Configuración de los parámetros de memoria para Aurora PostgreSQL
En Amazon Aurora PostgreSQL, puede usar varios parámetros que controlan la cantidad de memoria utilizada para las distintas tareas de procesamiento. Si una tarea ocupa más memoria que la cantidad establecida para un parámetro determinado, Aurora PostgreSQL utiliza otros recursos para el procesamiento, como escribir en el disco. Esto puede provocar que el clúster de base de datos de Aurora PostgreSQL se ralentice o se detenga, con un error de memoria insuficiente.
La configuración predeterminada de cada parámetro de memoria normalmente puede gestionar las tareas de procesamiento previstas. Sin embargo, también puede ajustar los parámetros relacionados con la memoria del clúster de base de datos de Aurora PostgreSQL . Realice este ajuste para asegurarse de que se asigne suficiente memoria para procesar su carga de trabajo específica.
A continuación, encontrará información sobre los parámetros que controlan la gestión de memoria. También puede aprender a evaluar la utilización de la memoria.
Comprobación y configuración de los valores de los parámetros
Los parámetros que puede configurar para administrar la memoria y evaluar el uso de memoria del clúster de base de datos de Aurora PostgreSQL son los siguientes:
work_mem: especifica la cantidad de memoria que el clúster de base de datos de Aurora PostgreSQL utiliza para las operaciones internas de ordenación y las tablas hash antes de escribir en los archivos temporales del disco.log_temp_files: registra la creación de archivos temporales, los nombres y los tamaños de los archivos. Cuando se activa este parámetro, se almacena una entrada de registro para cada archivo temporal que se crea. Actívelo para ver con qué frecuencia el clúster de base de datos de Aurora PostgreSQL necesita escribir en el disco. Desactívelo de nuevo después de recopilar información sobre la generación de archivos temporales del clúster de base de datos de Aurora PostgreSQL, para evitar un registro excesivo.logical_decoding_work_mem: especifica la cantidad de memoria (en kilobytes) que debe usar cada búfer de reordenamiento interno antes del volcado en el disco. Esta memoria se usa para la descodificación lógica, que es el proceso que se utiliza para crear una réplica. Se lleva a cabo convirtiendo los datos del archivo de registro de escritura anticipada (WAL) a la salida de transmisión lógica que necesita el destino.El valor de este parámetro crea un búfer único del tamaño especificado para cada conexión de replicación. De forma predeterminada, es de 65 536 KB. Después de llenar este búfer, el exceso se escribe en el disco como un archivo. Para minimizar la actividad del disco, puede establecer el valor de este parámetro a un valor mucho más alto que el de
work_mem.
Todos estos son parámetros dinámicos, por lo que puede cambiarlos para la sesión actual. Para ello, conéctese a la instrucción del clúster de base de datos de Aurora PostgreSQL con psql y usando la instrucción SET, tal como se muestra a continuación.
SET parameter_name TO parameter_value;La configuración de la sesión dura tanto como la sesión. Cuando finaliza la sesión, el parámetro vuelve a su configuración en el grupo de parámetros del clúster de base de datos. Antes de cambiar cualquier parámetro, compruebe primero los valores actuales consultando la tabla pg_settings, de la siguiente manera.
SELECT unit, setting, max_val FROM pg_settings WHERE name='parameter_name';
Por ejemplo, para encontrar el valor del parámetro work_mem, conéctese a la instancia de escritor del clúster de base de datos de Aurora PostgreSQL y ejecute la siguiente consulta.
SELECT unit, setting, max_val, pg_size_pretty(max_val::numeric) FROM pg_settings WHERE name='work_mem';unit | setting | max_val | pg_size_pretty ------+----------+-----------+---------------- kB | 1024 | 2147483647| 2048 MB (1 row)
Para cambiar la configuración de los parámetros para que se mantengan, es necesario utilizar un grupo de parámetros del clúster de base de datos personalizado. Después de practicar con el clúster de base de datos de Aurora PostgreSQL con valores diferentes para estos parámetros usando el parámetro SET, puede crear un grupo de parámetros personalizado y aplicarlo a su clúster de base de datos de Aurora PostgreSQL. Para obtener más información, consulte Grupos de parámetros para Amazon Aurora.
