This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Task scheduling and infrastructure orchestration
A high-performance computing system needs to achieve two goals:
-
Scheduling — Encompasses the lifecycle of compute tasks including: capturing and prioritizing tasks, allocating them to the appropriate compute resources, and handling failures.
-
Orchestration — Making compute capacity available to satisfy those demands.
It’s common for financial services organizations to use a third-party grid scheduler to coordinate HPC workloads, but orchestration is often a slow-moving exercise in procurement and physical infrastructure provisioning. Traditional schedulers are therefore highly optimized for making low-latency scheduling decisions to maximize usage of a relatively fixed set of resources.
As customers migrate to the cloud, the dynamics of the problem changes. Instead of near-static resource orchestration, capacity can be scaled to meet the demands at that instant. As a result, the scheduler doesn’t need to reason about which task to schedule next but rather just inform the orchestrator that additional capacity is needed.
Table 2 — Task scheduling and infrastructure orchestration approaches
| HPC hosting | Task scheduling approach | Infrastructure orchestration approach |
|---|---|---|
| On-Premises | Rapid task scheduling decisions to manage prioritization and maximize utilization while minimizing queue times. | Static, a procurement and physical provisioning process run over weeks or months. |
| Cloud based | Focus on managing the task lifecycle, decisions around prioritization and queue times are minimized by dynamic orchestration. | Highly dynamic, capacity on-demand with ‘pay as you go’ pricing. Optimized for cost and performance through selection of instance type and procurement model. |
When you plan a migration, a valid option is to migrate the on-premises solution first, and then consider optimizations. For example, an initial ‘lift and shift’ implementation might use Amazon EC2 On-Demand Instances to provision capacity, which yields some immediate benefits from elasticity. Some of the commercial schedulers also have integrations with AWS, which enable them to add and remove nodes according to demand.
