Uso de la utilidad de carga de datos de Base de datos ilimitada de Aurora PostgreSQL
Aurora proporciona una utilidad para cargar datos directamente en Base de datos ilimitada desde un clúster de base de datos de Aurora PostgreSQL o desde una instancia de base de datos de RDS para PostgreSQL.
Siga los siguientes pasos para utilizar la utilidad de carga de datos:
Limitaciones
La utilidad de carga de datos tiene las siguientes limitaciones:
-
No se admiten los siguientes tipos de datos:
enum,ARRAY,BOX,CIRCLE,LINE,LSEG,PATH,PG_LSN,PG_SNAPSHOT,POLYGON,TSQUERY,TSVECTORyTXID_SNAPSHOT. -
Los ceros iniciales (
0) se eliminan del tipo de datosVARBITdurante la carga. -
La migración de datos falla si hay claves primarias compuestas en las tablas de origen.
-
La migración de datos falla cuando hay claves externas en las tablas de destino.
-
No se admite la carga de datos desde clústeres de bases de datos Multi-AZ de RDS para PostgreSQL.
Requisitos previos
La utilidad de carga de datos tiene los siguientes requisitos previos:
-
La base de datos de origen utiliza Aurora PostgreSQL o RDS para PostgreSQL versión 11.x y posteriores.
-
La base de datos de origen se encuentra en la misma Cuenta de AWS y Región de AWS que el grupo de particiones de base de datos de destino.
-
El clúster de base de datos o la instancia de base de datos de origen tienen el estado
available. -
Las tablas de la base de datos de origen y de la base de datos ilimitada tienen los mismos nombres de tabla, nombres de columnas y tipos de datos de columna.
-
Las tablas de origen y destino tienen claves principales que utilizan las mismas columnas y el mismo orden de columnas.
-
Debe disponer de un entorno para conectarse a una base de datos ilimitada para ejecutar comandos de carga de datos. Los comandos disponibles son los siguientes:
-
rds_aurora.limitless_data_load_start -
rds_aurora.limitless_data_load_cancel
-
-
Para CDC:
-
Tanto la base de datos de origen como el grupo de particiones de base de datos de destino deben usar el mismo grupo de subredes de base de datos, el mismo grupo de seguridad de VPC y el mismo puerto de base de datos. Estas configuraciones son para las conexiones de red tanto a la base de datos de origen como a los enrutadores del grupo de particiones de base de datos.
-
Debe activar la replicación lógica en la base de datos de origen. El usuario de la base de datos de origen debe tener privilegios para leer la replicación lógica.
-
Preparación de la base de datos de origen
Para acceder a la base de datos de origen para cargar datos, debe permitir la entrada de tráfico de red. Siga estos pasos.
Cómo permitir el acceso del tráfico de red a la base de datos de origen
Inicie sesión en la AWS Management Console y abra la consola de Amazon EC2 en https://console.aws.amazon.com/ec2/
. -
Navegue a la página Grupos de seguridad.
-
Elija ID de grupo de seguridad para el grupo de seguridad utilizado por la instancia o el clúster de base de datos de origen.
Por ejemplo, el ID de grupo de seguridad es
sg-056a84f1712b77926. -
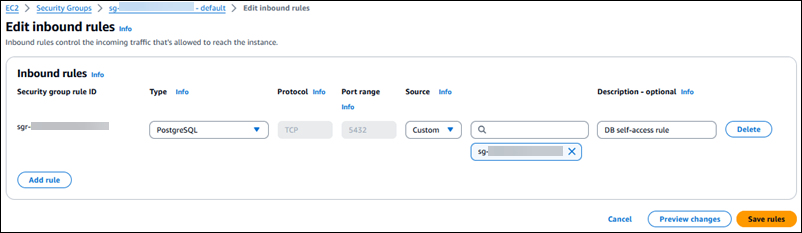
Vaya a la pestaña Reglas de entrada:
-
Elija Editar reglas de entrada.
-
Agregue una nueva regla de entrada para la instancia o el clúster de base de datos de origen:
-
Rango de puertos: puerto de base de datos para la base de datos de origen, normalmente
5432 -
ID de grupo de seguridad:
sg-056a84f1712b77926en este ejemplo
-
-
-
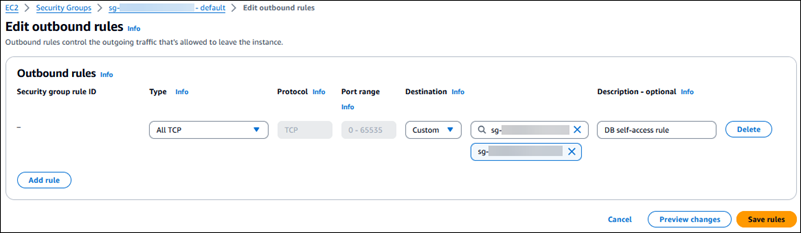
En la pestaña Reglas de salida:
-
Elija Edit outbound rules.
-
Agregue una nueva regla de salida para la instancia o el clúster de base de datos de origen:
-
Puerto de base de datos:
All traffic(incluye los puertos0-65535) -
ID de grupo de seguridad:
sg-056a84f1712b77926en este ejemplo
-
-
Inicie sesión en la AWS Management Console y abra la consola de Amazon VPC en https://console.aws.amazon.com/vpc/
. -
Navegue a la página ACL de red.
-
Agregue la configuración de ACL de red predeterminada tal como se describe en la ACL de red predeterminada.
Preparación de la base de datos de destino
Siga los procedimientos descritos en Creación de tablas de Base de datos ilimitada de Aurora PostgreSQL para crear las tablas de destino en el grupo de particiones de base de datos.
Las tablas de destino deben tener los mismos esquemas, nombres de tabla y claves principales que las tablas de origen.
Creación de credenciales de la base de datos
Debe crear usuarios de bases de datos en las bases de datos de origen y destino y conceder los privilegios necesarios a los usuarios. Para obtener más información, consulte CREATE USER
Creación de las credenciales de la base de datos de origen
El usuario de la base de datos de origen se pasa en el comando para iniciar la carga. El usuario debe tener privilegios para ejecutar la replicación desde la base de datos de origen.
-
Utilice el usuario maestro de la base de datos (u otro usuario con el rol
rds_superuser) para crear un usuario de la base de datos de origen con privilegiosLOGIN.CREATE USERsource_db_usernameWITH PASSWORD 'source_db_user_password'; -
Otorgue el rol
rds_superuseral usuario de la base de datos de origen.GRANT rds_superuser tosource_db_username; -
Si utiliza el modo
full_load_and_cdc, otorgue el rolrds_replicational usuario de la base de datos de origen. El rol derds_replicationconcede permisos para administrar ranuras lógicas y para transmitir datos mediante ranuras lógicas.GRANT rds_replication tosource_db_username;
Creación de las credenciales de la base de datos de destino
El usuario de la base de datos de destino debe tener permiso para escribir en las tablas de destino del grupo de particiones de base de datos.
-
Utilice el usuario maestro de la base de datos (u otro usuario con el rol
rds_superuser) para crear un usuario de la base de datos de destino con privilegiosLOGIN.CREATE USERdestination_db_usernameWITH PASSWORD 'destination_db_user_password'; -
Otorgue el rol
rds_superuseral usuario de la base de datos de destino.GRANT rds_superuser todestination_db_username;
