Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Crear un informe de evaluación multiservidor en AWS Schema Conversion Tool
Determine la mejor dirección de destino para su entorno general, cree un informe de evaluación multiservidor.
Un informe de evaluación multiservidor evalúa varios servidores en función de los datos que proporcione para cada definición de esquema que desee evaluar. La definición del esquema contiene los parámetros de conexión al servidor de la base de datos y el nombre completo de cada esquema. Tras evaluar cada esquema, AWS SCT elabora un informe de evaluación resumido y agregado para la migración de bases de datos entre varios servidores. Este informe muestra la complejidad estimada de cada posible objetivo de migración.
Puede utilizarlo AWS SCT para crear un informe de evaluación multiservidor para las siguientes bases de datos de origen y destino.
| Base de datos de origen | Bases de datos de destino |
|---|---|
|
Amazon Redshift |
Amazon Redshift |
|
Base de datos SQL Azure |
Aurora MySQL, Aurora PostgreSQL, MySQL, PostgreSQL |
|
Azure Synapse Analytics |
Amazon Redshift |
|
BigQuery |
Amazon Redshift |
|
Greenplum |
Amazon Redshift |
|
IBM Db2 para z/OS |
Amazon Aurora MySQL-Compatible Edition (Aurora MySQL), Amazon Aurora PostgreSQL-Compatible Edition (Aurora PostgreSQL), MySQL, PostgreSQL |
|
IBM Db2 LUW |
Aurora MySQL, Aurora PostgreSQL, MariaDB, MySQL, PostgreSQL |
|
Microsoft SQL Server |
Aurora MySQL, Aurora PostgreSQL, Amazon Redshift, Babelfish para Aurora PostgreSQL, MariaDB, Microsoft SQL Server, MySQL, PostgreSQL |
|
MySQL |
Aurora PostgreSQL, MySQL, PostgreSQL |
|
Netezza |
Amazon Redshift |
|
Oracle |
Aurora MySQL, Aurora PostgreSQL, Amazon Redshift, MariaDB, MySQL, Oracle, PostgreSQL |
|
PostgreSQL |
Aurora MySQL, Aurora PostgreSQL, MySQL, PostgreSQL |
|
SAP ASE |
Aurora MySQL, Aurora PostgreSQL, MariaDB, MySQL, PostgreSQL |
|
Snowflake |
Amazon Redshift |
|
Teradata |
Amazon Redshift |
|
Vertica |
Amazon Redshift |
Realización de una evaluación multiservidor
Utilice el siguiente procedimiento para realizar una evaluación multiservidor con. AWS SCT No es necesario crear un proyecto nuevo AWS SCT para realizar una evaluación multiservidor. Antes de empezar, prepare un archivo de valores separados por comas (CSV) con los parámetros de conexión a la base de datos. Además, instale todos los controladores de base de datos necesarios y establezca la ubicación de los controladores en la configuración de AWS SCT . Para obtener más información, consulte Instalación de controladores JDBC para AWS Schema Conversion Tool.
Para realizar una evaluación multiservidor y crear un informe resumido agregado
-
En AWS SCT, elija Archivo, Nueva evaluación multiservidor. Se abre el cuadro de diálogo Evaluación multiservidor nueva.
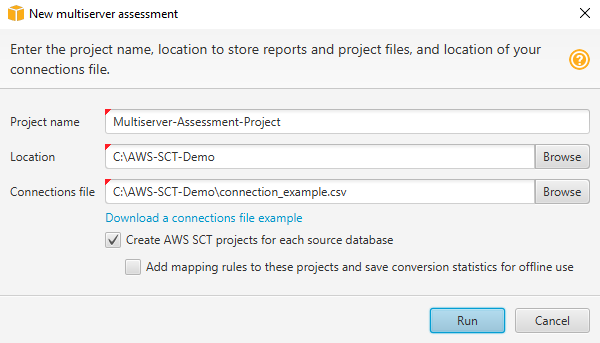
-
Seleccione Descargar un ejemplo de archivo de conexiones para descargar una plantilla vacía de un archivo CSV con los parámetros de conexión a la base de datos.
-
Introduzca los valores para Nombre del proyecto, Ubicación (para almacenar los informes) y Archivo de conexiones (un archivo CSV).
