed, but often provides a significant performance improvement at the cost of local memory or storage on each compute instance.
Though the combination of grid schedulers and distributed cache technologies used on premises can provide solutions to these challenges, their capabilities vary and they are not typically engineered for a cloud deployment with highly elastic, ephemeral instances. You can consider the following AWS services as potential solutions to the typical HPC data management use cases.
Amazon Simple Storage Service (Amazon S3)
The Amazon S3
Binary immutability is a common audit requirement in regulated industries, which require you to demonstrate that the binaries approved in the testing phase are identical to those used to produce reports. You can include this feature in your deployment pipeline to make sure that the analytics binaries you use in production are the same as those that you validated. This service also offers easy to implement encryption and granular access controls.
Some HPC architectures use checkpointing (compute instances save a snapshot of their current state to a datastore) to minimize the computational effort that could be lost if a node fails or is interrupted during processing. For this purpose, a distributed object store (such as Amazon S3) might be an ideal solution. Because the data is likely to only be needed for the life of the batch, you can use S3 life cycling rules to automatically purge these objects after a small number of days to reduce costs.
For HPC systems that require access to a shared POSIX filesystem,
Mountpoint for Amazon S3open and read.
The combination of Mountpoint and Amazon S3 allows many clients to read objects at once.
Amazon Elastic File System (Amazon EFS)
Amazon EFS offers shared
network storage that is elastic, which means it grows and shrinks as required. Thousands of
Amazon EC2
Amazon FSx for Windows File Server
Amazon FSx for Windows File Server
Amazon FSx for Lustre
For transient job data, the Amazon FSx for
Lustre
FSx for Lustre is ideal for HPC workloads because it provides a file system that’s optimized for the performance and costs of high-performance workloads, with file system access across thousands of EC2 instances.

An example of an Amazon FSx for Lustre implementation
Amazon FSx for NetApp ONTAP
Amazon FSx for NetApp ONTAP is a storage service that allows you to launch and run fully managed NetApp ONTAP file systems in the AWS Cloud. To support HPC use-cases it provides multiple GB/s of throughput and hundreds of thousands of IOPS per filesystem with consistent sub-millisecond latencies on SSD-based storage.
Amazon Elastic Block Store (Amazon EBS)
After a compute instance has binary or job data, it might not be possible to keep it in
memory, so you might want to keep a copy on a local disk. Amazon EBS
Though the volumes for compute nodes can be relatively small (10GB can be sufficient to store a variety of binary package versions and some job data) there might be some benefit to the higher IOPS and throughput offered by the Amazon EBS-provisioned input/output operations per second (IOPS) solid state drives (SSDs). These offer up to 64,000 IOPS per volume and up to 1,000MB/s of throughout, which can be valuable for workloads that require frequent, high-performance access to these datasets.
Because these volumes incur additional cost, you should complete an analysis of whether they provide any additional value over the standard, general-purpose volumes.
AWS Cloud hosted data providers
AWS Data Exchange
The Bloomberg Market Data Feed
(B-PIPE)
Additionally, Refinitiv’s Elektron Data
Platform
