Registro del tráfico de IP con registros de flujo de la VPC
Los logs de flujo de VPC son una característica que permite capturar información acerca del tráfico IP que entra y sale de las interfaces de red en la VPC. Los datos del registro de flujo se pueden publicar en las siguientes ubicaciones: Registros de Amazon CloudWatch, Amazon S3 o Amazon Data Firehose. Una vez creado un registro de flujo, puede recuperarlo y ver las entradas del registro de flujo en el grupo de registro, el bucket o el flujo de entrega que configuró.
Los logs de flujo pueden ayudarlo en una serie de tareas, tales como:
-
Diagnosticar reglas de grupo de seguridad muy restrictivas
-
Supervisar el tráfico que llega a su instancia
-
Determinar la dirección del tráfico hacia y desde las interfaces de red
Los datos de registro de flujo se recopilan fuera de la ruta del tráfico de red y, por lo tanto, no afectan al rendimiento ni a la latencia de la red. Puede crear o eliminar registros de flujo sin ningún riesgo de impacto en el rendimiento de la red.
Contenido
- Conceptos básicos de logs de flujo
- Registros de log de flujo
- Ejemplos de registros de log de flujo
- Limitaciones de los logs de flujo
- Precios
- Trabajo con registros de flujo
- Publicar registros de flujo en CloudWatch Logs
- Publicar registros de flujo en Amazon S3
- Publicar registros de flujo a Amazon Data Firehose
- Realizar consultas en los registros de flujo mediante Amazon Athena
- Solucionar problemas de los registros de flujo de VPC
Conceptos básicos de logs de flujo
Puede crear un log de flujo para una VPC, una subred o una interfaz de red. Si crea un log de flujo para una subred o VPC, se supervisará cada interfaz de red de la VPC o la subred.
Los datos de logs de flujo de una interfaz de red supervisada se registran como registros de logs de flujo, que son eventos de registro que constan de campos que describen el flujo de tráfico. Para obtener más información, consulte Registros de log de flujo.
Para crear un registro de flujo, especifique:
-
El recurso para el que desea crear el log de flujo
-
El tipo de tráfico que capturar (tráfico aceptado, tráfico rechazado o todo el tráfico)
-
Los destinos a los que desea publicar los datos de log de flujo
En el ejemplo siguiente, se crea una entrada de registro que captura el tráfico aceptado para la interfaz de red de una de las instancias EC2 en una subred privada y publica las entradas de registro de flujo en un bucket de Amazon S3.
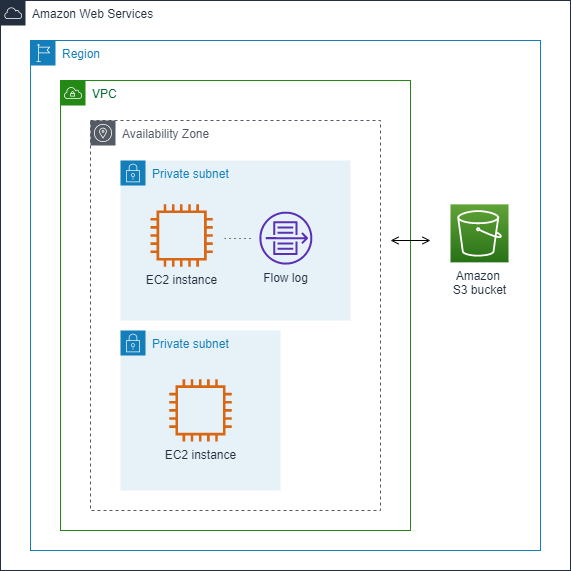
En el siguiente ejemplo una entrada de registro de flujo captura todo el tráfico de la subred y publica las entradas de registro de flujo en los Registros de Amazon CloudWatch. El registro de flujo captura el tráfico de todas las interfaces de red de la subred.
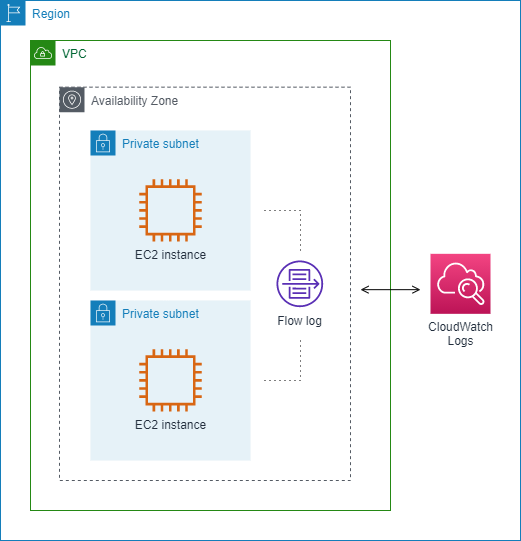
Después de crear un registro de flujo, pueden transcurrir varios minutos hasta que se empiecen a recopilar datos y a publicarse en los destinos elegidos. Los logs de flujo no capturan los flujos de logs en tiempo real de las interfaces de red. Para obtener más información, consulte Crear un log de flujo.
