Calling Amazon Textract Asynchronous Operations
Amazon Textract provides an asynchronous API that you can use to process multipage documents in PDF or TIFF format. You can also use asynchronous operations to process single-page documents that are in JPEG, PNG, TIFF, or PDF format.
The information in this topic uses text detection operations to show how you to use Amazon Textract asynchronous operations. You can use the same approach with the text analysis operations of StartDocumentAnalysis and GetDocumentAnalysis. It also works the same with StartExpenseAnalysis and GetExpenseAnalysis.
For an example, see Detecting or Analyzing Text in a Multipage Document.
If you are analyzing lending documents, you can use the
StartLendingAnalysis operation to classify document pages and send the
classified pages to an Amazon Textract analysis operation. The pages are routed to analysis
operations depending on their assigned class.
You can retreive results for individual pages by using the
GetLendingAnalysis operation, or retrieve a summary of the analysis
with GetLendingAnalysisSummary.
Amazon Textract asynchronously processes a document stored in an Amazon S3 bucket. You start
processing by calling a Start operation, such as StartDocumentTextDetection. The completion status of the
request is published to an Amazon Simple Notification Service (Amazon SNS) topic. To get the completion status from
the Amazon SNS topic, you can use an Amazon Simple Queue Service (Amazon SQS) queue or an AWS Lambda function. After
you have the completion status, you call a Get operation, such as GetDocumentTextDetection, to get the results of the request.
Results of asynchronous calls are encrypted and stored for 7 days in a Amazon Textract
owned bucket by default, unless you specify an Amazon S3 bucket using an operation's
OutputConfig argument. For information on how to let Amazon Textract
send encrypted documents to your Amazon S3 bucket, see Permissions for Output
Configuration.
The following table shows the corresponding Start and Get operations for the different types of asynchronous processing supported by Amazon Textract:
| Processing Type | Start API | Get API |
|---|---|---|
| Text Detection | StartDocumentTextDetection | GetDocumentTextDetection |
| Text Analysis | StartDocumentAnalysis | GetDocumentAnalysis |
| Expense Analysis | StartExpenseAnalysis | GetExpenseAnalysis |
| Lending Analysis | StartLendingAnalysis | GetLendingAnalysis, GetLendingAnalysisSummary |
For an example that uses AWS Lambda functions, see Large scale document processing with Amazon Textract
The following diagram shows the process for detecting document text in a document image stored in an Amazon S3 bucket. In the diagram, an Amazon SQS queue gets the completion status from the Amazon SNS topic.
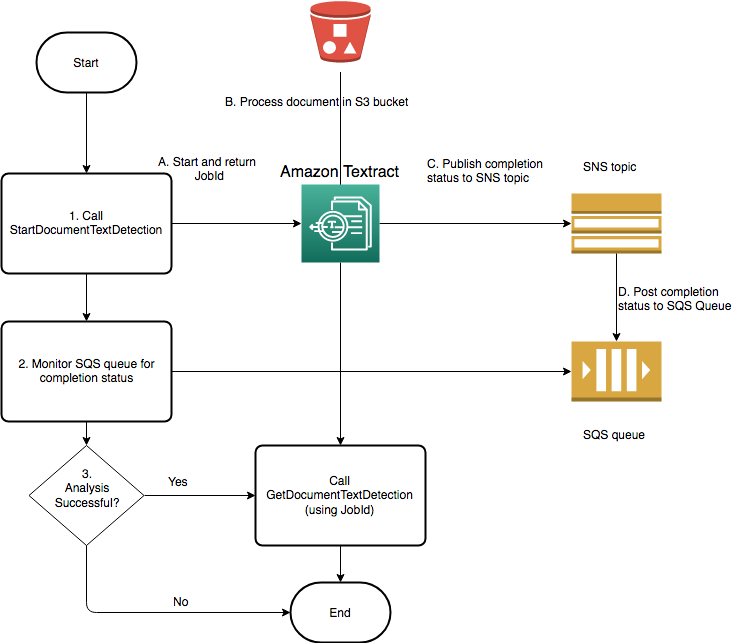
The process displayed by the preceeding diagram is the same for analyzing text and invoices/receipts. You start analyzing text by calling StartDocumentAnalysis and start analyzing invoices/receipts by calling StartExpenseAnalysis You get the results by calling GetDocumentAnalysis or GetExpenseAnalysis respectively.
