Arquitectura de Base de datos ilimitada de Aurora PostgreSQL
Base de datos ilimitada logra escalar con una arquitectura de dos capas que consta de varios nodos de base de datos. Los nodos son enrutadores o particiones.
-
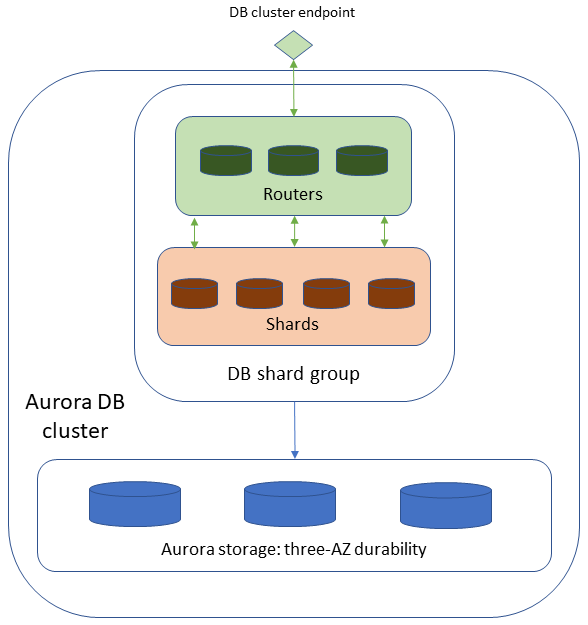
Las particiones son instancias de Base de datos ilimitada de Aurora PostgreSQL, cada una de las cuales almacena un subconjunto de los datos de la base de datos, lo que permite el procesamiento simultáneo para lograr un mayor rendimiento de escritura.
-
Los enrutadores administran la naturaleza distribuida de la base de datos y presentan una única imagen de la base de datos a los clientes de la base de datos. Los enrutadores mantienen los metadatos sobre el lugar donde se almacenan los datos, analizan los comandos SQL entrantes y los envían a las particiones. Luego, agregan los datos de las particiones para devolver un único resultado al cliente y administran las transacciones distribuidas para mantener la coherencia en toda la base de datos distribuida.
Base de datos ilimitada de Aurora PostgreSQL se diferencia de los Clústeres de base de datos de Aurora estándar en que tiene un grupo de particiones de base de datos en lugar de una instancia de base de datos de escritura e instancias de base de datos de lectura. Todos los nodos que componen la arquitectura de Base de datos ilimitada están incluidos en el grupo de particiones de base de datos. Las particiones y enrutadores individuales del grupo de particiones de base de datos no están visibles en su Cuenta de AWS. Utilice el punto de conexión del clúster de base de datos para acceder a Base de datos ilimitada.
La siguiente figura muestra la arquitectura de alto nivel de Base de datos ilimitada de Aurora PostgreSQL.
Para obtener más información sobre la arquitectura de Base de datos ilimitada de Aurora PostgreSQL y cómo utilizarla, consulte este vídeo en el canal AWS Events de YouTube:
Para obtener más información acerca de la arquitectura de un clúster de base de datos de Aurora estándar, consulte Clústeres de base de datos de Amazon Aurora.
Términos clave de Base de datos ilimitada de Aurora PostgreSQL
- Grupo de particiones de bases de datos
-
Es un contenedor para los nodos de Base de datos ilimitada (particiones y enrutadores).
- Enrutador
-
Es un nodo que acepta conexiones SQL de los clientes, envía comandos SQL a las particiones, mantiene la coherencia en todo el sistema y devuelve los resultados a los clientes.
- Partición
-
Es un nodo que almacena un subconjunto de tablas particionadas, copias completas de tablas de referencia y tablas estándar. Acepta consultas de enrutadores, pero los clientes no pueden conectarse directamente a ellos.
- Tabla particionada
-
Es una tabla cuyos datos están divididos en particiones.
- Clave de partición
-
Es una columna o conjunto de columnas de una tabla particionada que se utiliza para determinar la división entre las particiones.
- Tablas colocadas
-
Son dos tablas particionadas que comparten la misma clave de partición y que se declaran como colocadas de forma explícita. Todos los datos del mismo valor de clave de partición se envían a la misma partición.
- Tabla de referencia
-
Es una tabla cuyos datos se copian en su totalidad en cada partición.
- Tabla estándar
-
Es el tipo de tabla predeterminado en Base de datos ilimitada. Puede convertir tablas estándar en tablas particionadas o de referencia.
Todas las tablas estándar se almacenan en la misma partición seleccionada por el sistema, lo que permite realizar uniones entre tablas estándar dentro de una única partición. Sin embargo, las tablas estándar están limitadas por la capacidad máxima de la partición (128 TiB). Esta partición también almacena datos de tablas particionadas y de referencia, por lo que el límite efectivo para las tablas estándar es inferior a 128 TiB.
Tipos de tabla de Base de datos ilimitada de Aurora PostgreSQL
Base de datos ilimitada de Aurora PostgreSQL admite tres tipos de tabla: particionada, de referencia y estándar.
Los datos de las tablas particionadas se distribuyen entre todas las particiones del grupo de particiones de base de datos. Base de datos ilimitada lo hace automáticamente con una clave de partición, que es una columna o un conjunto de columnas que se especifican al dividir la tabla. Todos los datos con el mismo valor de clave de partición se envían a la misma partición. La partición se basa en el hash, no en rangos o listas.
Los siguientes son buenos ejemplos de casos de uso de tablas particionadas:
-
La aplicación funciona con un subconjunto de datos distinto.
-
El archivo de tabla es muy grande.
-
Es posible que la tabla crezca más rápido que otras tablas.
Las tablas particionadas se pueden colocar, lo que significa que comparten la misma clave de partición y que todos los datos de ambas tablas con el mismo valor de clave de partición se envían a la misma partición. Si coloca las tablas y las une con la clave de partición, la unión se puede realizar en una sola partición, ya que todos los datos necesarios están presentes en esa partición.
Las tablas de referencia tienen una copia completa de todos los datos de cada partición del grupo de particiones de base de datos. Las tablas de referencia se suelen utilizar para tablas más pequeñas con un volumen de escritura más bajo, pero aun así es necesario unirlas con frecuencia y no se prestan a la partición. Entre los ejemplos de tablas de referencia se incluyen las tablas de fechas y las tablas de datos geográficos, como estados, ciudades y códigos postales.
Las tablas estándar son el tipo de tabla predeterminado en Base de datos ilimitada de Aurora PostgreSQL. No son tablas distribuidas. Base de datos ilimitada de Aurora PostgreSQL admite uniones entre tablas estándar y tablas estándar, particionadas y de referencia.
Facturación de Base de datos ilimitada de Aurora PostgreSQL
Para obtener más información sobre cómo se cobra por Base de datos ilimitada de Aurora PostgreSQL, consulte Facturación de instancia de base de datos para Aurora.
Para obtener información acerca de los precios de Aurora, consulte la página de precios de Aurora
