Interbloqueos distribuidos en Base de datos ilimitada de Aurora PostgreSQL
En un grupo de particiones de base de datos, pueden producirse interbloqueos entre transacciones distribuidas entre distintos enrutadores y particiones. Por ejemplo, se ejecutan dos transacciones distribuidas simultáneas que abarcan dos particiones, tal y como se muestra en la siguiente figura.
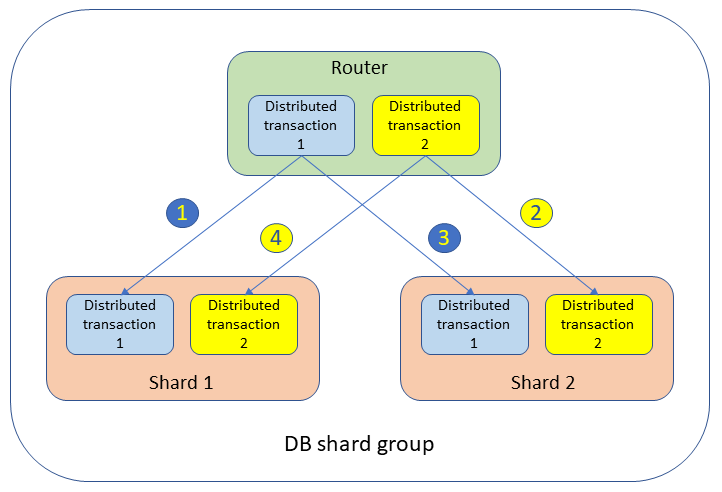
Las transacciones bloquean las tablas y crean eventos de espera en las dos particiones de la siguiente manera:
-
Transacción distribuida 1:
UPDATEtableSETvalue= 1 WHERE key = 'shard1_key';Esta acción coloca un bloqueo en la partición 1.
-
Transacción distribuida 2:
UPDATEtableSETvalue= 2 WHERE key = 'shard2_key';Esta acción coloca un bloqueo en la partición 2.
-
Transacción distribuida 1:
UPDATEtableSETvalue= 3 WHERE key = 'shard2_key';La transacción distribuida 1 está esperando la partición 2.
-
Transacción distribuida 2:
UPDATEtableSETvalue= 4 WHERE key = 'shard1_key';La transacción distribuida 2 está esperando la partición 1.
En este escenario, ni la partición 1 ni la partición 2 ven el problema: la transacción 1 espera la transacción 2 de la partición 2 y la transacción 2 espera la transacción 1 de la partición 1. Desde una perspectiva global, la transacción 1 espera la transacción 2 y la transacción 2 espera la transacción 1. Esta situación en la que dos transacciones de dos particiones diferentes se esperan una a la otra se denomina interbloqueo distribuido.
Base de datos ilimitada de Aurora PostgreSQL puede detectar y resolver los interbloqueos distribuidos automáticamente. Cuando una transacción tarda demasiado tiempo en adquirir un recurso, se notifica a un enrutador del grupo de particiones de base de datos. El enrutador que recibe la notificación comienza a recopilar la información necesaria de todos los enrutadores y particiones del grupo de particiones de base de datos. A continuación, el enrutador finaliza las transacciones que participan en un interbloqueo distribuido, hasta que el resto de las transacciones del grupo de particiones de base de datos pueda continuar sin que se bloqueen entre sí.
Recibe el siguiente error si la transacción formaba parte de un interbloqueo distribuido y, a continuación, el enrutador la ha finalizado:
ERROR: aborting transaction participating in a distributed deadlock
El parámetro del clúster de base de datos rds_aurora.limitless_distributed_deadlock_timeout establece el tiempo que debe esperar cada transacción en un recurso antes de notificar al enrutador que compruebe si hay un interbloqueo distribuido. Puede aumentar el valor del parámetro si su carga de trabajo es menos propensa a sufrir situaciones de interbloqueo. El valor predeterminado es de 1000 milisegundos (un segundo).
El ciclo de interbloqueo distribuido se publica en los registros de PostgreSQL cuando se encuentra y se resuelve un interbloqueo entre nodos. La información sobre cada proceso que forma parte del interbloqueo incluye lo siguiente:
-
Nodo coordinador que ha iniciado la transacción
-
ID de transacción virtual (xid) de la transacción en el nodo coordinador con el formato
backend_id/backend_local_xid -
ID de sesión distribuido de la transacción