When you are comfortable with running critical workloads on AWS, you can further optimize your implementation with options such as using more native services for data management, capacity provisioning, and orchestration. Ultimately, the scheduler might be in scope for replacement, at which point you can consider a few different approaches.
Though financial services workloads are often composed of very large volumes of
relatively short-running calculations, there are some cases where longer-running calculations
need to be scheduled. In these situations, AWS Batch
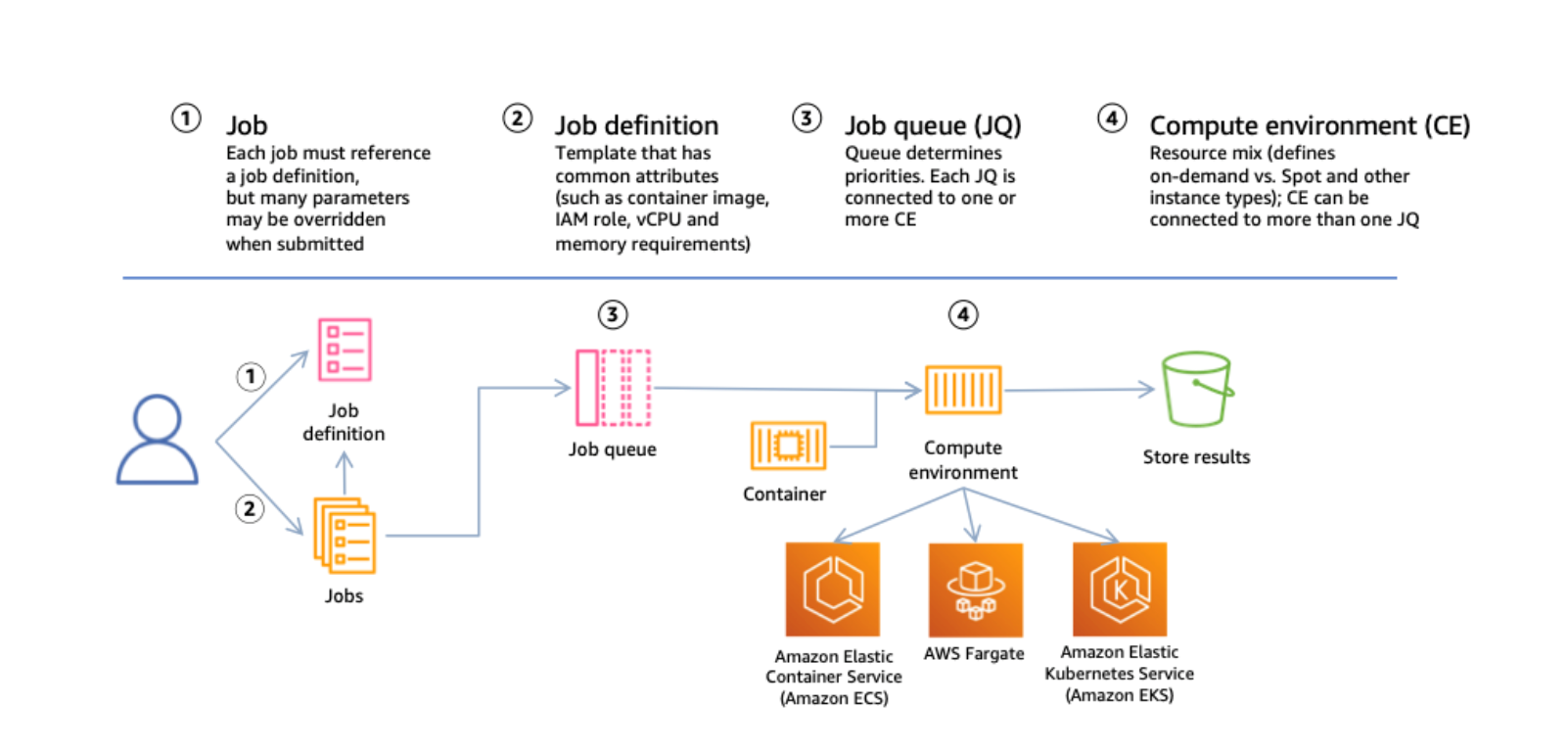
AWS Batch overview
AWS Batch decouples and templates the definition of jobs and submission into queues. Jobs are then run in compute environments linked to the queues. AWS Batch supports Amazon ECS, Fargate, and Amazon EKS as compute environments.
Customers looking to simplify their architecture might consider a queue-based
architecture in which clients submit tasks to a stateful queue. This can then be serviced by
an elastic group of hungry worker processes that take pending workloads,
process them, and then return results. The Amazon SQS
A simple HPC approach with Amazon SQS and Amazon EC2
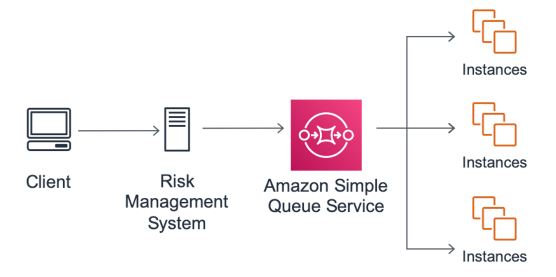
A simple HPC approach with Amazon SQS
Amazon SQS queues can be serviced by groups of Amazon EC2 instances that are managed by AWS Auto Scaling groups. You can configure the AWS Auto Scaling groups to scale capacity up or down based on metrics such as average CPU load, or the depth of the queue. AWS Auto Scaling groups can also incorporate provisioning strategies that can combine Amazon EC2 On-Demand Instances or Spot Instances to provide flexible and low-cost capacity.
A simple HPC approach with Amazon SQS and Lambda
With serverless queuing provided by Amazon SQS, it’s logical to think about serverless compute
capacity. With AWS Lambda
You can also configure Lambda to process workloads from SQS, scaling out horizontally to consume messages in a queue. Lambda attempts to process the items from the queue as quickly as possible, and is constrained only by the maximum concurrency allowed by the account, memory, and runtime limits. You can also allocate up to 10GB of memory and six vCPUs to your functions, which also have support for the AVX2 instruction set. This makes Lambda functions suitable for a wide range of HPC applications.