Si lanza una instancia en la subred después de haber creado un registro de flujo para la subred o la VPC, creamos un nuevo flujo de registros (para CloudWatch Logs) o un objeto de archivo de registros (para Amazon S3) para la nueva interfaz de red apenas haya tráfico de red para la interfaz de red.
Puede crear registros de flujo para interfaces de red creadas por otros servicios de AWS, tales como:
-
Elastic Load Balancing
-
Amazon RDS
-
Amazon ElastiCache
-
Amazon Redshift
-
Amazon WorkSpaces
-
Gateways NAT
-
Transit puerta de enlaces
Con independencia del tipo de interfaz de red, debe utilizar la consola de Amazon EC2 o la API de Amazon EC2 para crear un registro de flujo para una interfaz de red.
Puede aplicar etiquetas a los registros de flujo. Cada etiqueta está formada por una clave y un valor opcional, ambos definidos por el usuario. Las etiquetas pueden ayudarlo a organizar los registros de flujo, por ejemplo, por finalidad o propietario.
Si ya no necesita un log de flujo, puede eliminarlo. Al eliminar un registro de flujo, se deshabilita el servicio del registro de flujo para el recurso, de modo que no se creen ni se publiquen nuevas entradas de registros de flujo. La eliminación de un registro de flujo no elimina ningún dato de registro de flujo existente. Tras eliminar un registro de flujo, puede eliminar los datos del registro de flujo directamente desde el destino cuando haya terminado con él. Para obtener más información, consulte Eliminar un registro de flujo.
Registros de log de flujo
Un registro de log de flujo representa un flujo de red en su VPC. De forma predeterminada, cada registro captura un flujo de tráfico del protocolo de Internet (IP) de red (caracterizado por 5 tuplas para cada interfaz de red) que tiene lugar dentro de un intervalo de agregación, lo también se conoce como período de captura.
Cada registro es una cadena con campos separados por espacios. Un registro incluye valores para los distintos componentes del flujo de IP, por ejemplo, el origen, el destino y el protocolo.
Al crear un registro de flujo, puede utilizar el formato predeterminado para el registro del registro de flujo o puede especificar un formato personalizado.
Intervalo de agregación
El intervalo de agregación es el período de tiempo durante el que se captura un flujo determinado y se agrega a un registro de flujo. De forma predeterminada, el intervalo de agregación máximo es de 10 minutos. Cuando cree un registro de flujo, si lo desea, puede especificar un intervalo máximo de agregación de 1 minuto. Los registros de flujo con un intervalo de agregación máximo de 1 minuto producen un volumen mayor de registros que los que tienen un intervalo de agregación máximo de 10 minutos.
Cuando una interfaz de red está asociada a una instancia basada en Nitro, el intervalo de agregación siempre es igual o inferior a 1 minuto, independientemente del intervalo de agregación máximo especificado.
Una vez que los datos se han capturado durante el intervalo de agregación, se necesita más tiempo para procesarlos y publicarlos en CloudWatch Logs o Amazon S3. El servicio de registros de flujo suele entregar registros a CloudWatch Logs en unos 5 minutos y a Amazon S3 en unos 10 minutos. No obstante, aunque se hace todo lo posible para realizar la entrega de los registros, puede que se produzcan retrasos y se necesite más tiempo del habitual para entregarlos.
Formato predeterminado
Con el formato predeterminado, los registros del log de flujo incluyen los campos de la versión 2, en el orden mostrado en la tabla de campos disponibles. No puede personalizar o cambiar el formato predeterminado. Para capturar los campos adicionales o un subconjunto de campos distinto, especifique un formato personalizado.
Formato personalizado
Con un formato personalizado, especifique qué campos se incluyen en los registros del log de flujo y en qué orden. De este modo, puede crear registros de flujo específicos con arreglo a sus necesidades y omitir los campos que no resulten relevantes. El uso de un formato personalizado puede reducir la necesidad de procesos separados para extraer información específica de logs de flujo publicados. Puede especificar cualquier número de campos de log de flujo disponibles, pero debe especificar al menos uno.
