Administración de la pérdida de conexión de Aurora PostgreSQL con agrupación
Cuando las aplicaciones cliente se conectan y desconectan con tanta frecuencia que el tiempo de respuesta del clúster de base de datos de Aurora PostgreSQL se ralentiza, se dice que el clúster está experimentando pérdida de conexión. Cada nueva conexión al punto de conexión del clúster de base de datos de Aurora PostgreSQL consume recursos, lo que reduce el número de recursos que se puede usar para procesar la carga de trabajo real. La pérdida de conexión es un problema que le aconsejamos que administre siguiendo algunas de las prácticas recomendadas que se describen a continuación.
Para empezar, puede mejorar los tiempos de respuesta en los clústeres de base de datos de Aurora PostgreSQL que tienen altas tasas de pérdida de conexión. Por ejemplo, puede utilizar un concentrador de conexiones como RDS Proxy. Un concentrador de conexiones proporciona una caché de conexiones listas para usar para los clientes. Casi todas las versiones de Aurora PostgreSQL admiten RDS Proxy. Para obtener más información, consulte Proxy de Amazon RDS con Aurora PostgreSQL.
Si su versión específica de Aurora PostgreSQL no admite RDS Proxy, puede usar otro agrupador de conexiones compatible con PostgreSQL, como PgBouncer. Para obtener más información, consulte el sitio web de PgBouncer
Para comprobar si el clúster de base de datos de Aurora PostgreSQL puede beneficiarse de la agrupación de conexiones, consulte el archivo postgresql.log para conexiones y desconexiones. También puede usar Performance Insights para averiguar cuánta pérdida de conexión está experimentando su clúster de base de datos de Aurora PostgreSQL. A continuación, encontrará información sobre ambos temas.
Conexiones y desconexiones de registro
Los parámetros log_connections y log_disconnections pueden capturar conexiones y desconexiones en la instancia de escritor instancia del clúster de base de datos de Aurora PostgreSQL. De forma predeterminada, este parámetro está desactivado. Para activar estos parámetros, utilice un grupo de parámetros personalizado y actívelo cambiando el valor a 1. Para obtener más información acerca de los grupos de parámetros personalizados, consulte Grupos de parámetros de clústeres de base de datos para clústeres de base de datos en Amazon Aurora. Para comprobar la configuración, conéctese al punto de conexión del clúster de base de datos para Aurora PostgreSQL mediante psql y realice la consulta de la siguiente manera.
labdb=>SELECT setting FROM pg_settings WHERE name = 'log_connections';setting --------- on (1 row)labdb=>SELECT setting FROM pg_settings WHERE name = 'log_disconnections';setting --------- on (1 row)
Con ambos parámetros activados, el registro captura todas las conexiones y desconexiones nuevas. Verá el usuario y la base de datos de cada nueva conexión autorizada. En el momento de la desconexión, también se registra la duración de la sesión, tal como se muestra en el ejemplo siguiente.
2022-03-07 21:44:53.978 UTC [16641] LOG: connection authorized: user=labtek database=labdb application_name=psql
2022-03-07 21:44:55.718 UTC [16641] LOG: disconnection: session time: 0:00:01.740 user=labtek database=labdb host=[local]
Para comprobar la pérdida de conexión de su aplicación, active estos parámetros si aún no están activados. A continuación, recopile datos en el registro de PostgreSQL para analizarlos ejecutando su aplicación con una carga de trabajo y un período de tiempo realistas. Puede usar la consola de RDS para ver los archivos de registro. Elija la instancia de escritor de su clúster de base de datos de Aurora PostgreSQL y, a continuación, elija la pestaña Logs & events (Registros y eventos). Para obtener más información, consulte Visualización y descripción de archivos de registro de base de datos.