Starting Text Detection
You start an Amazon Textract text detection request by calling StartDocumentTextDetection. The following is an example of
a JSON request that's passed by StartDocumentTextDetection.
{ "DocumentLocation": { "S3Object": { "Bucket": "bucket", "Name": "image.pdf" } }, "ClientRequestToken": "DocumentDetectionToken", "NotificationChannel": { "SNSTopicArn": "arn:aws:sns:us-east-1:nnnnnnnnnn:topic", "RoleArn": "arn:aws:iam::nnnnnnnnnn:role/roleTopic" }, "JobTag": "Receipt" }
The input parameter DocumentLocation provides the document file name
and the Amazon S3 bucket to retrieve it from. NotificationChannel contains
the Amazon Resource Name (ARN) of the Amazon SNS topic that Amazon Textract notifies when
the text detection request finishes. The Amazon SNS topic must be in the same AWS Region
as the Amazon Textract endpoint that you're calling. NotificationChannel
also contains the ARN for a role that allows Amazon Textract to publish to the Amazon SNS
topic. You give Amazon Textract publishing permissions to your Amazon SNS topics by
creating an IAM service role. For more information, see Configuring Amazon Textract for Asynchronous
Operations.
You can also specify an optional input parameter, JobTag, that
enables you to identify the job, or groups of jobs, in the completion status that's
published to the Amazon SNS topic. For example, you can use JobTag to
identify the type of document being processed, such as a tax form or receipt.
To prevent accidental duplication of analysis jobs, you can optionally provide an
idempotent token, ClientRequestToken. If you supply a value for
ClientRequestToken, the Start operation returns the
same JobId for multiple identical calls to the Start
operation, such as StartDocumentTextDetection. A
ClientRequestToken token has a lifetime of 7 days. After 7 days,
you can reuse it. If you reuse the token during the token lifetime, the following
happens:
-
If you reuse the token with same
Startoperation and the same input parameters, the sameJobIdis returned. The job isn't performed again and Amazon Textract doesn't send a completion status to the registered Amazon SNS topic. -
If you reuse the token with the same
Startoperation and a minor input parameter change, you get anidempotentparametermismatchexception(HTTP status code: 400) exception raised. -
If you reuse the token with a different
Startoperation, the operation succeeds.
Another optional parameter available is OutputConfig, which lets you
adjust where your output will be placed. By default, Amazon Textract will store the
results internally, and can only be accessed by the Get API operations. With
OutputConfig enabled, you can set the name of the bucket the output
will be sent to, and the file prefix of the results, where you can download your
results. Additionally, you can set the KMSKeyID parameter to a
customer managed key to encrypt your output. Without this parameter set Amazon Textract will
encrypt server-side using the AWS managed key for Amazon S3
Note
Before using this parameter, ensure you have the PutObject permission for the output bucket. Additionally, ensure you have the Decrypt, ReEncrypt, GenerateDataKey, and DescribeKey permissions for the AWS KMS key if you decide to use it.
The response to the StartDocumentTextDetection operation is a job
identifier (JobId). Use JobId to track requests and get
the analysis results after Amazon Textract has published the completion status to the
Amazon SNS topic. The following is an example:
{"JobId":"270c1cc5e1d0ea2fbc59d97cb69a72a5495da75851976b14a1784ca90fc180e3"}
If you start too many jobs concurrently, calls to
StartDocumentTextDetection raise a
LimitExceededException exception (HTTP status code: 400) until the
number of concurrently running jobs is below the Amazon Textract service limit.