Comprensión del parámetro de memoria de trabajo
El parámetro de memoria de trabajo (work_mem) especifica la cantidad máxima de memoria que Aurora PostgreSQL puede usar para procesar consultas complejas. Las consultas complejas incluyen aquellas que implican operaciones de clasificación o agrupación; en otras palabras, las consultas que utilizan las siguientes cláusulas:
ORDER BY
DISTINCT
GROUP BY
JOIN (MERGE y HASH)
El planificador de consultas afecta indirectamente a la forma en que el clúster de base de datos de Aurora PostgreSQL utiliza la memoria El planificador de consultas genera planes de ejecución para procesar instrucciones SQL. Un plan determinado puede dividir una consulta compleja en varias unidades de trabajo que se pueden ejecutar en paralelo. Cuando es posible, Aurora PostgreSQL utiliza la cantidad de memoria especificada en el parámetro work_mem para cada sesión antes de escribir en el disco para cada proceso paralelo.
Varios usuarios de bases de datos que ejecutan varias operaciones simultáneamente y generan varias unidades de trabajo en paralelo pueden agotar la memoria de trabajo asignada al clúster de base de datos de Aurora PostgreSQL. Esto puede provocar una creación excesiva de archivos temporales y E/S de disco o, lo que es peor, puede provocar un error de falta de memoria.
Identificación del uso de archivos temporales
Siempre que la memoria necesaria para procesar consultas supere el valor especificado en el parámetro work_mem, los datos de trabajo se descargan al disco en un archivo temporal. Puede ver la frecuencia con la que ocurre esto activando el parámetro log_temp_files. De forma predeterminada, este parámetro está desactivado (establecido en -1). Para capturar toda la información del archivo temporal, defina este parámetro en 0. Establezca log_temp_files en cualquier otro entero positivo para capturar información de archivos temporales para archivos iguales o superiores a esa cantidad de datos (en kilobytes). En la siguiente imagen, puede ver un ejemplo de AWS Management Console.
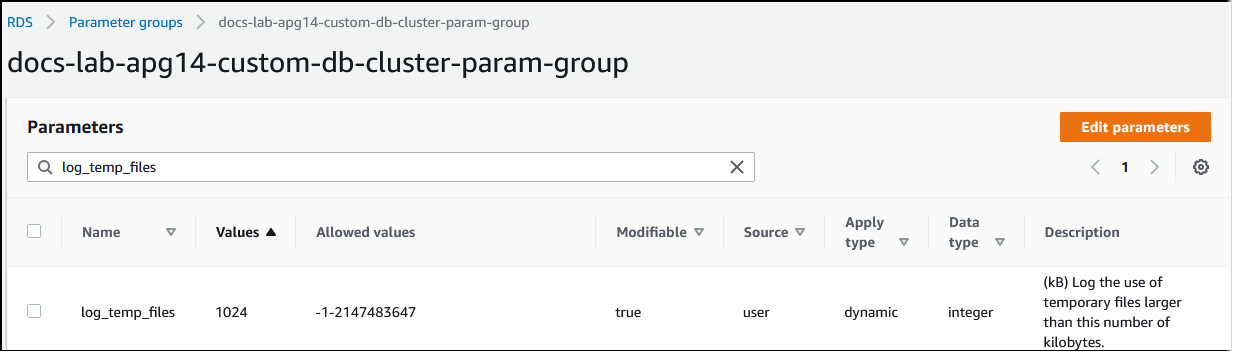
Tras configurar el registro de archivos temporales, puede realizar pruebas con su propia carga de trabajo para comprobar si la configuración de la memoria de trabajo es suficiente. También puede simular una carga de trabajo mediante pgbench, una sencilla aplicación de evaluación de referencia de la comunidad de PostgreSQL.
