Índices secundarios locales
Algunas aplicaciones solo necesitan consultar datos mediante la clave principal de la tabla base. Sin embargo, puede haber situaciones en las que una clave de ordenación alternativa sería útil. Para que la aplicación disponga de diversas claves de ordenación entre las que elegir, puede crear uno o varios índices secundarios en una tabla de Amazon DynamoDB y emitir solicitudes Query o Scan para estos índices.
Temas
Situación: Uso de un índice secundario local
Como ejemplo, veamos la tabla Thread. Esta tabla es útil para una aplicación como, por ejemplo, Foros de debate de AWS
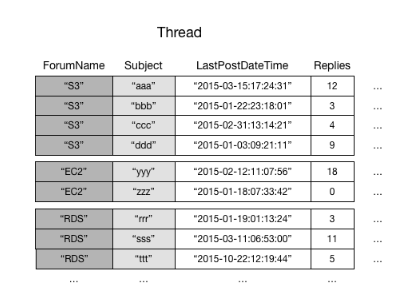
DynamoDB almacena todos los elementos que tienen el mismo valor de clave de partición de forma continua. En este ejemplo, para un valor determinado de ForumName, una operación Query podría localizar inmediatamente todas las conversaciones de ese foro. Dentro de un grupo de elementos con el mismo valor de clave de partición, los elementos se ordenan según el valor de la clave de ordenación. Si la clave de ordenación (Subject) también se incluye en la consulta, DynamoDB puede afinar los resultados que se devuelven; por ejemplo, devolvería todas las conversaciones del foro "S3" cuyo valor de Subject comience por la letra "a".
Algunas solicitudes podrían requerir patrones más complejos de acceso a los datos. Por ejemplo:
-
¿Qué conversaciones del foro son las que suscitan más visualizaciones y respuestas?
-
¿Qué conversación de un foro determinado tiene mayor cantidad de mensajes?
-
¿Cuántas conversaciones se han publicado en un foro determinado dentro de un periodo concreto?
Para responder a estas preguntas, la acción Query no bastaría. En su lugar, habría que aplicar Scan a la tabla completa. Si la tabla contiene millones de elementos, esto consumiría una cantidad enorme de desempeño de lectura provisionado y tardaría mucho tiempo en completarse.
Sin embargo, puede especificar uno o más índices secundarios locales en atributos que no sean clave, tales como Replies or LastPostDateTime.
Un índice secundario local mantiene una clave de ordenación alternativa para un determinado valor de clave de partición. Un índice secundario local también contiene una copia parcial o total de los atributos de la tabla base. Al crear la tabla, se especifican qué atributos se proyectarán en el índice secundario local. Los datos de un índice secundario local se organizan según la misma clave de partición que la tabla base, pero con una clave de ordenación distinta. Esto le permite obtener acceso a los elementos de datos de forma eficiente en esta otra dimensión. Para lograr una mayor flexibilidad de consulta o examen, puede crear hasta cinco índices secundarios locales por tabla.
Supongamos que una aplicación tiene que encontrar todas las conversaciones que se han publicado en los últimos tres meses en un foro particular. Sin un índice secundario local, la aplicación tendría que aplicar la operación Scan a toda la tabla Thread y, después, descartar aquellas publicaciones que no estuviesen comprendidos en el periodo especificado. Con un índice secundario local una operación Query podría usar LastPostDateTime como clave de ordenación para encontrar rápidamente los datos.
En el siguiente diagrama se muestra un índice secundario local denominado LastPostIndex. Tenga en cuenta que la clave de partición es la misma que para la tabla Thread, pero que la clave de ordenación es LastPostDateTime.
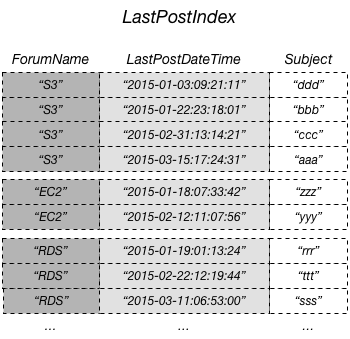
Cada índice secundario local debe cumplir las condiciones siguientes:
-
La clave de partición ha de ser la misma que aquella de la tabla base.
