Uso de índices secundarios globales en DynamoDB
Algunas aplicaciones pueden necesitar llevar a cabo muy diversos tipos de consultas en las que se usen distintos atributos como criterios de consulta. Para responder a estos requisitos, puede crear uno o más índices secundarios globales y emitir solicitudes Query en ellos en Amazon DynamoDB.
Temas
Sincronización de datos entre tablas e índices secundarios globales
Consideraciones sobre el rendimiento aprovisionado para los índices secundarios globales
Consideraciones sobre el almacenamiento para los índices secundarios globales
Detección y corrección de infracciones de la clave del índice en DynamoDB
Uso de índices secundarios globales en DynamoDB con la AWS CLI
Situación: Uso de un índice secundario global
Por poner un ejemplo, tomemos una tabla denominada GameScores que realiza el seguimiento de los usuarios y las puntuaciones de una aplicación de juegos para móviles. Cada elemento en GameScores se identifica por una clave de partición (UserId) y una clave de ordenación (GameTitle). En el siguiente diagrama se muestra cómo se organizarían los elementos de la tabla. No se muestran todos los atributos.
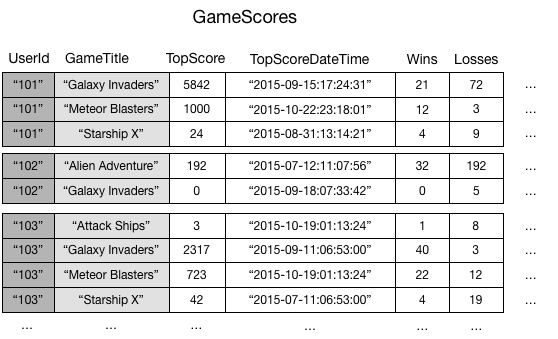
Ahora, supongamos que desea escribir una aplicación de clasificación para mostrar las puntuaciones máximas de cada juego. Una consulta que especifique los atributos de clave (UserId y GameTitle) sería muy eficiente. Sin embargo, si la aplicación tuviese que recuperar datos de GameScores solo según GameTitle, tendría que usar una operación Scan. A medida que se agregan elementos a la tabla, los exámenes de todos los datos resultarían lentos e ineficientes. En consecuencia, resultaría difícil responder a preguntas como estas:
-
¿Cuál es la puntuación máxima que se ha registrado en el juego Meteor Blasters?
-
¿Qué usuario ha obtenido la mejor puntuación en Galaxy Invaders?
-
¿Cuál es la mayor proporción de partidas ganadas respecto a las perdidas?
Para agilizar las consultas de atributos sin clave, puede crear un índice secundario global. Un índice secundario global contiene una selección de atributos de la tabla base, pero están organizados por una clave principal distinta de la clave principal de la tabla. La clave de índice no requiere disponer de ninguno de los atributos de clave de la tabla. Ni siquiera necesita el mismo esquema de claves que una tabla.
Por ejemplo, puede crear un índice secundario global llamado GameTitleIndex, con una clave de partición de GameTitle y una clave de ordenación de TopScore. Puesto que los atributos de clave principal de la tabla base siempre se proyectan en un índice, el atributo UserId también está presente. En el siguiente diagrama se muestra el aspecto que tendría el índice GameTitleIndex.
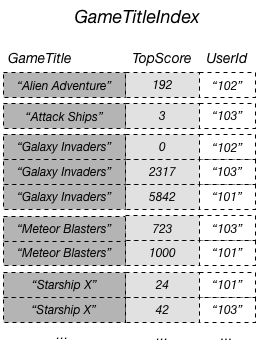
Ahora, puede consultar GameTitleIndex y obtener fácilmente las puntuaciones de Meteor Blasters. Los resultados se ordenan según los valores de la clave de ordenación, TopScore. Si establece el parámetro ScanIndexForward en false, los resultados se devuelven en orden descendente, de modo que la puntuación máxima se devuelve en primer lugar.
Cada índice secundario global debe tener una clave de partición y puede tener una clave de ordenación opcional. El esquema de claves de índice puede ser distinto del de la tabla base. La tabla podría tener una clave principal simple (clave de partición) y, en cambio, se podría crear un índice secundario global con una clave principal compuesta (clave de partición y clave de ordenación), o viceversa. Los atributos de clave del índice pueden constar de cualquier atributo de nivel superior de tipo String, Number o Binary de la tabla base. No se admite ningún otro tipo de escalar, documento ni conjunto.
