Schritt 4: Predicators auswerten
Ein typischer Machine-Learning-Workflow besteht darin, eine Reihe von Modellen oder eine Kombination von Modellen mithilfe eines Trainingssatzes zu trainieren und deren Genauigkeit anhand eines Hold-Out-Datensatzes zu bewerten. In diesem Abschnitt wird erläutert, wie historische Daten aufgeteilt und welche Metriken in der Zeitreihenprognose verwendet werden, um Modelle zu bewerten. Die Technik des Backtesting dient als Hauptinstrument zur Bewertung der Prognosegenauigkeit.
Backtesting
Ein adäquates Evaluierungs- und Backtesting-Framework stellt eines der zentralen Elemente bei der Erstellung einer erfolgreichen Machine-Learning-Anwendung dar. Ein erfolgreiches Backtesting Ihrer Modelle ist die Grundlage dafür, um Vertrauen in die zukünftige Vorhersagekraft der Modelle zu gewinnen. Darüber hinaus können Sie die Hyperparameteroptimierung (HPO) nutzen, um Modelle zu optimieren, zu lernen, wie Modelle miteinander kombiniert werden, und um Meta-Learning und AutoML zu aktivieren.
Im Vergleich zu anderen Bereichen des angewandten Machine Learning stellt das Merkmal der Zeitreihenprognose Zeit ein wesentliches Unterscheidungsmerkmal in Bezug auf die Bewertungs- und Backtesting-Methode dar. Um einen Prognosefehler in einem Backtest zu evaluiieren, teilen Sie bei ML-Aufgaben in der Regel einen Datensatz nach Elementen auf. Für die Kreuzvalidierung im Rahmen bildrelevanter Aufgaben trainieren Sie beispielsweise anhand eines bestimmten Prozentsatzes der Bilder. Anschließend verwenden Sie zum Testen und Validieren andere Teile. Bei Prognosen müssen Sie in erster Linie nach dem Faktor Zeit (und in geringerem Maße nach Elementen) aufteilen, um sicherzustellen, dass in den Test- oder Validierungssatz keine Informationen aus dem Trainingssatz gelangen und dass Sie den Produktionsfall so genau wie möglich simulieren.
Die Aufteilung nach Zeit muss sorgfältig erfolgen, da Sie nicht einen einzelnen Zeitpunkt sondern mehrere Zeitpunkte auswählen wollen. Andernfalls hängt die Genauigkeit zu stark vom Prognosestartdatum ab, das durch den Trennpunkt definiert wird. Eine fortlaufende Prognoseauswertung, bei der Sie mehrere Aufteilungen über mehrere Zeitpunkte hinweg durchführen und das Durchschnittsergebnis ausgeben, liefert robustere und zuverlässigere Backtest-Ergebnisse. Die folgende Abbildung zeigt vier verschiedene Backtest-Aufteilungen.

Abbildung, die vier verschiedene Backtesting-Szenarien mit zunehmender Trainingssatzgröße, jedoch konstanter Testgröße darstellt
In der vorherigen Abbildung stehen für alle Backtesting-Szenarien alle Daten zur Verfügung. Das ermöglicht das Abgleichen der prognostizierten Werte mit den tatsächlichen Werten.
Da die meisten Zeitreihen in der realen Welt normalerweise nicht stationär sind, bedarf es mehrerer Backtest-Fenster. Das E-Commerce-Geschäft aus der Fallstudie hat seinen Sitz in Nordamerika. Es verzeichnet die höchste Produktnachfrage im vierten Quartal, mit besonderen Bedarfsspitzen um Thanksgiving herum und vor Weihnachten. In der Einkaufssaison im vierten Quartal ist die Variabilität der Zeitreihen höher als während des restlichen Jahres. Mithilfe mehrerer Backtest-Fenster können Sie Prognosemodelle in einer ausgewogeneren Umgebung evaluieren.
Die folgende Abbildung zeigt für jedes Backtest-Szenario die grundlegenden Elemente der Terminologie von Amazon Forecast. Amazon Forecast teilt Daten automatisch in Trainings- und Test-Datasets auf. Amazon Forecast entscheidet, wie die Eingabedaten aufgeteilt werden. Hierzu verwendet das Tool den BackTestWindowOffset-Parameter, der als Parameter in dercreate_predictor-API angegeben ist oder seinenForecastHorizon-Standardwert.