En el siguiente ejemplo se inicializa (-i) pgbench creando las tablas y filas necesarias para ejecutar las pruebas. En este ejemplo, el factor de escalado (-s 50) crea 50 filas en la tabla pgbench_branches, 500 filas en la tabla pgbench_tellers y 5 000 000 filas en la tabla pgbench_accounts de la base de datos de labdb.
pgbench -U postgres -h your-cluster-instance-1.111122223333.aws-regionrds.amazonaws.com -p 5432 -i -s 50 labdb
Password:
dropping old tables...
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
creating tables...
generating data (client-side)...
5000000 of 5000000 tuples (100%) done (elapsed 15.46 s, remaining 0.00 s)
vacuuming...
creating primary keys...
done in 61.13 s (drop tables 0.08 s, create tables 0.39 s, client-side generate 54.85 s, vacuum 2.30 s, primary keys 3.51 s)Después de inicializar el entorno, puede ejecutar la referencia para un tiempo específico (-T) y el número de clientes (-c). En este ejemplo también se utiliza la opción -d para generar información de depuración a medida que el clúster de base de datos de Aurora PostgreSQL procesa las transacciones.
pgbench -h -U postgresyour-cluster-instance-1.111122223333.aws-regionrds.amazonaws.com -p 5432 -d -T 60 -c 10labdbPassword:*******pgbench (14.3) starting vacuum...end. transaction type: <builtin: TPC-B (sort of)> scaling factor: 50 query mode: simple number of clients: 10 number of threads: 1 duration: 60 s number of transactions actually processed: 1408 latency average = 398.467 ms initial connection time = 4280.846 ms tps = 25.096201 (without initial connection time)
Para obtener más información acerca de pgbench, consulte pgbench
Puede utilizar el comando de metacomandos psql (\d) para enumerar las relaciones, como tablas, vistas e índices, creadas por pgbench.
labdb=>\d pgbench_accountsTable "public.pgbench_accounts" Column | Type | Collation | Nullable | Default ----------+---------------+-----------+----------+--------- aid | integer | | not null | bid | integer | | | abalance | integer | | | filler | character(84) | | | Indexes: "pgbench_accounts_pkey" PRIMARY KEY, btree (aid)
Como se muestra en el resultado, la tabla pgbench_accounts está indexada en la columna aid. Para asegurarse de que la siguiente consulta utilice memoria de trabajo, consulte cualquier columna no indexada, como la que se muestra en el siguiente ejemplo.
postgres=>SELECT * FROM pgbench_accounts ORDER BY bid;
Compruebe los archivos temporales en el registro. Para ello, abra AWS Management Console, elija la instancia del clúster de base de datos de Aurora PostgreSQL y, a continuación, la pestaña Logs & events (Registros y eventos). Puede ver los registros en la consola o descargarlos para analizarlos en detalle. Tal como se muestra en la siguiente imagen, el tamaño de los archivos temporales necesarios para procesar la consulta indica que debe considerar aumentar la cantidad especificada para el parámetro work_mem.