Puede proyectar otros atributos de la tabla base en el índice si lo desea. Cuando se consulta el índice, DynamoDB puede recuperar estos atributos proyectados de forma eficiente. Sin embargo, las consultas de índice secundario global no permiten recuperar atributos de la tabla base. Por ejemplo, si consulta GameTitleIndex como se muestra en el diagrama anterior, la consulta no podría obtener acceso a ningún atributo sin clave excepto a TopScore (aunque los atributos de clave GameTitle y UserId se proyectarían automáticamente).
En una tabla de DynamoDB, cada valor de clave debe ser único. Sin embargo, no es obligatorio que los valores de clave de un índice secundario global sean únicos. A modo de ejemplo, supongamos que un juego denominado Comet Quest es especialmente difícil, de tal forma que muchos usuarios nuevos intentan lograr una puntuación superior a cero, sin conseguirlo. A continuación se muestran algunos datos que podrían representar esta situación.
| UserId | GameTitle | TopScore |
|---|---|---|
| 123 | Comet Quest | 0 |
| 201 | Comet Quest | 0 |
| 301 | Comet Quest | 0 |
Cuando estos datos se agregan a la tabla GameScores, DynamoDB los propaga a GameTitleIndex. Si, a continuación, consultamos el índice con el valor Comet Quest en GameTitle y el valor 0 en TopScore, se devuelven los valores siguientes.

Solo aparecerán en la respuesta los elementos que tengan los valores de clave especificados. Dentro de ese conjunto de datos, los elementos no aparecen en ningún orden concreto.
Un índice secundario global solo realiza el seguimiento de los elementos de datos cuyos atributos de clave existen realmente. Por ejemplo, supongamos que ha agregado otro elemento nuevo a la tabla GameScores, pero que solo ha proporcionado los atributos de clave principal obligatorios.
| UserId | GameTitle |
|---|---|
| 400 | Comet Quest |
Al no haber especificado el atributo TopScore, DynamoDB no propagará este elemento a GameTitleIndex. Por lo tanto, si consultase GameScores para obtener todos los elementos de Comet Quest, obtendría los siguientes cuatro elementos.
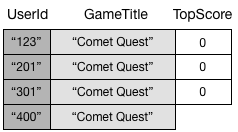
Una consulta parecida de GameTitleIndex devolvería tres elementos, en lugar de cuatro. Esto se debe a que el elemento cuyo valor de TopScore no existe no se propaga al índice.
Proyecciones de atributos
Una proyección es el conjunto de atributos que se copia de una tabla en un índice secundario. La clave de partición y la clave de ordenación de la tabla siempre se proyectan en el índice; puede proyectar otros atributos para admitir los requisitos de consulta de la aplicación. Cuando consulta un índice, Amazon DynamoDB puede acceder a cualquier atributo de la proyección como si esos atributos estuvieran en una tabla propia.
Al crear un índice secundario, debe especificar los atributos que se proyectarán en el índice. DynamoDB ofrece tres opciones diferentes para esto:
-
KEYS_ONLY: cada elemento del índice consta únicamente de los valores de la clave de partición y la clave de ordenación de la tabla, así como de los valores de las claves del índice. La opción
KEYS_ONLYda como resultado el índice secundario más pequeño posible. -
INCLUDE: además de los atributos que se describen en
KEYS_ONLY, el índice secundario incluirá otros atributos sin clave que se especifiquen. -
ALL: el índice secundario incluye todos los atributos de la tabla de origen. Debido a que todos los datos de la tabla están duplicados en el índice, un resultado de proyección
ALLen el índice secundario más grande posible.
En el diagrama anterior, GameTitleIndex tiene solo un atributo proyectado: UserId. Por tanto, mientras una aplicación puede determinar de forma eficiente el UserId de los jugadores que tienen mayor puntuación en cada juego utilizando GameTitle y TopScore en las consultas, no puede determinar de manera eficiente la mayor proporción de partidas ganadas respecto a las perdidas para los jugadores con mayor puntuación. Para ello, tendría que realizar una consulta adicional en la tabla base para recuperar las partidas ganadas y perdidas de cada uno de los jugadores con mayor puntuación. Una manera más eficiente de consultar estos datos sería proyectar estos atributos de la tabla base en el índice secundario global, tal y como se muestra en este diagrama.