-
La clave de ordenación consta exactamente de un atributo escalar.
-
La clave de ordenación de la tabla base se proyectará en el índice, donde actuará como atributo sin clave.
En este ejemplo, la clave de partición es ForumName y la clave de ordenación del índice secundario local es LastPostDateTime. Además, el valor de clave de ordenación de la tabla base (en este ejemplo, Subject) se proyecta en el índice, aunque no forma parte de la clave de índice. Si una aplicación requiere una lista basada en ForumName y LastPostDateTime, puede emitir una solicitud Query para LastPostIndex. Los resultados de la consulta se ordenan por LastPostDateTime y se pueden devolver en orden ascendente o descendente. La consulta también puede aplicar condiciones de clave, tales como devolver solamente aquellos elementos cuyo valor de LastPostDateTime esté comprendido en un periodo determinado.
Cada índice secundario local contiene automáticamente las claves de partición y ordenación de su tabla base. Si lo desea, puede proyectar atributos sin clave en el índice. Cuando se consulta el índice, DynamoDB puede recuperar estos atributos proyectados de forma eficiente. Cuando se consulta un índice secuandario local, la consulta también puede recuperar atributos no proyectados en el índice. DynamoDB recuperará automáticamente estos atributos de la tabla base, pero con una mayor latencia y costes más elevados de rendimiento aprovisionado.
Para cualquier índice secundario local, puede almacenar hasta 10 GB de datos por cada valor diferente de clave de partición. Esta cifra incluye todos los elementos de la tabla base, además de todos los elementos de los índices, que tengan el mismo valor de clave de partición. Para obtener más información, consulte Colecciones de elementos en los índices secundarios locales.
Proyecciones de atributos
Con LastPostIndex, una aplicación podría usar ForumName y LastPostDateTime como criterios de consulta. Sin embargo, para recuperar cualquier atributo adicional, DynamoDB debe realizar operaciones de lectura adicionales en la tabla Thread. Estas lecturas adicionales se denominan recuperaciones y pueden aumentar la cantidad total de desempeño provisionado necesario para una consulta.
Supongamos que desea rellenar una página web con una lista de todas las conversaciones del foro "S3" y el número de respuestas de cada conversación, ordenadas según la fecha y hora de la última respuesta y comenzando por la respuesta más reciente. Para rellenar esta lista, se requieren los siguientes atributos:
-
Subject -
Replies -
LastPostDateTime
La forma más eficiente de consultar estos datos y evitar operaciones de recuperación, sería proyectar el atributo Repliesde la tabla en el índice secundario global, tal y como se muestra en este diagrama.
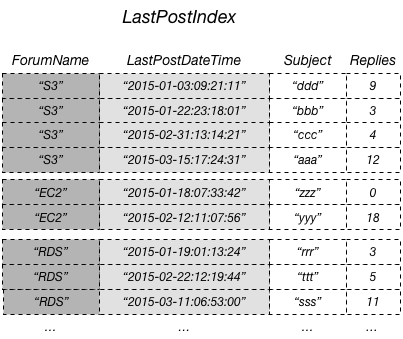
Una proyección es el conjunto de atributos que se copia de una tabla en un índice secundario. La clave de partición y la clave de ordenación de la tabla siempre se proyectan en el índice; puede proyectar otros atributos para admitir los requisitos de consulta de la aplicación. Cuando consulta un índice, Amazon DynamoDB puede acceder a cualquier atributo de la proyección como si esos atributos estuvieran en una tabla propia.