-
Elija Crear AWS SCT proyectos para cada base de datos de origen para crear automáticamente los proyectos de migración después de generar el informe de evaluación.
-
Con la opción Crear AWS SCT proyectos para cada base de datos fuente activada, puede elegir Añadir reglas de mapeo a estos proyectos y guardar las estadísticas de conversión para utilizarlas sin conexión. En este caso, AWS SCT añadirá reglas de mapeo a cada proyecto y guardará los metadatos de la base de datos fuente en el proyecto. Para obtener más información, consulte Uso del modo fuera de línea en AWS Schema Conversion Tool.
-
Elija Ejecutar.
Aparece una barra de progreso que indica el ritmo de la evaluación de la base de datos. La cantidad de motores de destino puede afectar al tiempo de ejecución de la evaluación.
-
Elija Sí si aparece el siguiente mensaje: El análisis completo de todos los servidores de bases de datos puede tardar algún tiempo. ¿Desea continuar?
Una vez elaborado el informe de evaluación multiservidor, aparecerá una pantalla que lo indica.
-
Elija Abrir informe para ver el informe de evaluación resumido agregado.
De forma predeterminada, AWS SCT genera un informe agregado para todas las bases de datos fuente y un informe de evaluación detallado para cada nombre de esquema de una base de datos fuente. Para obtener más información, consulte Localización y visualización de informes.
Con la opción Crear AWS SCT proyectos para cada base de datos fuente activada, AWS SCT crea un proyecto vacío para cada base de datos fuente. AWS SCT también crea informes de evaluación tal como se describió anteriormente. Tras analizar estos informes de evaluación y elegir el destino de migración para cada base de datos de origen, agregue las bases de datos de destino a estos proyectos vacíos.
Con la opción Añadir reglas de mapeo a estos proyectos y guardar las estadísticas de conversión para su uso sin conexión a Internet, AWS SCT crea un proyecto para cada base de datos de origen. En estos proyectos se incluye la siguiente información:
Su base de datos de origen y una plataforma de base de datos de destino virtual. Para obtener más información, consulte Mapeo a objetivos virtuales en el AWS Schema Conversion Tool.
Una regla de asignación para este par origen-destino. Para obtener más información, consulte Asignación de tipos de datos.
Un informe de evaluación de la migración de la base de datos para este par origen-destino.
Metadatos del esquema de origen, que te permiten usar este AWS SCT proyecto sin conexión. Para obtener más información, consulte Uso del modo fuera de línea en AWS Schema Conversion Tool.
Preparación de un archivo CSV de entrada
Para proporcionar los parámetros de conexión como entrada para el informe de evaluación multiservidor, utilice un archivo CSV como se muestra en el ejemplo siguiente.
Name,Description,Secret Manager Key,Server IP,Port,Service Name,Database name,BigQuery path,Source Engine,Schema Names,Use Windows Authentication,Login,Password,Use SSL,Trust store,Key store,SSL authentication,Target Engines Sales,,,192.0.2.0,1521,pdb,,,ORACLE,Q4_2021;FY_2021,,user,password,,,,,POSTGRESQL;AURORA_POSTGRESQL Marketing,,,ec2-a-b-c-d.eu-west-1.compute.amazonaws.com,1433,,target_audience,,MSSQL,customers.dbo,,user,password,,,,,AURORA_MYSQL HR,,,192.0.2.0,1433,,employees,,MSSQL,employees.%,true,,,,,,,AURORA_POSTGRESQL Customers,,secret-name,,,,,,MYSQL,customers,,,,,,,,AURORA_POSTGRESQL Analytics,,,198.51.100.0,8195,,STATISTICS,,DB2LUW,BI_REPORTS,,user,password,,,,,POSTGRESQL Products,,,203.0.113.0,8194,,,,TERADATA,new_products,,user,password,,,,,REDSHIFT
En el ejemplo anterior, se utiliza un punto y coma para separar los dos nombres de esquema de la base de datos Sales. También se utiliza un punto y coma para separar las dos plataformas de migración de bases de datos de destino de la base de datos Sales.
Además, en el ejemplo anterior se utiliza la autenticación de Windows AWS Secrets Manager para conectarse a la Customers base de datos y la autenticación de Windows para conectarse a la HR base de datos.