También puede descargar el archivo de registro de la consola y usar la siguiente secuencia de comandos. Esta secuencia encuentra el número total de conexiones autorizadas y descartadas por minuto.
grep "connection authorized\|disconnection: session time:" postgresql.log.2022-03-21-16|\ awk {'print $1,$2}' |\ sort |\ uniq -c |\ sort -n -k1
En el resultado del ejemplo, puede ver un pico en las conexiones autorizadas seguido de desconexiones a partir de las 16:12:10.
.....
,......
.........
5 2022-03-21 16:11:55 connection authorized:
9 2022-03-21 16:11:55 disconnection: session
5 2022-03-21 16:11:56 connection authorized:
5 2022-03-21 16:11:57 connection authorized:
5 2022-03-21 16:11:57 disconnection: session
32 2022-03-21 16:12:10 connection authorized:
30 2022-03-21 16:12:10 disconnection: session
31 2022-03-21 16:12:11 connection authorized:
27 2022-03-21 16:12:11 disconnection: session
27 2022-03-21 16:12:12 connection authorized:
27 2022-03-21 16:12:12 disconnection: session
41 2022-03-21 16:12:13 connection authorized:
47 2022-03-21 16:12:13 disconnection: session
46 2022-03-21 16:12:14 connection authorized:
41 2022-03-21 16:12:14 disconnection: session
24 2022-03-21 16:12:15 connection authorized:
29 2022-03-21 16:12:15 disconnection: session
28 2022-03-21 16:12:16 connection authorized:
24 2022-03-21 16:12:16 disconnection: session
40 2022-03-21 16:12:17 connection authorized:
42 2022-03-21 16:12:17 disconnection: session
40 2022-03-21 16:12:18 connection authorized:
40 2022-03-21 16:12:18 disconnection: session
.....
,......
.........
1 2022-03-21 16:14:10 connection authorized:
1 2022-03-21 16:14:10 disconnection: session
1 2022-03-21 16:15:00 connection authorized:
1 2022-03-21 16:16:00 connection authorized:
Con esta información, puede decidir si su carga de trabajo puede beneficiarse de un agrupador de conexiones. Para realizar análisis más detallados, puede utilizar Performance Insights.
Detección de la pérdida de conexión con Performance Insights
Puede utilizar Performance Insights para evaluar la cantidad de pérdida de conexión en su clúster de base de datos de Aurora PostgreSQL-Compatible Edition. Al crear un clúster de base de datos de Aurora PostgreSQL, la configuración de Performance Insights se activa de forma predeterminada. Si ha desactivado esta opción al crear el clúster de base de datos, modifique el clúster para activar la función. Para obtener más información, consulte Modificación de un clúster de base de datos de Amazon Aurora.
Si Performance Insights se ejecuta en su clúster de base de datos de Aurora PostgreSQL, puede elegir las métricas que desee supervisar. Puede acceder a Performance Insights desde el panel de navegación de la consola. También puede acceder a Performance Insights desde la pestaña Monitoring (Monitorización)de la instancia de escritura del clúster de base de datos de Aurora PostgreSQL, tal como se muestra en la siguiente imagen.