Al crear un índice secundario, debe especificar los atributos que se proyectarán en el índice. DynamoDB ofrece tres opciones diferentes para esto:
-
KEYS_ONLY: cada elemento del índice consta únicamente de los valores de la clave de partición y la clave de ordenación de la tabla, así como de los valores de las claves del índice. La opción
KEYS_ONLYda como resultado el índice secundario más pequeño posible. -
INCLUDE: además de los atributos que se describen en
KEYS_ONLY, el índice secundario incluirá otros atributos sin clave que se especifiquen. -
ALL: el índice secundario incluye todos los atributos de la tabla de origen. Debido a que todos los datos de la tabla están duplicados en el índice, un resultado de proyección
ALLen el índice secundario más grande posible.
En el diagrama anterior, el atributo sin clave Replies se proyecta en LastPostIndex. Una aplicación puede consultar LastPostIndex en lugar de Thread completo para rellenar una página web con Subject, Replies y LastPostDateTime. Si se solicitasen otros atributos sin clave, DynamoDB tendría que recuperarlos en la tabla Thread.
Desde el punto de vista de una aplicación, la recuperación de atributos adicionales de la tabla base se lleva a cabo de forma automática y transparente, por lo que no es necesario volver a escribir la lógica de la aplicación. No obstante, este tipo de recuperaciones puede reducir en gran medida el efecto beneficioso para el desempeño que aporta el uso de un índice secundario local.
Cuando elija los atributos para proyectarlos en un índice secundario local, debe estudiar el equilibrio entre los costes de rendimiento aprovisionado y de almacenamiento:
-
Si solo necesita acceder a algunos atributos con la menor latencia posible, puede ser conveniente proyectar solamente esos atributos en un índice secundario local. Cuando menor es el índice, menos cuesta almacenarlo y menos son los costes de escritura. Si hay atributos que solo tiene que recuperar de vez en cuando, el costo del desempeño provisionado podría superar con creces el costo a largo plazo de almacenar esos atributos.
-
Si la aplicación va a obtener acceso con frecuencia a determinados atributos sin clave, puede ser interesante proyectarlos en un índice secundario local. Los costes del almacenamiento adicionales del índice secundario local compensarán el coste que supondrían los frecuentes exámenes de la tabla.
-
Si tiene que acceder a la mayoría de los atributos sin clave con frecuencia, puede proyectar estos atributos o, incluso, toda la tabla base, en un índice secundario local. De este modo, dispondrá de la máxima flexibilidad y el menor consumo de desempeño provisionado, porque no será preciso realizar recuperaciones. Sin embargo, el coste del almacenamiento aumentaría y podría llegar a duplicarse si se proyectan todos los atributos.
-
Si la aplicación tiene que consultar una tabla con poca frecuencia, pero tiene que realizar gran cantidad de escrituras o actualizaciones en los datos de la tabla, puede ser conveniente proyectar KEYS_ONLY. El índice secundario local tendrá el tamaño mínimo, pero estaría disponible siempre que se requiriese para actividades de consulta.
Creación de un índice secundario local
Para crear una tabla con uno o varios índices secundarios locales, use el parámetro LocalSecondaryIndexes de la operación CreateTable. Los índices secundarios locales de una tabla se crean cuando se crea la tabla. Al eliminar una tabla, todos los índices secundarios globales de esa tabla se eliminan también.
Debe especificar un atributo sin clave que actúe como clave de ordenación del índice secundario local. El atributo que elija debe ser un escalar String, Number o Binary. No se admite ningún otro tipo de escalar, documento ni conjunto. Para obtener una lista completa de los tipos de datos, consulte Tipos de datos.
importante
Para las tablas con índices secundarios locales, existe un límite de tamaño de 10 GB por valor de clave de partición. Una tabla con índices secundarios locales puede almacenar cualquier número de elementos, siempre y cuando el tamaño total de cualquier valor de clave de partición individual no supere los 10 GB. Para obtener más información, consulte Límite del tamaño de una colección de elementos.