Puede crear un archivo CSV nuevo o descargar una plantilla para un archivo CSV desde AWS SCT y completar la información requerida. Asegúrese de que la primera fila del archivo CSV incluya los mismos nombres de columna que se muestran en el ejemplo anterior.
Para descargar una plantilla del archivo CSV de entrada
Iniciar AWS SCT.
En Archivo, seleccione Evaluación multiservidor nueva.
Elija Descargar un ejemplo de archivo de conexiones.
Asegúrese de que el archivo CSV incluya los siguientes valores, proporcionados por la plantilla:
-
Nombre: la etiqueta de texto que ayuda a identificar la base de datos. AWS SCT muestra esta etiqueta de texto en el informe de evaluación.
-
Descripción: un valor opcional en el que puede proporcionar información adicional sobre la base de datos.
-
Clave de Secrets Manager: el nombre del secreto que almacena las credenciales de la base de datos en AWS Secrets Manager. Para usar Secrets Manager, asegúrate de guardar AWS los perfiles en AWS SCT. Para obtener más información, consulte Configurando AWS Secrets Manager en el AWS Schema Conversion Tool.
importante
AWS SCT ignora el parámetro Secret Manager Key si incluye los parámetros IP del servidor, puerto, inicio de sesión y contraseña en el archivo de entrada.
-
IP de servidor: escriba el nombre del servicio de nombres de dominio (DNS) o la dirección IP del servidor de la base de datos de origen.
-
Puerto: el puerto utilizado para conectarse al servidor de su base de datos de origen.
-
Nombre del servicio: si utiliza un nombre de servicio para conectarse a la base de datos de Oracle, el nombre del servicio de Oracle al que se va a conectar.
-
Nombre de la base de datos: el nombre de la base de datos. Para las bases de datos de Oracle, utilice el ID de sistema de Oracle (SID).
-
BigQuery ruta: la ruta al archivo de claves de la cuenta de servicio de la BigQuery base de datos de origen. Para obtener más información sobre la creación de este archivo, consulte Privilegios BigQuery como fuente.
-
Motor de origen: el tipo de base de datos de origen. Utilice uno de los siguientes valores:
AZURE_MSSQL para una base de datos de Azure SQL.
AZURE_SYNAPSE para una base de datos de Azure Synapse Analytics.
GOOGLE_BIGQUERY para una base de datos. BigQuery
DB2ZOS para una base de datos IBM Db2 for z/OS.
DB2LUW para una base de datos LUW de IBM Db2.
GREENPLUM para una base de datos de Greenplum.
MSSQL para una base de datos de Microsoft SQL Server.
MYSQL para una base de datos de MySQL.
NETEZZA para una base de datos de Netezza.
ORACLE para una base de datos de Oracle.
POSTGRESQL para una base de datos de PostgreSQL.
REDSHIFT para una base de datos de Amazon Redshift.
SNOWFLAKE para una base de datos de Snowflake.
SYBASE_ASE para una base de datos de SAP ASE.
TERADATA para una base de datos de Teradata.
VERTICA para una base de datos de Vertica.
-
Nombres de esquemas: los nombres de los esquemas de bases de datos que se van a incluir en el informe de evaluación.
Para Azure SQL Database, Azure Synapse Analytics, Netezza BigQuery, SAP ASE, Snowflake y SQL Server, utilice el siguiente formato de nombre de esquema:
db_name.schema_nameSustituya
db_nameSustituya
schema_nameIncluya los nombres de las bases de datos o los esquemas que incluyan un punto entre comillas dobles como se muestra a continuación:
"database.name"."schema.name".Separe los nombres de varios esquemas mediante punto y coma como se muestra a continuación:
Schema1;Schema2.Los nombres de las base de datos y los esquemas distinguen entre mayúsculas y minúsculas.
Utilice el porcentaje (
%) como carácter comodín para reemplazar los símbolos del nombre de la base de datos o del esquema. El ejemplo anterior utiliza el porcentaje (%) como carácter comodín para incluir todos los esquemas de la base de datosemployeesen el informe de evaluación. -
Usar autenticación de Windows: si utiliza la autenticación de Windows para conectarse a la base de datos de Microsoft SQL Server, introduzca true. Para obtener más información, consulte Uso de la autenticación de Windows al utilizar Microsoft SQL Server como origen.
-
Nombre de usuario: el nombre de usuario para conectarse a su servidor de base de datos de origen.
