Understanding tables, databases, and data catalogs
In Athena, catalogs, databases, and tables are containers for the metadata definitions that define a schema for underlying source data.
Athena uses the following terms to refer to hierarchies of data objects:
-
Data source – a group of databases
-
Database – a group of tables
-
Table – data organized as a group of rows or columns
Sometimes these objects are also referred to with alternate but equivalent names such as the following:
-
A data source is sometimes referred to as a catalog.
-
A database is sometimes referred to as a schema.
Note
This terminology can vary in the federated data sources that you use with Athena. For more information, see Athena and federated table name qualifiers.
The following example query in the Athena console uses the awsdatacatalog data
source, the default database, and the some_table table.
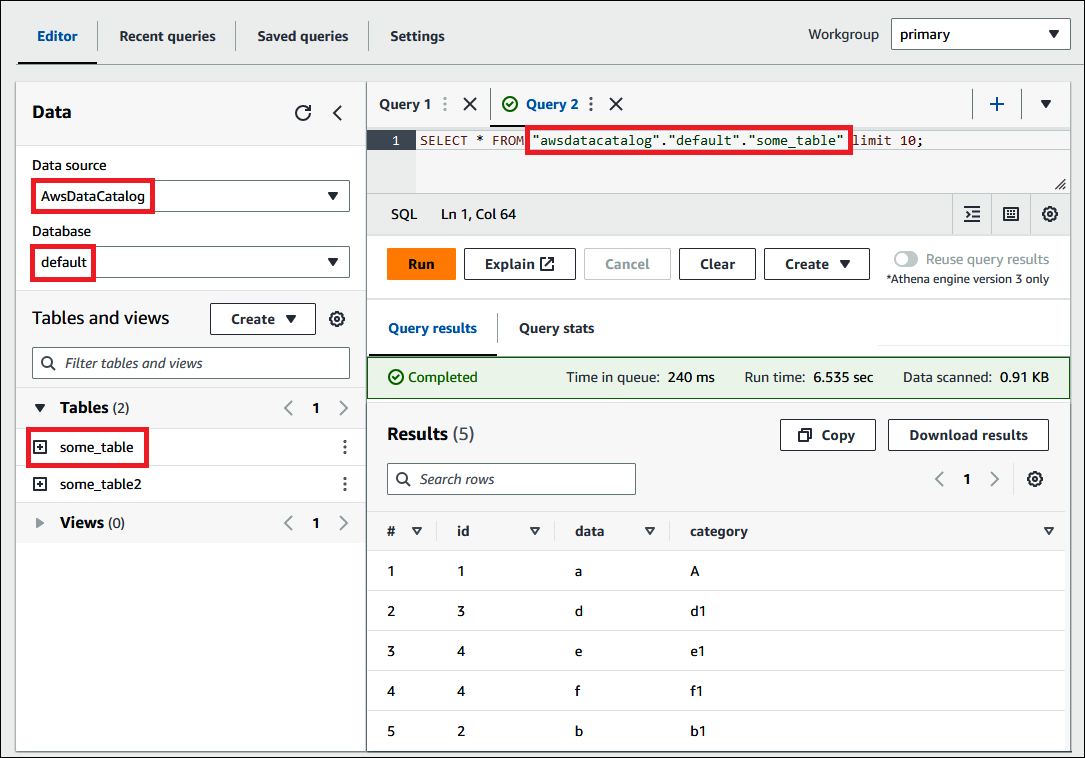
For each dataset, a table needs to exist in Athena. The metadata in the table tells Athena where the data is located in Amazon S3, and specifies the structure of the data, for example, column names, data types, and the name of the table. Databases are a logical grouping of tables, and also hold only metadata and schema information for a dataset.
For each dataset that you'd like to query, Athena must have an underlying table it will use for obtaining and returning query results. Therefore, before querying data, a table must be registered in Athena. The registration occurs when you either create tables automatically or manually.
You can create a table automatically using an AWS Glue crawler. For more information about AWS Glue and crawlers, see Integration with AWS Glue. When AWS Glue creates a table, it registers it in its own AWS Glue Data Catalog. Athena uses the AWS Glue Data Catalog to store and retrieve this metadata, using it when you run queries to analyze the underlying dataset.
Regardless of how the tables are created, the table creation process registers the dataset
with Athena. This registration occurs in the AWS Glue Data Catalog and enables Athena to run queries on
the data. In the Athena query editor, this catalog (or data source) is referred to with the
label AwsDataCatalog.
After you create a table, you can use SQL SELECT statements to query it, including getting specific file locations for your source data. Your query results are stored in Amazon S3 in the query result location that you specify.
The AWS Glue Data Catalog is accessible throughout your Amazon Web Services account. Other AWS services can share the AWS Glue Data Catalog, so you can see databases and tables created throughout your organization using Athena and vice versa.
-
To create a table manually:
-
Use the Athena console to run the Create Table Wizard.
-
Use the Athena console to write Hive DDL statements in the Query Editor.
-
Use the Athena API or CLI to run a SQL query string with DDL statements.
-
Use the Athena JDBC or ODBC driver.
-
When you create tables and databases manually, Athena uses HiveQL data definition language
(DDL) statements such as CREATE TABLE, CREATE DATABASE, and
DROP TABLE under the hood to create tables and databases in the
AWS Glue Data Catalog.
To get started, you can use a tutorial in the Athena console or work through a step-by-step guide in the Athena documentation.
-
To use the tutorial in the Athena console, choose the information icon on the upper right of the console, and then choose the Tutorial tab.
-
For a step-by-step tutorial on creating a table and writing queries in the Athena query editor, see Getting started.