Puede proyectar atributos de cualquier tipo de datos en un índice secundario local. Esto incluye escalares, documentos y conjuntos. Para obtener una lista completa de los tipos de datos, consulte Tipos de datos.
Lectura de datos de un índice secundario local
Puede recuperar elementos de un índice secundario local utilizando las operaciones Query y Scan. Las operaciones GetItem y BatchGetItem no se pueden usar en un índice secundario local.
Consulta a un índice secundario local
En una tabla de DynamoDB, la combinación de valor de clave de partición y valor de clave de ordenación de cada elemento debe ser única. Sin embargo, en un índice secundario local, no es preciso que el valor de la clave de ordenación sea exclusivo para un determinado valor de clave de partición. Si un índice secundario local contiene varios elementos que tienen el mismo valor de clave de ordenación, una operación Query devolverá todos los elementos que tengan el mismo valor de clave de partición. En la respuesta, los elementos coincidentes no se devuelven en ningún orden concreto.
Puede consultar un índice secundario local usando lecturas consistentes finales o de consistencia alta. Para especificar qué tipo de consistencia desea aplicar, se utiliza el parámetro ConsistentReadConsistentead de la operación Query. Una lectura de consistencia alta de un índice secundario local siempre devolverá los valores actualizados más recientemente. Si la consulta tiene que recuperar atributos adicionales de la tabla base, estos serán consistentes respecto al índice.
ejemplo
Fíjese en los datos siguientes devueltos por una operación Query que solicita datos de las conversaciones de un foro determinado.
{ "TableName": "Thread", "IndexName": "LastPostIndex", "ConsistentRead": false, "ProjectionExpression": "Subject, LastPostDateTime, Replies, Tags", "KeyConditionExpression": "ForumName = :v_forum and LastPostDateTime between :v_start and :v_end", "ExpressionAttributeValues": { ":v_start": {"S": "2015-08-31T00:00:00.000Z"}, ":v_end": {"S": "2015-11-31T00:00:00.000Z"}, ":v_forum": {"S": "EC2"} } }
En esta consulta:
-
DynamoDB accede a
LastPostIndex. Utiliza la clave de particiónForumNamepara localizar los elementos del índice correspondientes a "EC2". Todos los elementos de índice que tienen esta clave se almacenan en posiciones adyacentes, para agilizar su recuperación. -
En este foro, DynamoDB utiliza el índice para buscar las claves que coinciden con la condición
LastPostDateTimeespecificada. -
Dado que el atributo
Repliesse proyecta en el índice, DynamoDB puede recuperar este atributo sin consumir ningún rendimiento provisionado adicional. -
El atributo
Tagsno se proyecta en el índice, de tal forma que DynamoDB debe acceder a la tablaThready recuperar este atributo. -
Se devuelven los resultados ordenados según
LastPostDateTime. Las entradas de índice se ordenan según el valor de la clave de partición y, a continuación, según el valor de la clave de ordenación;Querylas devuelve en el orden en el que se encuentran almacenadas. Puede utilizar el parámetroScanIndexForwardpara devolver los resultados en orden descendente.
Puesto que el atributo Tags no se ha proyectado en el índice secundario local, DynamoDB debe consumir unidades de capacidad de lectura adicionales para recuperar este atributo de la tabla base. Si necesita ejecutar esta consulta a menudo, debe proyectar Tags en LastPostIndex para evitar la obtención de la tabla base. Sin embargo, si necesitaba acceder a Tags sólo ocasionalmente, el coste de almacenamiento adicional para proyectar Tags en el índice puede no valer la pena.
Análisis de un índice secundario local
Puede utilizar Scan para recuperar todos los datos de un índice secundario local. Debe proporcionar el nombre de la tabla base y el nombre del índice en la solicitud. Con una operación Scan, DynamoDB lee todos los datos del índice y los devuelve a la aplicación. También puede solicitar que solo se devuelvan algunos de los datos y se descarten los demás. Para ello, se utiliza el parámetro FilterExpression del API Scan. Para obtener más información, consulte Expresiones de filtro para el análisis.