In der folgenden Abbildung sehen Sie den ersten allgemeineren Fall, in dem dieForecastHorizon-Parameter und die BackTestWindowOffset-Parameter nicht identisch sind. DerBackTestWindowOffset-Parameter definiert das Startdatum einer virtuellen Prognose, das in der folgenden Abbildung als gestrichelte vertikale Linie dargestellt wird. Es kann dazu verwendet werden, um die folgende hypothetische Frage zu beantworten: Wenn das Modell an diesem Tag eingesetzt würde, wie würde dann die Prognose aussehen? DerForecastHorizon definiert die Anzahl der vorherzusagenden Zeitschritte vom Startdatum der virtuellen Prognose.
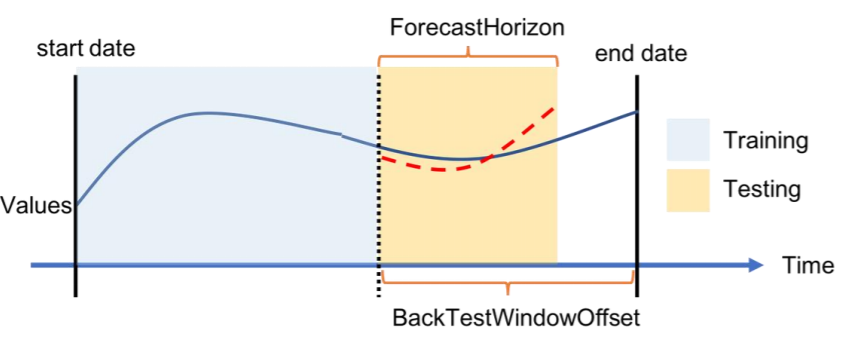
Abbildung eines einzelnen Backtest-Szenarios und seiner Konfiguration in Amazon Forecast
Amazon Forecast kann die prognostizierten Werte und Genauigkeitsmetriken, die beim Backtesting generiert wurden, exportieren. Die exportierten Daten können zur Auswertung bestimmter Elemente zu bestimmten Zeitpunkten und Quantilen verwendet werden.
Vorhersagequantile und Genauigkeitsmetriken
Prognosequantile können eine Ober- und Untergrenze für Prognosen angeben. Wenn Sie beispielsweise die Prognosetypen 0,1 (P10), 0,5 (P50) und 0,9 (P90) verwenden, entsteht um die P50-Prognose herum ein Wertebereich, der als 80-%-Konfidenzintervall bezeichnet wird. Wenn Sie Vorhersagen für P10, P50 und P90 generieren, können Sie davon ausgehen, dass der wahre Wert in 80 % der Fälle zwischen diesen Grenzen liegt.
Quantile werden in diesem Whitepaper unter Schritt 5 näher erörtert.
Amazon Forecast verwendet die Genauigkeitsmetriken Weighted Quantile Loss (wQL), Root Mean Square Error (RMSE) und Weighted Absolute Percentage Error (WAPE), um beim Backtesting Predictors zu bewerten.
Gewichteter Quantilverlust (Weighted Quantile Loss, wQL)
Die Fehlermetrik Gewichteter Quantilverlust (wQL) misst die Genauigkeit der Prognose eines Modells bei einem bestimmten Quantil. Dies ist besonders nützlich, wenn für Unter- und Überprognosen unterschiedliche Kosten anfallen. Indem Sie die Gewichtung (τ) der wQL-Funktion festlegen, können Sie automatisch unterschiedliche Strafen für Zu- und Unterprognosen einbauen.
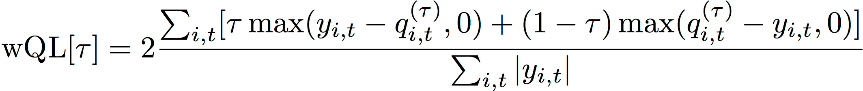
wQL-Funktion
Wobei gilt:
-
τ – ein Quantil in der Menge {0,01, 0,02,..., 0,99}
-
qi, t (τ) – das vom Modell vorhergesagte τ-Quantil.
-
yi, t – der beobachtete Wert am Punkt (i, t)
Gewichteter absoluter prozentualer Fehler (Weighted Absolute Percentage Error, WAPE)
Der gewichtete absolute Prozentfehler (WAPE) ist eine häufig verwendete Metrik zur Messung der Modellgenauigkeit. Es misst die Gesamtabweichung der prognostizierten Werte von den beobachteten Werten.