If you find that LimitExceededException exceptions are raised with bursts of
activity, consider using an Amazon SQS queue to manage incoming requests. Contact AWS
Support if you find that your average number of concurrent requests can't be managed
by an Amazon SQS queue and you're still receiving
LimitExceededException exceptions.
Getting the Completion Status of an Amazon Textract Analysis Request
Amazon Textract sends an analysis completion notification to the registered Amazon SNS
topic. The notification includes the job identifier and the completion status of the
operation in a JSON string. A successful text detection request has a
SUCCEEDED status. For example, the following result shows the
successful processing of a text detection job.
{ "JobId": "642492aea78a86a40665555dc375ee97bc963f342b29cd05030f19bd8fd1bc5f", "Status": "SUCCEEDED", "API": "StartDocumentTextDetection", "JobTag": "Receipt", "Timestamp": 1543599965969, "DocumentLocation": { "S3ObjectName": "document", "S3Bucket": "bucket" } }
For more information, see Amazon Textract Results Notification.
To get the status information published to the Amazon SNS topic by Amazon Textract, use one of the following options:
-
AWS Lambda – You can subscribe an AWS Lambda function that you write to an Amazon SNS topic. The function is called when Amazon Textract notifies the Amazon SNS topic that the request has completed. Use a Lambda function if you want server-side code to process the results of a text detection request. For example, you might want to use server-side code to annotate the image or create a report on the detected text before returning the information to a client application.
-
Amazon SQS – You can subscribe an Amazon SQS queue to an Amazon SNS topic. You then poll the Amazon SQS queue to retrieve the completion status published by Amazon Textract when a text detection request completes. For more information, see Detecting or Analyzing Text in a Multipage Document. Use an Amazon SQS queue if you want to call Amazon Textract operations only from a client application.
Important
We don't recommend getting the request completion status by repeatedly calling
the Amazon Textract Get operation. This is because Amazon Textract
throttles the Get operation if too many requests are made. If
you're processing multiple documents at the same time, it's simpler and more
efficient to monitor one SQS queue for the completion notification than to poll
Amazon Textract for the status of each job individually.
If you have configured your account to receive a results notification from an Amazon Simple Notification Service (Amazon SNS) topic or through an Amazon SQS queue, you should ensure that your account is secure by limiting the scope of Amazon Textract's access to just the resources you are using. This can be done by attaching a trust policy to your IAM service role. For information on how to do this, see Cross-service confused deputy prevention.
Getting Amazon Textract Text Detection Results
To get the results of a text detection request, first ensure that the completion
status that's retrieved from the Amazon SNS topic is SUCCEEDED. Then call
GetDocumentTextDetection, which passes the JobId value
that's returned from StartDocumentTextDetection. The request JSON is
similar to the following example:
{ "JobId": "270c1cc5e1d0ea2fbc59d97cb69a72a5495da75851976b14a1784ca90fc180e3", "MaxResults": 10, "SortBy": "TIMESTAMP" }
JobId is the identifier for the text detection operation. Because
text detection can generate large amounts of data, use MaxResults to
specify the maximum number of results to return in a single
Getoperation. The default value for MaxResults is 1,000.
If you specify a value greater than 1,000, only 1,000 results are returned. If the
operation doesn't return all of the results, a pagination token for the next page is
returned. To get the next page of results, specify the token in the
NextToken parameter.
Note
Results can be retrieved only up to 7 days of job initialization time.
The GetDocumentTextDetection operation response JSON is similar to
the following. The total number of pages that are detected is returned in
DocumentMetadata. The detected text is returned in the
Blocks array. For information about Block objects, see
Text Detection and Document Analysis
Response Objects.