-
Contraseña: la contraseña para conectarse al servidor de base de datos de origen.
-
Usar SSL: si utiliza una capa de sockets seguros (SSL) para conectarse a la base de datos de origen, introduzca true.
-
Almacén de confianza: el almacén de confianza que se utilizará para la conexión SSL.
-
Almacén de confianza: el almacén de claves que se utilizará para la conexión SSL.
-
Autenticación SSL: si utiliza la autenticación SSL mediante certificado, introduzca true.
-
Motores de destino: las plataformas de bases de datos de destino. Utilice los siguientes valores para especificar uno o más destinos en el informe de evaluación:
AURORA_MYSQL para una base de datos compatible con Aurora MySQL.
AURORA_POSTGRESQL para una base de datos compatible con Aurora PostgreSQL.
BABELFISH: para una base de datos de Babelfish para Aurora PostgreSQL.
MARIA_DB para una base de datos de MariaDB.
MSSQL para una base de datos de Microsoft SQL Server.
MYSQL para una base de datos de MySQL.
ORACLE para una base de datos de Oracle.
POSTGRESQL para una base de datos de PostgreSQL.
REDSHIFT para una base de datos de Amazon Redshift.
Separe varios destinos con punto y coma como en este ejemplo:
MYSQL;MARIA_DB. La cantidad de destinos afecta al tiempo que se tarda en ejecutar la evaluación.
Localización y visualización de informes
La evaluación multiservidor genera dos tipos de informes:
-
Un informe agregado de todas las bases de datos de origen.
-
Un informe de evaluación detallado de las bases de datos de destino para cada nombre de esquema de una base de datos de origen.
Los informes se almacenan en el directorio que haya elegido como Ubicación en el cuadro de diálogo Evaluación multiservidor nueva.
Para acceder a los informes detallados, puede navegar por los subdirectorios, que están organizados por base de datos de origen, nombre de esquema y motor de base de datos de destino.
Los informes agregados muestran información en cuatro columnas sobre la complejidad de conversión de una base de datos de destino. Las columnas incluyen información sobre la conversión de objetos de código, objetos de almacenamiento, elementos de sintaxis y complejidad de conversión.
El siguiente ejemplo muestra información para la conversión de dos esquemas de bases de datos de Oracle a Amazon RDS para PostgreSQL.

Las mismas cuatro columnas se adjuntan a los informes para cada motor de base de datos de destino adicional especificado.
Para obtener información detallada acerca de la forma de leer esta información, consulte a continuación.
Resultado de un informe de evaluación agregado
El informe agregado de evaluación de la migración de bases de datos multiservidor AWS Schema Conversion Tool es un archivo CSV con las siguientes columnas:
-
Server IP address and port -
Secret Manager key -
Name -
Description -
Database name -
Schema name -
Code object conversion % fortarget_database -
Storage object conversion % fortarget_database -
Syntax elements conversion % fortarget_database -
Conversion complexity fortarget_database
Para recopilar información, elabora informes AWS SCT de evaluación completos y, a continuación, agrega los informes por esquemas.
En el informe, los tres campos siguientes muestran el porcentaje de conversión automática posible en función de la evaluación:
- % de conversión de objetos de código
-
El porcentaje de objetos de código del esquema que AWS SCT se pueden convertir automáticamente o con cambios mínimos. Los objetos de código incluyen procedimientos, funciones, vistas y similares.
- % de conversión de objetos de almacenamiento
-
El porcentaje de objetos de almacenamiento que SCT puede convertir automáticamente o con cambios mínimos. Los objetos de almacenamiento incluyen tablas, índices, restricciones y similares.
- % de conversión de elementos de sintaxis
-
El porcentaje de elementos de sintaxis que SCT puede convertir automáticamente. Los elementos de sintaxis incluyen cláusulas
SELECT,FROM,DELETEyJOINy similares.
El cálculo de la complejidad de la conversión se basa en la noción de elementos de acción. Un elemento de acción refleja un tipo de problema encontrado en el código fuente que hay que solucionar manualmente durante la migración a un destino concreto. Un elemento de acción puede tener varias apariciones.
Una escala ponderada identifica el nivel de complejidad necesario para realizar una migración. El número 1 representa el nivel más bajo de complejidad y el número 10 representa el nivel más alto de complejidad.