Dado que los atributos sin clave Wins y Losses se proyectan en el índice, una aplicación puede determinar la proporción de partidas ganadas respecto a las perdidas en cualquier juego, o para cualquier combinación de juego e identificador de usuario.
Cuando elija los atributos para proyectarlos en un índice secundario global, debe estudiar el equilibrio entre los costes de rendimiento aprovisionado y de almacenamiento:
-
Si solo necesita obtener acceso a algunos atributos con la menor latencia posible, puede ser conveniente proyectar solamente esos atributos en un índice secundario global. Cuando menor es el índice, menos cuesta almacenarlo y menos son los costes de escritura.
-
Si la aplicación va a obtener acceso con frecuencia a determinados atributos sin clave, puede ser interesante proyectarlos en un índice secundario global. Los costes del almacenamiento adicionales del índice secundario global compensarán el coste que supondrían los frecuentes exámenes de la tabla.
-
Si tiene que obtener acceso a la mayoría de los atributos sin clave con frecuencia, puede proyectar estos atributos o, incluso, toda la tabla base, en un índice secundario global. Esto le da la máxima flexibilidad. Sin embargo, el coste del almacenamiento aumentaría y podría llegar a duplicarse.
-
Si la aplicación tiene que consultar una tabla con poca frecuencia, pero tiene que realizar gran cantidad de escrituras o actualizaciones en los datos de la tabla, puede ser conveniente proyectar
KEYS_ONLY. El índice secundario global tendrá el tamaño mínimo, pero estaría disponible siempre que se requiriese para actividades de consulta.
Lectura de datos de un índice secundario global
Puede recuperar elementos de un índice secundario global mediante las operaciones Query y Scan. Las opreciones GetItem y BatchGetItem no se pueden usar en un índice secundario global.
Consulta a un índice secundario global
Puede utilizar la operación Query para obtener acceso a uno o varios elementos de un índice secundario global. En la consulta se debe especificar el nombre de la tabla base y el nombre del índice que se desea utilizar, los atributos que se devolverán en los resultados de la consulta y las condiciones de consulta que se van a aplicar. DynamoDB puede devolver los resultados en orden ascendente o descendente.
Tomemos los datos siguientes devueltos por una operación Query que solicita datos de juegos para una aplicación de clasificación de juegos.
{ "TableName": "GameScores", "IndexName": "GameTitleIndex", "KeyConditionExpression": "GameTitle = :v_title", "ExpressionAttributeValues": { ":v_title": {"S": "Meteor Blasters"} }, "ProjectionExpression": "UserId, TopScore", "ScanIndexForward": false }
En esta consulta:
-
DynamoDB accede GameTitleIndex utilizando la clave de partición GameTitle para localizar los elementos de índice correspondientes a Meteor Blasters. Todos los elementos de índice que tienen esta clave se almacenan en posiciones adyacentes, para agilizar su recuperación.
-
En este juego, DynamoDB utiliza el índice para obtener acceso a todos los identificadores de los usuarios y a las puntuaciones máximas de este juego.
-
Los resultados se devuelven ordenados por orden descendente, porque el parámetro
ScanIndexForwardse ha establecido en false.
Análisis de un índice secundario global
Puede usar la operación Scan para recuperar todos los datos de un índice secundario global. Debe proporcionar el nombre de la tabla base y el nombre del índice en la solicitud. Con una operación Scan, DynamoDB lee todos los datos del índice y los devuelve a la aplicación. También puede solicitar que solo se devuelvan algunos de los datos y se descarten los demás. Para ello, se utiliza el parámetro FilterExpression de la operación Scan. Para obtener más información, consulte Expresiones de filtro para el análisis.
Sincronización de datos entre tablas e índices secundarios globales
DynamoDB sincroniza automáticamente cada índice secundario global con su tabla base. Cuando una aplicación escribe o elimina elementos en una tabla, cualquier índice secundario global de esa tabla se actualizan de forma asincrónica, aplicando un modelo de consistencia final. Las aplicaciones nunca escriben directamente en un índice. Sin embargo, es importante que comprenda las implicaciones de cómo DynamoDB mantiene estos índices.
Los índices secundarios globales heredan el modo de capacidad de lectura/escritura de la tabla base. Para obtener más información, consulte Aspectos a tener en cuenta al cambiar los modos de capacidad en DynamoDB.