Escrituras de elementos e índices secundarios locales
DynamoDB mantiene sincronizados automáticamente todos los índices secundarios locales con sus tablas base respectivas. Las aplicaciones nunca escriben directamente en un índice. Sin embargo, es importante que comprenda las implicaciones de cómo DynamoDB mantiene estos índices.
Al crear un índice secundario local, se especifica un atributo que actuará como clave de ordenación del índice. También se puede especificar el tipo de datos de ese atributo. Esto significa que, cada vez que se escribe un elemento en la tabla base, si el elemento define un atributo de clave de índice, su tipo debe coincidir con el tipo de datos del esquema de claves de índice. En el caso de LastPostIndex, el tipo de datos de la clave de ordenación LastPostDateTime del índice es String. Si intenta agregar un elemento a la tabla Thread, pero especifica un tipo de datos distinto para LastPostDateTime (tal comoNumber), DynamoDB devolverá una excepción ValidationException, porque los tipos de datos no coinciden.
No es obligatorio que exista una relación biunívoca entre los elementos de una tabla base y los elementos en un índice secundario local. De hecho, este comportamiento puede ser ventajoso para muchas aplicaciones.
Una tabla con muchos índices secundarios locales devengará costes más elevados por la actividad de escritura que las tablas con menos índices. Para obtener más información, consulte Consideraciones sobre el rendimiento aprovisionado para los índices secundarios locales.
importante
Para las tablas con índices secundarios locales, existe un límite de tamaño de 10 GB por valor de clave de partición. Una tabla con índices secundarios locales puede almacenar cualquier número de elementos, siempre y cuando el tamaño total de cualquier valor de clave de partición individual no supere los 10 GB. Para obtener más información, consulte Límite del tamaño de una colección de elementos.
Consideraciones sobre el rendimiento aprovisionado para los índices secundarios locales
Al crear una tabla en DynamoDB, se provisionan unidades de capacidad de lectura y escritura para la carga de trabajo prevista de esa tabla. Esta carga de trabajo incluye la actividad de lectura y escritura en los índices secundarios locales de la tabla.
Para ver las tarifas vigentes de la capacidad de rendimiento aprovisionada, visite Precios de Amazon DynamoDB
Unidades de capacidad de lectura
Cuando se realiza una consulta en un índice secundario local, el número de unidades de capacidad de lectura consumidas depende de cómo se obtiene acceso a los datos.
Al igual que ocurre con las consultas de tablas, las consultas de índices pueden utilizar lecturas consistentes finales o de consistencia alta, según el valor de ConsistentRead. Una lectura de consistencia alta consume una unidad de capacidad de lectura; una lectura eventualmente consistente consume solo la mitad. Por lo tanto, elegir la opción de lecturas consistentes finales permite reducir los cargos de unidades de capacidad de lectura.
Para las consultas de índices que solo solicitan claves de índice y atributos proyectados, DynamoDB calcula la actividad de lectura provisionada de la misma forma que para las consultas de tablas. La única diferencia es que el cálculo se basa en el tamaño de las entradas del índice, no en el tamaño del elemento en la tabla base. El número de unidades de capacidad de lectura es la suma de todos los tamaños de los atributos proyectados para todos los elementos devueltos; el resultado se redondea al múltiplo de 4 KB inmediatamente superior. Para obtener más información sobre cómo calcula DynamoDB el consumo de rendimiento aprovisionado, consulte Modo de capacidad aprovisionada de DynamoDB.
Para indexar consultas que leen atributos no proyectados en el índice secundario, DynamoDB tendrá que recuperar esos atributos de la tabla base, además de leer los atributos proyectados en el índice. Estas recuperaciones tienen lugar cuando se incluyen atributos no proyectados en los parámetros Select o ProjectionExpression de la operación Query. Las recuperaciones provocan latencia adicional en las respuestas a las consultas y también devengan un mayor coste de desempeño provisionado. Esto se debe a que, además de las lecturas en el índice secundario local que se han descrito anteriormente, se le cobrarán unidades de capacidad de lectura por cada elemento recuperado de la tabla base. Este cargo incluye la lectura de cada elemento completo de la tabla, no solo de los atributos solicitados.