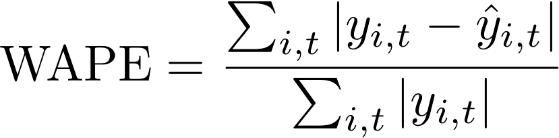
WAPE
Wobei gilt:
-
yi, t – der beobachtete Wert am Punkt (i, t)
-
i, t – der vorhergesagte Wert am Punkt (i, t)
Die Prognose verwendet den Prognosemittelwert als prognostizierten Wert, ŷi,t.
Quadratischer Mittelwertfehler (Root Mean Square Error, RMSE)
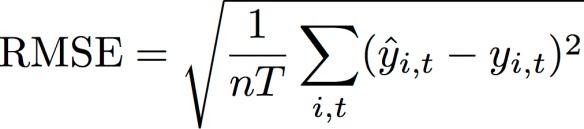
Der quadratische Mittelwertfehler (RMSE) ist eine häufig verwendete Metrik zur Messung der Modellgenauigkeit. Ebenso wie der WAPE misst der RMSE die Gesamtabweichung der Schätzungen von den beobachteten Werten.
Wobei gilt:
-
yi, t – der beobachtete Wert am Punkt (i, t)
-
i, t – der vorhergesagte Wert am Punkt (i, t)
-
nT – Die Anzahl der Datenpunkte in einem Testsatz
Die Prognose verwendet den Prognosemittelwert als prognostizierten Wert, ŷi,t. Bei der Berechnung von Predictor-Metriken ist nT die Anzahl der Datenpunkte in einem Backtest-Fenster.
Probleme mit WAPE und RMSE
Generell sollten die Punktprognosen, die intern oder mit anderen Prognose-Tools generiert werden können, mit den p50-Quantil- oder Mittelwertprognosen übereinstimmen. Sowohl für WAPE als auch für RMSE verwendet Amazon Forecast die Mittelwertprognose, um den prognostizierten Wert (yhat) darzustellen.
Für die Gleichung tau = 0,5 in der wQL [tau] sind beide Gewichtungen gleich, und der wQl [0,5] reduziert sich auf den allgemein verwendeten gewichteten absoluten Prozentfehler (WAPE) für Punktprognosen:
![Abbildung der wQL [0.5]-Gleichung.](images/wql.png)
Wobei yhat = q (0,5) die Berechnungsprognose ist. In der wQL-Formel wird ein Skalierungsfaktor von 2 verwendet, um den Faktor 0,5 zu annullieren und den exakten WAPE [Median]-Ausdruck zu erhalten.
Beachten Sie, dass sich die obige Definition von WAPE von einer gängigen Interpretation des mittleren absoluten prozentualen Fehlers MAPE
Anders als bei der Metrik Gewichteter Quantilverlust für tau, die nicht gleich 0,5 ist, kann die inhärente Verzerrung jedes Quantils nicht durch eine Berechnung wie WAPE erfasst werden, bei der die Gewichtungen gleich sind. Die weiteren Nachteile des WAPE sind, dass er nicht symmetrisch ist, eine zu hohe prozentuale Fehlerquote für kleine Zahlen aufweist und lediglich eine punktuelle Metrik darstellt.
Der RMSE ist das Quadrat des Fehlerbegriffs im WAPE und eine häufige Fehlermetrik in anderen ML-Anwendungen. Die RMSE-Metrik zieht ein Modell vor, bei dem die einzelnen Fehler eine konsistente Größenordnung aufweisen, da große Fehlervariationen den RMSE überproportional ansteigen lassen. Aufgrund des quadratischen Fehlers können einige schlecht vorhergesagte Werte den RMSE in einer ansonsten guten Prognose erhöhen. Außerdem haben Terme mit kleineren Fehlern aufgrund der quadrierten Terme im RMSE ein geringeres Gewicht als im WAPE.
Genauigkeitsmetriken ermöglichen eine quantitative Prognosebewertung. Insbesondere für groß angelegte Vergleiche („Ist Methode A insgesamt besser als Methode B?“) sind diese entscheidend. Es ist jedoch oft wichtig, zu solchen Vergleichen Bildmaterial für die einzelnen SKUs hinzuzufügen.