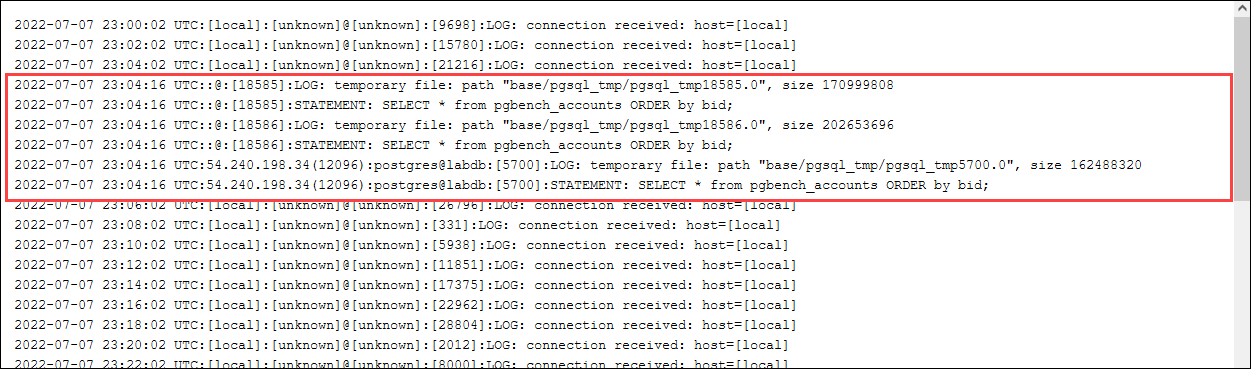
Puede configurar este parámetro de forma diferente para individuos y grupos, en función de sus necesidades operativas. Por ejemplo, puede establecer el parámetro work_mem en 8 GB para el rol denominado dev_team.
postgres=>ALTER ROLEdev_teamSET work_mem=‘8GB';
Con esta configuración de work_mem, a cualquier rol que sea miembro del rol dev_team se le asignan hasta 8 GB de memoria de trabajo.
Uso de índices para un tiempo de respuesta más rápido
Si sus consultas tardan demasiado en devolver resultados, puede comprobar que los índices se están utilizando de la forma esperada. En primer lugar, active \timing, el metacomando psql, tal como se indica a continuación.
postgres=>\timing on
Después de activar la temporización, utilice una instrucción SELECT sencilla.
postgres=>SELECT COUNT(*) FROM (SELECT * FROM pgbench_accounts ORDER BY bid) AS accounts;count ------- 5000000 (1 row) Time: 3119.049 ms (00:03.119)
Como se ve en el resultado, esta consulta ha tardado poco más de 3 segundos en completarse. Para mejorar el tiempo de respuesta, cree un índice en pgbench_accounts, de la siguiente manera.
postgres=>CREATE INDEX ON pgbench_accounts(bid);CREATE INDEX
Vuelva a ejecutar la consulta y observe que el tiempo de respuesta es más rápido. En este ejemplo, la consulta se completó unas 5 veces más rápido, en aproximadamente medio segundo.
postgres=>SELECT COUNT(*) FROM (SELECT * FROM pgbench_accounts ORDER BY bid) AS accounts;count ------- 5000000 (1 row) Time: 567.095 ms
Ajuste de la memoria de trabajo para la descodificación lógica
La replicación lógica ha estado disponible en todas las versiones de Aurora PostgreSQL desde su introducción en PostgreSQL versión 10. Al configurar la replicación lógica, también puede establecer el parámetro logical_decoding_work_mem para especificar la cantidad de memoria que el proceso de descodificación lógica puede usar para el proceso de descodificación y transmisión.
Durante la descodificación lógica, los registros de registro de escritura anticipada (WAL) se convierten en instrucciones SQL que luego se envían a otro destino para la replicación lógica u otra tarea. Cuando se escribe una transacción en el WAL y, a continuación, se convierte, la transacción completa debe ajustarse al valor especificado para logical_decoding_work_mem. De forma predeterminada, este parámetro se establece en 65536 KB. Los desbordamientos se escriben en el disco. Esto significa que se debe volver a leer desde el disco antes de que se pueda enviar a su destino, lo que ralentiza el proceso general.
Puede evaluar la cantidad de desbordamiento de transacciones en su carga de trabajo actual en un momento específico mediante la función aurora_stat_file, tal como se muestra en el siguiente ejemplo.
