Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Replicación entre AWS regiones mediante almacenes de datos globales
nota
Actualmente, el almacén de datos global solo está disponible para clústeres autodiseñados.
Al utilizar la función Global Datastore, puede trabajar con una replicación de clústeres de OSS de Valkey o Redis totalmente gestionada, rápida, fiable y segura en todas las regiones. AWS Con esta función, puede crear clústeres de réplicas de lectura entre regiones para permitir las lecturas de baja latencia y la recuperación ante desastres en todas las regiones. AWS
En las secciones siguientes, puede encontrar una descripción de cómo trabajar con almacenes de datos globales.
Temas
Descripción general
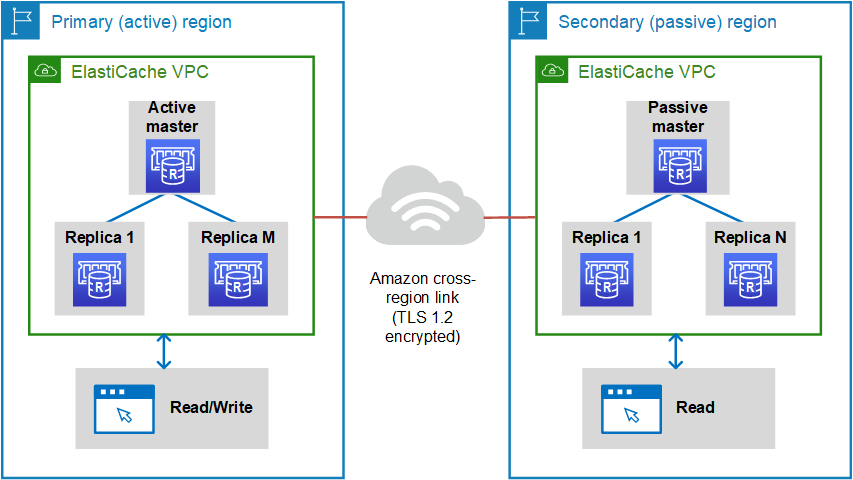
Cada almacén de datos global es un conjunto de uno o más clústeres que se replican entre sí.
Un almacén de datos global consta de lo siguiente:
-
Clúster principal (activo): un clúster principal acepta escrituras que se replican en todos los clústeres dentro del almacén de datos global. Un clúster principal también acepta además solicitudes de lectura.
-
Clúster secundario (pasivo): un clúster secundario solo acepta solicitudes de lectura y replica las actualizaciones de datos a partir de un clúster principal. Un clúster secundario debe estar en una AWS región diferente a la del clúster principal.
Al crear un almacén de datos global ElastiCache para Valkey o Redis OSS, este replica automáticamente los datos del clúster principal al clúster secundario. Elija la AWS región en la que se deben replicar los datos de Valkey o Redis OSS y, a continuación, cree un clúster secundario en esa región. AWS ElastiCache a continuación, configura y gestiona la replicación automática y asíncrona de los datos entre los dos clústeres.
El uso de un almacén de datos global de Valkey or Redis OSS ofrece las siguientes ventajas:
-
Rendimiento geolocal: al configurar clústeres de réplicas remotas en AWS regiones adicionales y sincronizar los datos entre ellas, puede reducir la latencia del acceso a los datos en esa región. AWS Un almacén de datos global puede ayudar a aumentar la capacidad de respuesta de su aplicación al ofrecer lecturas geolocales de baja latencia en todas las regiones. AWS
-
Recuperación de desastres: si el clúster principal de un almacén de datos global experimenta una reducción, puede promocionar un clúster secundario como su clúster principal nuevo. Puede hacerlo conectándose a cualquier AWS región que contenga un clúster secundario.
El siguiente diagrama muestra cómo pueden funcionar los almacenes de datos globales.