El tamaño máximo de los resultados que devuelve una operación Query es de 1 MB. Esta cifra incluye los tamaños de todos los nombres y valores de los atributos de todos los elementos devueltos. Sin embargo, si una consulta de un índice secundario local hace que DynamoDB recupere atributos de elementos de la tabla base, el tamaño máximo de los datos de los resultados podría ser inferior. En este caso, el tamaño del resultado es la suma de:
-
El tamaño de los elementos coincidentes del índice, redondeado al múltiplo de 4 KB inmediatamente superior.
-
El tamaño de cada elemento coincidente de la tabla base, redondeado individualmente al múltiplo de 4 KB inmediatamente superior.
Usando esta fórmula, el tamaño máximo de los resultados que devuelve una operación Query también es de 1 MB.
Por ejemplo, tomemos una tabla en la que el tamaño de cada elemento es de 300 bytes. Existe un índice secundario local en esa tabla, pero solo se proyectan en él 200 bytes de cada elemento. Ahora, supongamos que se ejecuta Query en este índice, que la consulta requiere recuperaciones en la tabla para cada elemento y que la consulta devuelve 4 elementos. DynamoDB calcula lo siguiente:
-
El tamaño de los elementos coincidentes en el índice: 200 bytes × 4 elementos = 800 bytes; este valor se redondea hasta 4 KB.
-
El tamaño de cada elemento coincidente de la tabla base: (300 bytes, redondeados al múltiplo de 4 KB inmediatamente superior) × 4 elementos = 16 KB.
Por lo tanto, el tamaño total de los datos del resultado es de 20 KB.
Unidades de capacidad de escritura
Cuando se agrega, actualiza o elimina un elemento de una tabla, la actualización de los índices secundarios locales consumirá unidades de capacidad de escritura provisionadas para la tabla. El coste total de rendimiento aprovisionado de una escritura es la suma de las unidades de capacidad de escritura consumidas al escribir en la tabla y aquellas consumidas al actualizar los índices secundarios locales.
El coste de escribir un elemento en un índice secundario local depende de varios factores:
-
Si escribe un nuevo elemento en la tabla que define un atributo indexado o actualiza un elemento existente para definir un atributo indexado no definido previamente, se requiere una operación de escritura para colocar el elemento en el índice.
-
Si al actualizar la tabla se cambia el valor de un atributo de clave indexado (de A a B), se requieren dos escrituras: una para eliminar el elemento anterior del índice y otra para colocar el nuevo elemento en el índice.
-
Si ya hay un elemento en el índice, pero al escribir en la tabla se elimina el atributo indexado, se requiere una escritura para eliminar la proyección del elemento anterior del índice.
-
Si no hay ningún elemento presente en el índice antes o después de actualizar el elemento, no se devenga ningún coste de escritura adicional para el índice.
Al calcular las unidades de capacidad de escritura, en todos estos factores se presupone que el tamaño de cada elemento del índice es menor o igual que el tamaño de elemento de 1 KB. Las entradas de índice de mayor tamaño requieren más unidades de capacidad de escritura. Para minimizar los costes de escritura, es conveniente estudiar qué atributos tendrán que devolver las consultas y proyectar solamente esos atributos en el índice.
Consideraciones sobre el almacenamiento para los índices secundarios locales
Cuando una aplicación escribe un elemento en una tabla, DynamoDB copia automáticamente el subconjunto de atributos correcto en todos los índices secundarios locales en los que deban aparecer esos atributos. Se aplica un cargo en su cuenta de AWS por el almacenamiento del elemento en la tabla base y también por el almacenamiento de los atributos en todos los índices secundarios locales de esa tabla.