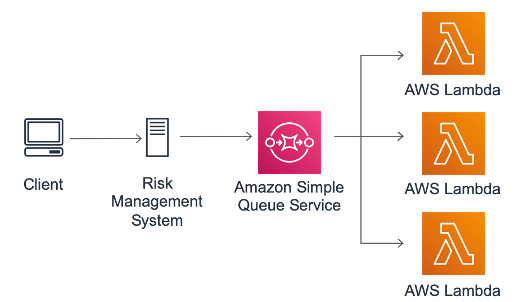
A serverless, event-driven approach to HPC
A serverless, event-driven approach to HPC

A cloud-native serverless scheduler architecture
Some FSI customers choose to relay on the existing container orchestration platforms such as Amazon ECS and Amazon EKS for their grid systems. These are fully managed AWS solutions that provide scalability, availability, load balancing, and integration with other AWS services. Both Amazon ECS and Amazon EKS have a concept of tasks (or jobs in EKS) which represent a unit of compute; in other words, a task can be submitted to a cluster, which in turn will deploy a container that will do the computation and will end the container when the task is completed.
Unfortunately, this approach does not work very well with the high volume of short running tasks, which is common for financial services. For example, when the duration of the computation is only one second, it is unacceptably wasteful to spend a few more seconds just to deploy a container to do the task. Moreover, some FSI workloads rely on computational context or state which can take time to be established at the first invocation of a container. Thus, sending tasks directly “as is” to ECS or EKS clusters does not always fit well into FSI workload characteristics.
Therefore, some FSI customers are looking into implementing their own pull-based mechanisms where a worker container persists between consecutive task computations; in other words, a worker container is created once and persists until there are no more tasks to compute. This requires implementing an additional layer to do the state management of each task.
Taking these concepts further, the blog Cloud-native,
high throughput grid computing using the HTC-Grid
solution
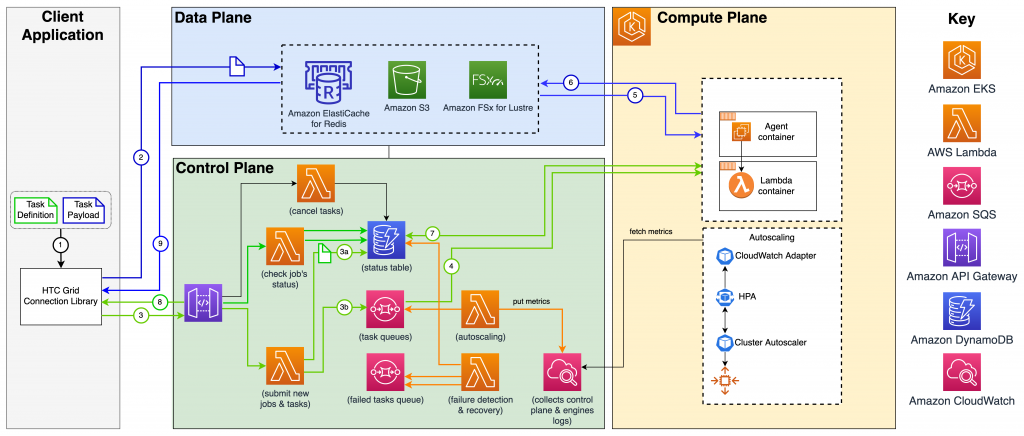
When you explore these alternative cloud-native approaches, especially in comparison to established schedulers, it’s important to consider all of the features required to run what can be a critical system. Metrics gathering, data management, and management tooling are only some of the typical requirements that must be addressed and should not be overlooked.
A key benefit of running HPC workloads on AWS is the flexibility of the offerings that enable you to combine various solutions to meet very specific needs. An HPC architect can use Amazon EC2 Savings Plans for long-running, stateful hosts. You can use Amazon EC2 On-Demand Instances for long-running tasks, or to secure capacity at the start of a batch. Additionally, you can provision Amazon EC2 Spot Instances to try to deliver a batch more quickly and at lower cost. Some workloads can then be directed to alternative platforms, such as GPU enabled instances or Lambda functions. You can optimize the overall mix of these options on a regular basis to adapt to the changing needs of your business.