Al crear un índice secundario global, debe especificar uno o varios atributos de clave de índice y sus tipos de datos. Esto significa que, cada vez que se escribe un elemento en la tabla base, los tipos de datos de esos atributos deben coincidir con los tipos de datos del esquema de claves de índice. En el caso de GameTitleIndex, el tipo de datos de la clave de partición GameTitle del índice es String. La clave de ordenación TopScore del índice es de tipo Number. Si intenta agregar un elemento a la tabla GameScores, pero especifica un tipo de datos distinto para GameTitle o TopScore, DynamoDB devolverá una excepción ValidationException, porque los tipos de datos no coinciden.
Al colocar o eliminar elementos en una tabla, sus índices secundarios globales se actualizan de forma consistente final. En condiciones normales, los cambios en los datos de la tabla se propagan a los índices secundarios globales casi al instante. No obstante, en algunos escenarios de error improbables, pueden producirse retardos de propagación más prolongados. Debido a ello, las aplicaciones deben prever y controlar las situaciones en las que una consulta de un índice secundario global devuelva resultados que no se encuentren actualizados.
Si escribe un elemento en una tabla, no tiene que especificar los atributos de ninguna clave de ordenación del índice secundario global. Si utilizamos GameTitleIndex a modo de ejemplo, no sería preciso especificar un valor para el atributo TopScore para poder escribir un nuevo elemento en la tabla GameScores. En este caso, DynamoDB no escribe ningún dato en el índice para este elemento concreto.
Una tabla con muchos índices secundarios globales devengará costes más elevados por la actividad de escritura que las tablas con menos índices. Para obtener más información, consulte Consideraciones sobre el rendimiento aprovisionado para los índices secundarios globales.
Clases de tabla con un índice secundario global
Un índice secundario global siempre utilizará la misma clase de tabla que su tabla base. Cada vez que se agrega un nuevo índice secundario global para una tabla, el nuevo índice utilizará la misma clase de tabla que su tabla base. Cuando se actualiza la clase de tabla de una tabla, también se actualizan todos los índices secundarios globales asociados.
Consideraciones sobre el rendimiento aprovisionado para los índices secundarios globales
Al crear un índice secundario global en una tabla en modo aprovisionado, debe especificar las unidades de capacidad de lectura y escritura para la carga de trabajo prevista de ese índice. Los ajustes de rendimiento aprovisionado de un índice secundario global son independientes de los de su tabla base. Una operación Query en un consume unidades de capacidad de lectura del índice, no de la tabla base. Al colocar, actualizar o eliminar elementos en una tabla, sus índices secundarios globales se actualizan de forma consistente final. Estas actualizaciones de índices consumen unidades de capacidad de escritura del índice, no de la tabla base.
Por ejemplo, si realiza una operación Query en un índice secundario global y supera su capacidad de lectura aprovisionada, la solicitud se someterá a una limitación controlada. Si realiza una intensa actividad de escritura en la tabla, pero un índice secundario global de esa tabla no tiene suficiente capacidad de escritura, entonces la actividad de escritura de la tabla se someterá a una limitación controlada.
importante
Para evitar una posible limitación controlada, la capacidad de escritura provisionada para un índice secundario global debe ser igual o mayor que la capacidad de escritura de la tabla base, ya que las nuevas actualizaciones se escribirán tanto en la tabla base como en el índice secundario global.
Para modificar los ajustes de rendimiento aprovisionado de un índice secundario global, use la operación DescribeTable. Se devuelve información detallada sobre cada índices secundario global de la tabla.
Unidades de capacidad de lectura
Los índices secundarios globales admiten las lecturas consistentes finales, cada una de la cuales consume la mitad de una unidad de capacidad de lectura. Esto quiere decir que una sola consulta en un índice secundario global permite recuperar hasta 2 × 4 = 8 KB por unidad de capacidad de lectura.
Para las consultas en un índce secundario global, DynamoDB calcula la actividad de lectura provisionada de la misma forma que para las consultas en una tabla. La única diferencia es que el cálculo se basa en el tamaño de las entradas del índice, no en el tamaño del elemento en la tabla base. El número de unidades de capacidad de lectura es la suma de todos los tamaños de los atributos proyectados para todos los elementos devueltos. El resultado se redondea al múltiplo de 4 KB inmediatamente superior. Para obtener más información sobre cómo calcula DynamoDB el consumo de rendimiento aprovisionado, consulte Modo de capacidad aprovisionada de DynamoDB.