La cantidad de espacio utilizado por un elemento de índice es la suma de lo siguiente:
-
El tamaño en bytes de la clave principal (clave de partición y clave de ordenación) de la tabla base
-
El tamaño en bytes del atributo de clave de índice
-
El tamaño en bytes de los atributos proyectados (si procede)
-
100 bytes de gastos generales por cada elemento de índice
Para calcular los requisitos de almacenamiento de un índice secundario local, puede calcular el tamaño medio de un elemento del índice y, a continuación, multiplicarlo por el número de elementos del índice.
Si una tabla contiene un elemento en el que no se ha definido un atributo determinado, pero ese atributo se ha definido como clave de ordenación del índice, DynamoDB no escribirá ningún dato para ese elemento en el índice.
Colecciones de elementos en los índices secundarios locales
nota
Esta sección solo concierne a las tablas que tienen índices secundarios locales.
En DynamoDB, una colección de elementos es cualquier grupo de elementos que contiene el mismo valor de clave de partición en una tabla y todos sus índices secundarios locales. En los ejemplos utilizados en esta sección, la clave de partición de la tabla Thread es ForumName y la clave de partición de LastPostIndextambién es ForumName. Todos los elementos de la tabla y del índice que tienen el mismo valor de ForumName forman parte de la misma colección de elementos. Por ejemplo, en la tabla Thread y en el índice secundario localLastPostIndex hay una colección de elementos para el foro EC2 y otra colección de elementos distinta para el foro RDS.
En el siguiente diagrama se muestra la colección de elementos del foro S3.
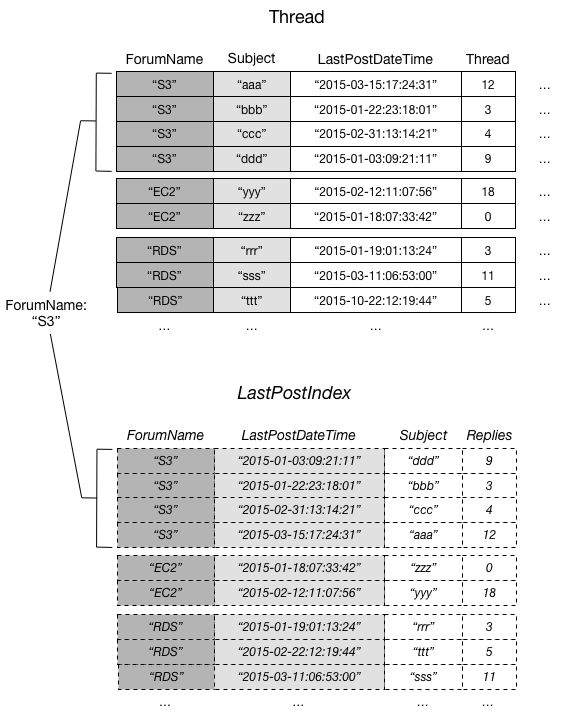
En este diagrama, la colección de elementos consta de todos los elementos de Thread y LastPostIndex donde el valor de clave de partición ForumName es "S3". Si hay otros índices secundarios locales en la tabla, los elementos de esos índices cuyo valor de ForumName sea "S3" también formarán parte de la colección de elementos.
Puede utilizar cualquiera de las siguientes operaciones de DynamoDB para devolver información sobre las colecciones de elementos:
-
BatchWriteItem -
DeleteItem -
PutItem -
UpdateItem -
TransactWriteItems
Todas estas operaciones admiten el parámetro ReturnItemCollectionMetrics. Si establece este parámetro en SIZE, podrá ver información sobre el tamaño de cada colección de elementos en el índice.
ejemplo
A continuación se muestra un ejemplo del resultado de una operación UpdateItem en la tabla Thread, con ReturnItemCollectionMetrics configurado en SIZE. El elemento que se ha actualizado tenía un valor de ForumName de "EC2", por lo que el resultado incluye información acerca de esa colección de elementos.