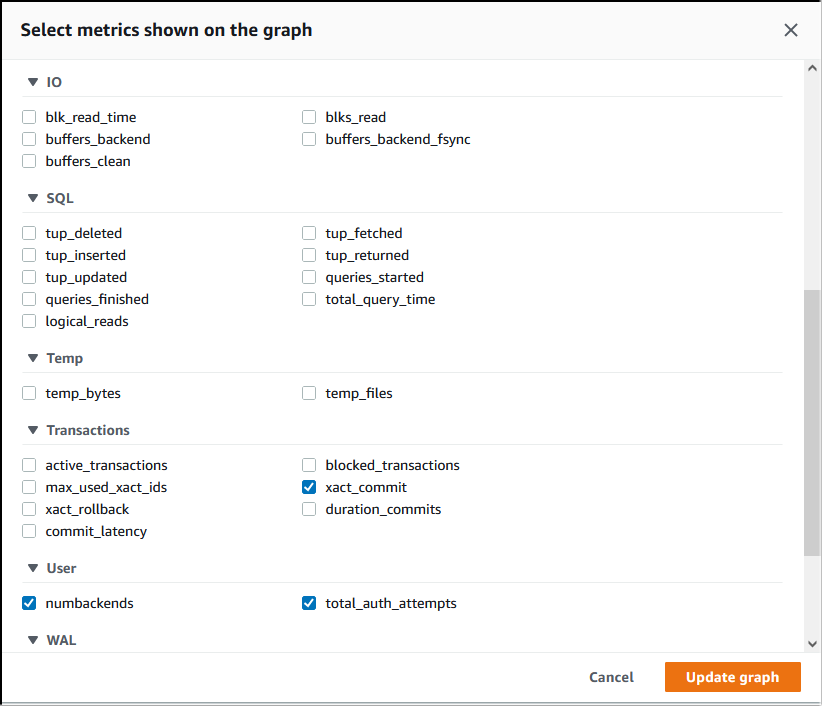
En la consola de Performance Insights, elija Manage metrics (Administrar métricas). Para analizar la actividad de conexión y desconexión del clúster de base de datos de Aurora PostgreSQL, elija las siguientes métricas. Todas estas son métricas de PostgreSQL.
xact_commit: número de transacciones confirmadas.total_auth_attempts: número de intentos de conexión de usuarios autenticados por minuto.numbackends: número de backends conectados actualmente a la base de datos.
Para guardar la configuración y mostrar la actividad de conexión, elija Update graph (Actualizar gráfico).
En la siguiente imagen, puede ver el impacto de ejecutar pgbench con 100 usuarios. La línea que muestra las conexiones está en una pendiente ascendente constante. Para más información sobre pgbench y su uso, consulte pgbench
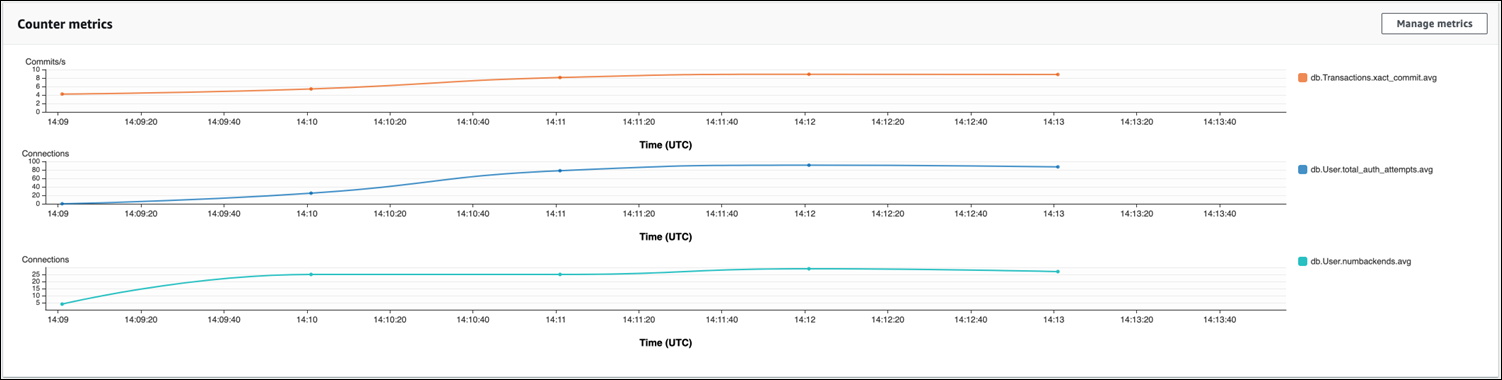
La imagen muestra que ejecutar una carga de trabajo con tan solo 100 usuarios sin un agrupador de conexiones puede provocar un aumento significativo en la cantidad de total_auth_attempts durante todo el procesamiento de la carga de trabajo. Tenga en cuenta que es mejor mantener total_auth_attempts lo más cerca posible de cero.