{ "DocumentMetadata": { "Pages": 1 }, "JobStatus": "SUCCEEDED", "Blocks": [ { "BlockType": "PAGE", "Geometry": { "BoundingBox": { "Width": 1.0, "Height": 1.0, "Left": 0.0, "Top": 0.0 }, "Polygon": [ { "X": 0.0, "Y": 0.0 }, { "X": 1.0, "Y": 0.0 }, { "X": 1.0, "Y": 1.0 }, { "X": 0.0, "Y": 1.0 } ] }, "Id": "64533157-c47e-401a-930e-7ca1bb3ac3fa", "Relationships": [ { "Type": "CHILD", "Ids": [ "4297834d-dcb1-413b-8908-3b96866ebbb5", "1d85ba24-2877-4d09-b8b2-393833d769e9", "193e9c47-fd87-475a-ba09-3fda210d8784", "bd8aeb62-961b-4b47-b78a-e4ed9eeecd0f" ] } ], "Page": 1 }, { "BlockType": "LINE", "Confidence": 53.301639556884766, "Text": "ellooworio", "Geometry": { "BoundingBox": { "Width": 0.9999999403953552, "Height": 0.5365243554115295, "Left": 0.0, "Top": 0.46347561478614807 }, "Polygon": [ { "X": 0.0, "Y": 0.46347561478614807 }, { "X": 0.9999999403953552, "Y": 0.46347561478614807 }, { "X": 0.9999999403953552, "Y": 1.0 }, { "X": 0.0, "Y": 1.0 } ] }, "Id": "4297834d-dcb1-413b-8908-3b96866ebbb5", "Relationships": [ { "Type": "CHILD", "Ids": [ "170c3eb9-5155-4bec-8c44-173bba537e70" ] } ], "Page": 1 }, { "BlockType": "LINE", "Confidence": 89.15632629394531, "Text": "He llo,", "Geometry": { "BoundingBox": { "Width": 0.33642634749412537, "Height": 0.49159330129623413, "Left": 0.13885067403316498, "Top": 0.17169663310050964 }, "Polygon": [ { "X": 0.13885067403316498, "Y": 0.17169663310050964 }, { "X": 0.47527703642845154, "Y": 0.17169663310050964 }, { "X": 0.47527703642845154, "Y": 0.6632899641990662 }, { "X": 0.13885067403316498, "Y": 0.6632899641990662 } ] }, "Id": "1d85ba24-2877-4d09-b8b2-393833d769e9", "Relationships": [ { "Type": "CHILD", "Ids": [ "516ae823-3bab-4f9a-9d74-ad7150d128ab", "6bcf4ea8-bbe8-4686-91be-b98dd63bc6a6" ] } ], "Page": 1 }, { "BlockType": "LINE", "Confidence": 82.44834899902344, "Text": "worlo", "Geometry": { "BoundingBox": { "Width": 0.33182239532470703, "Height": 0.3766750991344452, "Left": 0.5091826915740967, "Top": 0.23131252825260162 }, "Polygon": [ { "X": 0.5091826915740967, "Y": 0.23131252825260162 }, { "X": 0.8410050868988037, "Y": 0.23131252825260162 }, { "X": 0.8410050868988037, "Y": 0.607987642288208 }, { "X": 0.5091826915740967, "Y": 0.607987642288208 } ] }, "Id": "193e9c47-fd87-475a-ba09-3fda210d8784", "Relationships": [ { "Type": "CHILD", "Ids": [ "ed135c3b-35dd-4085-8f00-26aedab0125f" ] } ], "Page": 1 }, { "BlockType": "LINE", "Confidence": 88.50325775146484, "Text": "world", "Geometry": { "BoundingBox": { "Width": 0.35004907846450806, "Height": 0.19635874032974243, "Left": 0.527581512928009, "Top": 0.30100569128990173 }, "Polygon": [ { "X": 0.527581512928009, "Y": 0.30100569128990173 }, { "X": 0.8776305913925171, "Y": 0.30100569128990173 }, { "X": 0.8776305913925171, "Y": 0.49736443161964417 }, { "X": 0.527581512928009, "Y": 0.49736443161964417 } ] }, "Id": "bd8aeb62-961b-4b47-b78a-e4ed9eeecd0f", "Relationships": [ { "Type": "CHILD", "Ids": [ "9e28834d-798e-4a62-8862-a837dfd895a6" ] } ], "Page": 