{ ItemCollectionMetrics: { ItemCollectionKey: { ForumName: "EC2" }, SizeEstimateRangeGB: [0.0, 1.0] } }
El objeto SizeEstimateRangeGB muestra que el tamaño de esta colección de elementos está comprendido entre 0 y 1 GB. DynamoDB actualiza periódicamente este cálculo del tamaño, de modo que las cifras podrían ser distintas la próxima vez que se modifique el elemento.
Límite del tamaño de una colección de elementos
El tamaño máximo de cualquier colección de elementos para una tabla que tenga uno o más índices secundarios locales es de 10 GB. Esto no se aplica a las colecciones de elementos en tablas sin índices secundarios locales, y tampoco se aplica a las colecciones de elementos en índices secundarios generales. Solo se ven afectadas las tablas que tienen uno o más índices secundarios locales.
Si una colección de elementos supera el límite de 10 GB, DynamoDB puede devolver una ItemCollectionSizeLimitExceededException y es posible que no pueda agregar más elementos a la colección de elementos ni incrementar los tamaños de los elementos contenidos en ella. (Las operaciones de lectura y escritura que reduzcan el tamaño de la colección de elementos sí se permitirán). También podrá agregar elementos a otras colecciones de elementos.
Para reducir el tamaño de una colección de elementos, puede elegir una de las siguientes opciones:
-
Eliminar todos los elementos innecesarios que tengan el valor de clave de partición de que se trate. Al eliminar estos elementos de la tabla base, DynamoDB también eliminará las entradas de índice cuyo valor de clave de partición sea el mismo.
-
Actualizar los elementos eliminando atributos o reduciendo el tamaño de estos últimos. Si estos atributos se han proyectado en uno o varios índices secundarios locales, DynamoDB también reducirá el tamaño de las entradas de índice correspondientes.
-
Crear una nueva tabla con las mismas clave de partición y clave de ordenación y, a continuación, mover elementos de la tabla anterior a la nueva. Esto puede ser conveniente si una tabla contiene datos históricos a los que se obtiene acceso con poca frecuencia. Puede considerar también el archivado de estos datos históricos en Amazon Simple Storage Service (Amazon S3).
Cuando el tamaño total de la colección de elementos disminuye por debajo de 10 GB, podrá volver a agregar elementos con el mismo valor de clave de partición.
Como práctica recomendada, es preferible instrumentar la aplicación de tal forma que monitorice los tamaños de las colecciones de elementos. Una forma de hacerlo es establecer el parámetro ReturnItemCollectionMetrics en SIZE siempre que utilice BatchWriteItem, DeleteItem, PutItem o UpdateItem. La aplicación debe examinar el objeto ReturnItemCollectionMetrics en los resultados y registrar un mensaje de error cada vez que una colección de elementos supere un límite definido por el usuario (8 GB, por ejemplo). Establecer un límite menor que 10 GB ofrece un mecanismo de advertencia precoz sistema que le permitirá saber qué colección de elementos está próxima a alcanzar el límite a tiempo para adoptar las medidas pertinentes.
Colecciones de elementos y particiones
En una tabla con uno o más índices secundarios locales, cada colección de elementos se almacena en una partición. El tamaño total de esa colección de elementos está limitado a la capacidad de esa partición: 10 GB. En el caso de una aplicación en la que el modelo de datos incluya colecciones de elementos cuyo tamaño no esté limitado, o en la que pueda esperar razonablemente que algunas colecciones de elementos aumenten más allá de los 10 GB en el futuro, debería considerar la posibilidad de utilizar un índice secundario general.
Debe diseñar las aplicaciones de tal forma que los datos de las tablas se distribuyan uniformemente entre los distintos valores de clave de partición. Para las tablas que tienen índices secundarios locales, las aplicaciones no deben crear "puntos calientes" de actividad de lectura y escritura dentro de una misma colección de elementos de una sola partición.