Campos disponibles
La tabla siguiente describe todos los campos disponibles para un registro de logs de flujo. La columna Version (Versión) indica la versión de los registros de flujo de VPC en la que se introdujo el campo. El formato predeterminado incluye todos los campos de la versión 2, en el mismo orden en que aparecen en la tabla.
Al publicar datos de registro de flujo en Amazon S3, el tipo de datos de los campos depende del formato del registro de flujo. Si el formato es texto sin formato, todos los campos son de tipo STRING. Si el formato es Parquet, consulte la tabla de los tipos de datos de campo.
Si un campo no es aplicable o no se pudo calcular para un registro específico, el registro muestra un símbolo “-” en esa entrada. Los campos de metadatos que no provienen directamente del encabezado del paquete son aproximaciones de mejor esfuerzo y sus valores pueden faltar o ser inexactos.
| Campo | Descripción | Versión |
|---|---|---|
|
version |
La versión de los registros de flujo de VPC. Si utiliza el formato predeterminado, la versión es 2. Si utiliza un formato personalizado, la versión es la más alta entre los campos especificados. Por ejemplo, si especifica sólo campos de la versión 2, la versión es 2. Si especifica una combinación de campos de las versiones 2, 3 y 4, la versión es 4. Tipo de datos de Parquet: INT_32 |
2 |
|
account-id |
El ID de la cuenta de AWS del propietario de la interfaz de red de origen en la que se registra el tráfico. Si un servicio de AWS crea la interfaz de red, por ejemplo, al momento de crear un punto de conexión de VPC o Network Load Balancer, el registro puede mostrar unknown para este campo. Tipo de datos de Parquet: STRING |
2 |
|
interface-id |
El ID de la interfaz de red para la que se registra el tráfico. Tipo de datos de Parquet: STRING |
2 |
|
srcaddr |
La dirección de origen para tráfico entrante o la dirección IPv4 o IPv6 de la interfaz de red para tráfico saliente en la interfaz de red. La dirección IPv4 de la interfaz de red es siempre su dirección IPv4 privada. Véase también pkt-srcaddr. Tipo de datos de Parquet: STRING |
2 |
|
dstaddr |
La dirección de destino para tráfico saliente o la dirección IPv4 o IPv6 de la interfaz de red para tráfico entrante en la interfaz de red. La dirección IPv4 de la interfaz de red es siempre su dirección IPv4 privada. Véase también pkt-dstaddr. Tipo de datos de Parquet: STRING |
2 |
|
srcport |
El puerto de origen del tráfico. Tipo de datos de Parquet: INT_32 |
2 |
|
dstport |
El puerto de destino del tráfico. Tipo de datos de Parquet: INT_32 |
2 |
|
protocol |
El número de protocolo IANA del tráfico. Para obtener más información, consulte Números de protocolo asignados en internet Tipo de datos de Parquet: INT_32 |
2 |
|
packets |
El número de paquetes transferidos durante el flujo. Tipo de datos de Parquet: INT_64 |
2 |
|
bytes |
El número de bytes transferidos durante el flujo. Tipo de datos de Parquet: INT_64 |
2 |
|
start |
Momento, en segundos Unix, en que se recibió el primer paquete del flujo dentro del intervalo de agregación. El tiempo transcurrido puede ser como máximo de 60 segundos una vez que el paquete se ha transmitido o recibido en la interfaz de red. Tipo de datos de Parquet: INT_64 |
2 |
|
end |
Momento, en segundos Unix, en que se recibió el último paquete del flujo dentro del intervalo de agregación. El tiempo transcurrido puede ser como máximo de 60 segundos una vez que el paquete se ha transmitido o recibido en la interfaz de red. Tipo de datos de Parquet: INT_64 |
2 |
|
action |
La acción asociada al tráfico:
Tipo de datos de Parquet: STRING |
2 |
|
log-status |
El estado de registro del registro de flujo:
Tipo de datos de Parquet: STRING |
2 |
|
vpc-id |
El ID de la VPC que contiene la interfaz de red para la que se registra el tráfico. Tipo de datos de Parquet: STRING |
3 |
|
subnet-id |
El ID de la subred que contiene la interfaz de red para la que se registra el tráfico. Tipo de datos de Parquet: STRING |
3 |
|
instance-id |
El ID de la instancia que está asociado a la interfaz de red para la que se registra el tráfico, si la instancia es de su propiedad. Devuelve un símbolo "-" para una interfaz de red administrada por el solicitante; por ejemplo, la interfaz de red para una puerta de enlace NAT. Tipo de datos de Parquet: STRING |