El tamaño máximo de los resultados que devuelve una operación Query es de 1 MB. Esta cifra incluye los tamaños de todos los nombres y valores de los atributos de todos los elementos devueltos.
Por ejemplo, tomemos un índice secundario global en el que cada elemento contiene 2000 bytes de datos. Ahora, supongamos que se utiliza una operación Query en este índice y que la consulta KeyConditionExpression devuelve ocho elementos. El tamaño total de los elementos coincidentes es de 2000 bytes x 8 elementos = 16 000 bytes. El resultado se redondea al múltiplo de 4 KB inmediatamente superior. Puesto que las consultas en un índice secundario global presentan consistencia final, el coste total es de 0,5 (16 KB / 4 KB), lo que equivale a 2 unidades de capacidad de lectura.
Unidades de capacidad de escritura
Cuando se agrega, actualiza o elimina un elemento de una tabla y esto afecta a un índice secundario global, este índice secundario global consume unidades de capacidad de escritura provisionadas por esta operación. El coste total de desempeño provisionado de una escritura es la suma de las unidades de capacidad de escritura consumidas al escribir en la tabla base y aquellas consumidas al actualizar los índices secundarios globales. Si una escritura en una tabla no requiere que se actualice un índice secundario global, no se consume ninguna capacidad de escritura del índice.
Para que una escritura en una tabla se lleve a cabo correctamente, la capacidad de desempeño provisionada definida para la tabla y todos sus índices secundarios globales debe ser suficiente para admitir esa escritura. De lo contrario, la escritura en la tabla se someterá a una limitación controlada.
El coste de escribir un elemento en un índice secundario global depende de varios factores:
-
Si escribe un nuevo elemento en la tabla que define un atributo indexado o actualiza un elemento existente para definir un atributo indexado no definido previamente, se requiere una operación de escritura para colocar el elemento en el índice.
-
Si al actualizar la tabla se cambia el valor de un atributo de clave indexado (de A a B), se requieren dos escrituras, una para eliminar el elemento anterior del índice y otra para colocar el nuevo elemento en el índice.
-
Si ya hay un elemento en el índice, pero al escribir en la tabla se elimina el atributo indexado, se requiere una escritura para eliminar la proyección del elemento anterior del índice.
-
Si no hay ningún elemento presente en el índice antes o después de actualizar el elemento, no se devenga ningún coste de escritura adicional para el índice.
-
Si al actualizar la tabla solo se cambia el valor de los atributos proyectados en el esquema de claves del índice, pero no se cambia el valor de ningún atributo de clave indexado, se requiere una escritura para actualizar los valores de los atributos proyectados en el índice.
Al calcular las unidades de capacidad de escritura, en todos estos factores se presupone que el tamaño de cada elemento del índice es menor o igual que el tamaño de elemento de 1 KB. Las entradas de índice de mayor tamaño requieren más unidades de capacidad de escritura. Para minimizar los costos de escritura, es conveniente estudiar qué atributos tendrán que devolver las consultas y proyectar solamente esos atributos en el índice.
Consideraciones sobre el almacenamiento para los índices secundarios globales
Cuando una aplicación escribe un elemento en una tabla, DynamoDB copia automáticamente el subconjunto de atributos correcto en todos los índices secundarios globales en los que deban aparecer esos atributos. Se aplica un cargo en su cuenta de AWS por el almacenamiento del elemento en la tabla base y también por el almacenamiento de los atributos en todos los índices secundarios globales de esa tabla.
La cantidad de espacio utilizado por un elemento de índice es la suma de lo siguiente:
-
El tamaño en bytes de la clave principal (clave de partición y clave de ordenación) de la tabla base
-
El tamaño en bytes del atributo de clave de índice
-
El tamaño en bytes de los atributos proyectados (si procede)
-
100 bytes de gastos generales por cada elemento de índice
Para calcular los requisitos de almacenamiento de un índice secundario global, puede calcular el tamaño medio de un elemento del índice y, a continuación, multiplicarlo por el número de elementos de la tabla base que tienen atributos de clave del índice secundario global.
Si una tabla contiene un elemento en el que no se ha definido un atributo determinado, pero ese atributo se ha definido como clave de partición o de ordenación del índice, DynamoDB no escribe ningún dato para ese elemento en el índice.