SELECT split_part (filename, '/', 2) AS slot_name, count(1) AS num_spill_files, sum(used_bytes) AS slot_total_bytes, pg_size_pretty(sum(used_bytes)) AS slot_total_size FROM aurora_stat_file() WHERE filename like '%spill%' GROUP BY 1;slot_name | num_spill_files | slot_total_bytes | slot_total_size ------------+-----------------+------------------+----------------- slot_name | 590 | 411600000 | 393 MB (1 row)
Esta consulta devuelve el recuento y el tamaño de los archivos de vertido en el clúster de base de datos de Aurora PostgreSQL cuando se invoca la consulta. Es posible que las cargas de trabajo más largas no tengan aún ningún archivo de vertido en el disco. Para crear perfiles de cargas de trabajo de larga duración, le recomendamos que cree una tabla para capturar la información del archivo de vertido a medida que se ejecute la carga de trabajo. Puede crear la tabla tal y como se indica a continuación.
CREATE TABLE spill_file_tracking AS SELECT now() AS spill_time,* FROM aurora_stat_file() WHERE filename LIKE '%spill%';
Para ver cómo se usan los archivos de vertido durante la replicación lógica, configure un publicador y un suscriptor y, a continuación, inicie una replicación simple. Para obtener más información, consulte Configuración de la replicación lógica para el clúster de base de datos de Aurora PostgreSQL. Con la replicación en marcha, puede crear un trabajo que capture el conjunto de resultados de la función de archivo de vertido aurora_stat_file(), de la siguiente manera.
INSERT INTO spill_file_tracking SELECT now(),* FROM aurora_stat_file() WHERE filename LIKE '%spill%';
Utilice el siguiente comando psql para ejecutar el trabajo una vez por segundo.
\watch 0.5
Mientras se ejecuta el trabajo, conéctese a la instancia de escritor desde otra sesión de psql. Utilice la siguiente serie de instrucciones para ejecutar una carga de trabajo que supere la configuración de memoria y haga que Aurora PostgreSQL cree un archivo de vertido.
labdb=>CREATE TABLE my_table (a int PRIMARY KEY, b int);CREATE TABLElabdb=>INSERT INTO my_table SELECT x,x FROM generate_series(0,10000000) x;INSERT 0 10000001labdb=>UPDATE my_table SET b=b+1;UPDATE 10000001
Estas instrucciones pueden tardar varios minutos en completarse. Cuando haya terminado, pulse la tecla Ctrl y la tecla C a la vez para detener la función de monitorización. A continuación, utilice el siguiente comando para crear una tabla que contenga la información sobre el uso de archivos de vertido del clúster de base de datos de Aurora PostgreSQL.
SELECT spill_time, split_part (filename, '/', 2) AS slot_name, count(1) AS spills, sum(used_bytes) AS slot_total_bytes, pg_size_pretty(sum(used_bytes)) AS slot_total_size FROM spill_file_tracking GROUP BY 1,2 ORDER BY 1;spill_time | slot_name | spills | slot_total_bytes | slot_total_size ------------------------------+-----------------------+--------+------------------+----------------- 2022-04-15 13:42:52.528272+00 | replication_slot_name | 1 | 142352280 | 136 MB 2022-04-15 14:11:33.962216+00 | replication_slot_name | 4 | 467637996 | 446 MB 2022-04-15 14:12:00.997636+00 | replication_slot_name | 4 | 569409176 | 543 MB 2022-04-15 14:12:03.030245+00 | replication_slot_name | 4 | 569409176 | 543 MB 2022-04-15 14:12:05.059761+00 | replication_slot_name | 5 | 618410996 | 590 MB 2022-04-15 14:12:07.22905+00 | replication_slot_name | 5 | 640585316 | 611 MB (6 rows)
El resultado muestra que al ejecutar el ejemplo se crearon cinco archivos de vertido que utilizaron 611 MB de memoria. Para evitar escribir en el disco, recomendamos configurar el parámetro logical_decoding_work_mem con el siguiente tamaño de memoria más alto: 1024.