3 |
|
tcp-flags |
El valor de máscara de bits de las siguientes marcas TCP:
-. Si no se envían marcadores, el valor del marcador TCP es 0.Se puede aplicar OR a las marcas TCP durante el intervalo de agregación. Para conexiones breves, los marcadores se pueden establecer en la misma línea en el registro de flujo, por ejemplo 19 para SYN-ACK y FIN y 3 para SYN y FIN. Para ver un ejemplo, consulte Secuencia de marca TCP. Para obtener información general sobre marcadores TCP (como el significado de marcadores como FIN, SYN y ACK), consulte TCP segment structure Tipo de datos de Parquet: INT_32 |
3 |
|
type |
El tipo de tráfico. Los valores posibles son IPv4 | IPv6 | EFA. Para obtener más información, consulte Elastic Fabric Adapter. Tipo de datos de Parquet: STRING |
3 |
|
pkt-srcaddr |
La dirección IP de origen (original) del nivel de paquete del tráfico. Utilice este campo con el campo srcaddr para distinguir entre la dirección IP de una capa intermedia a través de la que fluye el tráfico y la dirección IP de origen original del tráfico. Por ejemplo, cuando el tráfico fluye a través de una interfaz de red para una puerta de enlace NAT o si la dirección IP de un pod de Amazon EKS es distinta de la dirección IP de la interfaz de red del nodo de instancia en el que se ejecuta el pod (para permitir la comunicación dentro de una VPC). Tipo de datos de Parquet: STRING |
3 |
|
pkt-dstaddr |
La dirección IP de destino (original) del nivel de paquete para el tráfico. Utilice este campo con el campo dstaddr para distinguir entre la dirección IP de una capa intermedia a través de la que fluye el tráfico y la dirección IP de destino final del tráfico. Por ejemplo, cuando el tráfico fluye a través de una interfaz de red para una puerta de enlace NAT o si la dirección IP de un pod de Amazon EKS es distinta de la dirección IP de la interfaz de red del nodo de instancia en el que se ejecuta el pod (para permitir la comunicación dentro de una VPC). Tipo de datos de Parquet: STRING |
3 |
|
region |
La región que contiene la interfaz de red para la que se registra el tráfico. Tipo de datos de Parquet: STRING |
4 |
|
az-id |
El ID de la zona de disponibilidad que contiene la interfaz de red para la que se registra el tráfico. Si el tráfico procede de una ubicación secundaria, el registro muestra un símbolo '-' en este campo. Tipo de datos de Parquet: STRING |
4 |
|
sublocation-type |
El tipo de ubicación secundaria que se devuelve en el sublocation-id campo. Los valores posibles son: longitud de onda Tipo de datos de Parquet: STRING |
4 |
|
sublocation-id |
El ID de la ubicación secundaria que contiene la interfaz de red para la que se registra el tráfico. Si el tráfico no procede de una ubicación secundaria, el registro muestra un símbolo '-' en este campo. Tipo de datos de Parquet: STRING |
4 |
|
pkt-src-aws-service |
El nombre del subconjunto de intervalos de direcciones IP para el campo pkt-srcaddr, si la dirección IP de origen está destinada a un servicio de AWS. Los valores posibles son AMAZON | AMAZON_APPFLOW | AMAZON_CONNECT | API_GATEWAY | CHIME_MEETINGS | CHIME_VOICECONNECTOR | CLOUD9 | CLOUDFRONT | CODEBUILD | DYNAMODB | EBS | EC2 | EC2_INSTANCE_CONNECT | GLOBALACCELERATOR | KINESIS_VIDEO_STREAMS | ROUTE53 | ROUTE53_HEALTHCHECKS | ROUTE53_HEALTHCHECKS_PUBLISHING | ROUTE53_RESOLVER | S3 | WORKSPACES_GATEWAYS. Tipo de datos de Parquet: STRING |
5 |
|
pkt-dst-aws-service |
El nombre del subconjunto de intervalos de direcciones IP para el campo pkt-dstaddr, si la dirección IP de destino está destinada a un servicio de AWS. Para obtener una lista de posibles valores, consulte el campo pkt-src-aws-service. Tipo de datos de Parquet: STRING |
5 |
|
flow-direction |
La dirección del flujo con respecto a la interfaz donde se captura el tráfico. Los valores posibles son: ingress | egress. Tipo de datos de Parquet: STRING |
5 |
|
traffic-path |
La ruta que el tráfico de salida toma al destino. Para determinar si el tráfico es de salida, marque el flow-direction campo. Los valores posibles son los siguientes: Si no se aplica ninguno de los valores, el campo se establece en -.