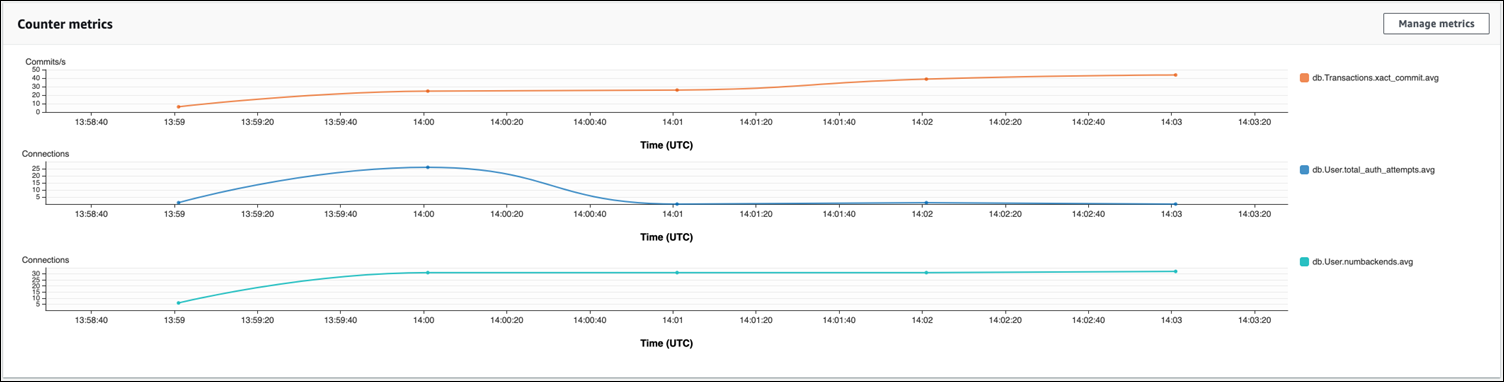
Con la agrupación de conexiones de RDS Proxy, los intentos de conexión aumentan al inicio de la carga de trabajo. Después de configurar el grupo de conexiones, el promedio disminuye. Los recursos utilizados por las transacciones y el uso de backend se mantienen consistentes durante todo el procesamiento de la carga.
Para obtener más información acerca del uso de Performance Insights con su clúster de base de datos de Aurora PostgreSQL, consulte Monitoreo de la carga de base de datos con Performance Insights en Amazon Aurora. Para analizar las métricas, consulte Análisis de métricas mediante el panel de Información sobre rendimiento.
Demostración de los beneficios de la agrupación de conexiones
Tal como se menciona anteriormente, si determina que el clúster de base de datos de Aurora PostgreSQL tiene un problema de pérdida de conexión, puede usar RDS Proxy para mejorar el rendimiento. A continuación, encontrará un ejemplo que muestra las diferencias en el procesamiento de una carga de trabajo cuando las conexiones están agrupadas y cuando no lo están. El ejemplo usa pgbench para modelar una carga de trabajo de transacciones.
De igual modo que psql, pgbench es una aplicación cliente de PostgreSQL que puede instalar y ejecutar desde su máquina cliente local. También puede instalarla y ejecutarla desde la instancia de Amazon EC2 que utiliza para administrar el clúster de base de datos de Aurora PostgreSQL. Para obtener más información, consulte pgbench
Para seguir este ejemplo, primero debe crear el entorno pgbench en su base de datos. El siguiente comando es la plantilla básica para inicializar las tablas pgbench en la base de datos especificada. En este ejemplo se utiliza la cuenta de usuario principal predeterminada, postgres, para iniciar sesión. Cámbiela según sea necesario para el clúster de base de datos de Aurora PostgreSQL. El entorno pgbench se crea en una base de datos en la instancia de escritor de su clúster.
nota
El proceso de inicialización de pgbench descarta y vuelve a crear tablas denominadas pgbench_accounts, pgbench_branches, pgbench_history y pgbench_tellers. Asegúrese de que la base de datos que elija para dbname
pgbench -U postgres -hdb-cluster-instance-1.111122223333.aws-region.rds.amazonaws.com -p 5432 -d -i -s 50dbname
Para pgbench, especifique los siguientes parámetros.