1 }, { "BlockType": "WORD", "Confidence": 53.301639556884766, "Text": "ellooworio", "Geometry": { "BoundingBox": { "Width": 1.0, "Height": 0.5365243554115295, "Left": 0.0, "Top": 0.46347561478614807 }, "Polygon": [ { "X": 0.0, "Y": 0.46347561478614807 }, { "X": 1.0, "Y": 0.46347561478614807 }, { "X": 1.0, "Y": 1.0 }, { "X": 0.0, "Y": 1.0 } ] }, "Id": "170c3eb9-5155-4bec-8c44-173bba537e70", "Page": 1 }, { "BlockType": "WORD", "Confidence": 88.46246337890625, "Text": "He", "Geometry": { "BoundingBox": { "Width": 0.15350718796253204, "Height": 0.29955607652664185, "Left": 0.13885067403316498, "Top": 0.21856294572353363 }, "Polygon": [ { "X": 0.13885067403316498, "Y": 0.21856294572353363 }, { "X": 0.292357861995697, "Y": 0.21856294572353363 }, { "X": 0.292357861995697, "Y": 0.5181190371513367 }, { "X": 0.13885067403316498, "Y": 0.5181190371513367 } ] }, "Id": "516ae823-3bab-4f9a-9d74-ad7150d128ab", "Page": 1 }, { "BlockType": "WORD", "Confidence": 89.8501968383789, "Text": "llo,", "Geometry": { "BoundingBox": { "Width": 0.17724157869815826, "Height": 0.49159327149391174, "Left": 0.2980354428291321, "Top": 0.17169663310050964 }, "Polygon": [ { "X": 0.2980354428291321, "Y": 0.17169663310050964 }, { "X": 0.47527703642845154, "Y": 0.17169663310050964 }, { "X": 0.47527703642845154, "Y": 0.6632899045944214 }, { "X": 0.2980354428291321, "Y": 0.6632899045944214 } ] }, "Id": "6bcf4ea8-bbe8-4686-91be-b98dd63bc6a6", "Page": 1 }, { "BlockType": "WORD", "Confidence": 82.44834899902344, "Text": "worlo", "Geometry": { "BoundingBox": { "Width": 0.33182239532470703, "Height": 0.3766750991344452, "Left": 0.5091826915740967, "Top": 0.23131252825260162 }, "Polygon": [ { "X": 0.5091826915740967, "Y": 0.23131252825260162 }, { "X": 0.8410050868988037, "Y": 0.23131252825260162 }, { "X": 0.8410050868988037, "Y": 0.607987642288208 }, { "X": 0.5091826915740967, "Y": 0.607987642288208 } ] }, "Id": "ed135c3b-35dd-4085-8f00-26aedab0125f", "Page": 1 }, { "BlockType": "WORD", "Confidence": 88.50325775146484, "Text": "world", "Geometry": { "BoundingBox": { "Width": 0.35004907846450806, "Height": 0.19635874032974243, "Left": 0.527581512928009, "Top": 0.30100569128990173 }, "Polygon": [ { "X": 0.527581512928009, "Y": 0.30100569128990173 }, { "X": 0.8776305913925171, "Y": 0.30100569128990173 }, { "X": 0.8776305913925171, "Y": 0.49736443161964417 }, { "X": 0.527581512928009, "Y": 0.49736443161964417 } ] }, "Id": "9e28834d-798e-4a62-8862-a837dfd895a6", "Page": 1 } ] }
Using an adapter
With Amazon Textract, you can use an adapter when calling the StartDocumentAnalysis operation. To use an adapter, you must first create and train an adapter by using the Amazon Textract console. To apply your adapter, provide its ID when calling the StartDocumentAnalysis API operation. When calling the StartDocumentAnalysis operation, you can use up to one adapter per page.
"AdaptersConfig": { "Adapters": [ { "AdapterId": "2e9bf1c4aa31", "Version": "1", "Pages": [ "1" ] } ] }