Tipo de datos de Parquet: INT_32 |
5 |
Limitaciones de los logs de flujo
Para utilizar los logs de flujo, debe conocer las siguientes limitaciones:
-
No se pueden habilitar los logs de flujo para VPC interconectadas con su VPC a menos que la VPC del mismo nivel se encuentre en su cuenta.
-
Después de haber creado un registro de flujo, no puede cambiar su configuración ni el formato de registro de los registros de flujo. Por ejemplo, no puede asociar un rol de IAM diferente con el registro de flujo ni agregar o quitar campos en la entrada de registro de flujo. En su lugar, puede eliminar el log de flujo y crear uno nuevo con la configuración necesaria.
-
Si su interfaz de red tiene varias direcciones IPv4 y el tráfico se envía a una dirección IPv4 privada secundaria, el log de flujo mostrará la dirección IPv4 privada principal en el campo
dstaddr. Para capturar la dirección IP de destino original, cree un log de flujo con el campopkt-dstaddr. -
Si el tráfico se envía a una interfaz de red y el destino no es ninguna de las direcciones IP de la interfaz de red, el log de flujo muestra la dirección IPv4 privada principal en el campo
dstaddr. Para capturar la dirección IP de destino original, cree un log de flujo con el campopkt-dstaddr. -
Si el tráfico se envía a una interfaz de red y el origen no es ninguna de las direcciones IP de la interfaz de red, el log de flujo muestra la dirección IPv4 privada principal en el campo
srcaddr. Para capturar la dirección IP de origen original, cree un log de flujo con el campopkt-srcaddr. -
Si el tráfico se envía a una interfaz de red o desde una interfaz de red, los campos
srcaddrydstaddrdel registro de flujo muestran siempre la dirección IPv4 privada principal, con independencia del origen o destino del paquete. Para capturar el origen o destino del paquete, cree un log de flujo con los campospkt-srcaddrypkt-dstaddr. -
Cuando la interfaz de red está asociada a una instancia basada en Nitro, el intervalo de agregación siempre es igual o menor a 1 minuto, independientemente del intervalo máximo de agregación especificado.
Los logs de flujo no capturan todo el tráfico IP. Los siguientes tipos de tráfico no se registran:
-
Tráfico generado por instancias al contactar con el servidor DNS de Amazon. Si utiliza su propio servidor DNS, sí se registrará el tráfico a ese servidor DNS.
-
Tráfico generado por una instancia de Windows para la activación de licencia de Windows para Amazon.
-
Tráfico entrante y saliente de
169.254.169.254para metadatos de instancias. -
Tráfico entrante y saliente de
169.254.169.123para el Servicio de sincronización temporal de Amazon. -
Tráfico DHCP.
-
Tráfico reflejado.
-
Tráfico a la dirección IP reservada para el router VPC predeterminado.
-
El tráfico entre una interfaz de red de punto de enlace y una interfaz de red de Network Load Balancer.
Precios
Se aplican costos por archivo e ingesta de datos para los registros distribuidos cuando se publican registros de flujo. Para obtener más información acerca de los precios de publicación de registros distribuidos, abra Precios de Amazon CloudWatch
Para realizar un seguimiento de los cargos de publicación de los registros de flujo, puede aplicar etiquetas de asignación de costos al recurso de destino. A partir de entonces, el informe de asignación de costos de AWS incluirá el uso y los costos agregados por estas etiquetas. Puede aplicar etiquetas que representen categorías de negocio (por ejemplo, centros de costos, nombres de aplicación o propietarios) para organizar los costos. Para más información, consulte los siguientes temas:
-
Uso de etiquetas de asignación de costos en la Guía del usuario de AWS Billing.
-
Etiquetado de grupos de registro de Amazon CloudWatch en la Guía del usuario de Amazon CloudWatch Logs
-
Uso de etiquetas de buckets de S3 de asignación de costos en la Guía del usuario de Amazon Simple Storage Service
-
Etiquetado de flujos de entrega en la Guía para desarrolladores de Amazon Data Firehose