- -d
-
Genera un informe de depuración a medida que se ejecuta pgbench.
- -h
-
Especifica el punto de conexión de la instancia de escritor del clúster de la base de datos de Aurora PostgreSQL.
- -i
-
Inicializa el entorno pgbench en la base de datos para las pruebas de referencia.
- -p
-
Identifica el puerto utilizado para las conexiones de la base de datos El valor predeterminado para Aurora PostgreSQL suele ser 5432 o 5433.
- -s
-
Especifica el factor de escala que se utilizará para rellenar las tablas con filas. El factor de escala predeterminado es 1, lo que genera 1 fila en la tabla
pgbench_branches, 10 filas en la tablapgbench_tellersy 100 000 filas en la tablapgbench_accounts. - -U
-
Especifica la cuenta de usuario de la instancia de escritor del clúster de la base de datos de Aurora PostgreSQL.
Después de configurar el entorno pgbench, puede ejecutar pruebas de referencia con y sin agrupación de conexiones. La prueba predeterminada consiste en una serie de cinco comandos SELECT, UPDATE e INSERT por transacción que se ejecutan repetidamente durante el tiempo especificado. Puede especificar el factor de escala, el número de clientes y otros detalles para modelar sus propios casos de uso.
Por ejemplo, el siguiente comando ejecuta la referencia durante 60 segundos (opción -T, para el tiempo) con 20 conexiones simultáneas (la opción -c). La opción -C hace que la prueba se ejecute con una nueva conexión cada vez, en lugar de hacerlo una vez por sesión de cliente. Esta configuración le da una indicación de la sobrecarga de la conexión.
pgbench -h docs-lab-apg-133-test-instance-1.c3zr2auzukpa.us-west-1.rds.amazonaws.com -U postgres -p 5432 -T 60 -c 20 -C labdbPassword:**********pgbench (14.3, server 13.3) starting vacuum...end. transaction type: <builtin: TPC-B (sort of)> scaling factor: 50 query mode: simple number of clients: 20 number of threads: 1 duration: 60 s number of transactions actually processed: 495 latency average = 2430.798 ms average connection time = 120.330 ms tps = 8.227750 (including reconnection times)
La ejecución de pgbench en la instancia de escritor de un clúster de base de datos de Aurora PostgreSQL sin volver a utilizar las conexiones muestra que solo se procesan unas 8 transacciones por segundo. Esto da un total de 495 transacciones durante la prueba de 1 minuto.
Si reutiliza las conexiones, la respuesta del clúster de base de datos de Aurora PostgreSQL para el número de usuarios es casi 20 veces más rápida. Con la reutilización, se procesan un total de 9042 transacciones, si comparamos con las 495 con la misma cantidad de tiempo y para el mismo número de conexiones de usuario. La diferencia es que, a continuación, cada conexión se vuelve a utilizar.
pgbench -h docs-lab-apg-133-test-instance-1.c3zr2auzukpa.us-west-1.rds.amazonaws.com -U postgres -p 5432 -T 60 -c 20 labdbPassword:*********pgbench (14.3, server 13.3) starting vacuum...end. transaction type: <builtin: TPC-B (sort of)> scaling factor: 50 query mode: simple number of clients: 20 number of threads: 1 duration: 60 s number of transactions actually processed: 9042 latency average = 127.880 ms initial connection time = 2311.188 ms tps = 156.396765 (without initial connection time)
En este ejemplo se muestra que agrupar conexiones puede mejorar significativamente los tiempos de respuesta. Para obtener información acerca de cómo configurar RDS Proxy para el clúster de base de datos de Aurora PostgreSQL, consulte Amazon RDS Proxy para Aurora.
