Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Prácticas recomendadas para gestionar las relaciones many-to-many
Las listas de adyacencia son un patrón de diseño que resulta útil para modelar many-to-many relaciones en Amazon DynamoDB. En otras palabras, constituyen un mecanismo para representar datos gráficos (nodos y bordes) en DynamoDB.
Patrón de diseño de listas de adyacencia
Cuando distintas entidades de una aplicación tienen una many-to-many relación entre ellas, la relación se puede modelar como una lista de adyacencia. En este patrón, todas las entidades del nivel superior (que se corresponderían con los nodos en el modelo gráfico) se representan utilizando la clave de partición. Cualquier relación con otras entidades (los límites en el modelo gráfico) se representa como un elemento dentro de la partición, donde el valor de la clave de ordenación se establece en el ID de la entidad de destino (nodo de destino).
Algunas de las ventajas de este patrón son la escasa duplicación de los datos y la simplificación de los patrones de consulta para buscar todas las entidades (nodos) relacionadas con una entidad de destino (que tiene un límite con un nodo de destino).
Un ejemplo real en el que este patrón resulta útil son los sistemas de facturación en los que las facturas (invoices) contienen varias cuentas (bills). Una cuenta puede ir en varias facturas. La clave de partición en este ejemplo es InvoiceID o bien BillID. Las particiones BillID tienen todos los atributos específicos de las facturas. Las particiones InvoiceID tienen un elemento que almacena atributos específicos de las facturas y un elemento para cada BillID que aparece en la factura.
El esquema sería similar al siguiente:
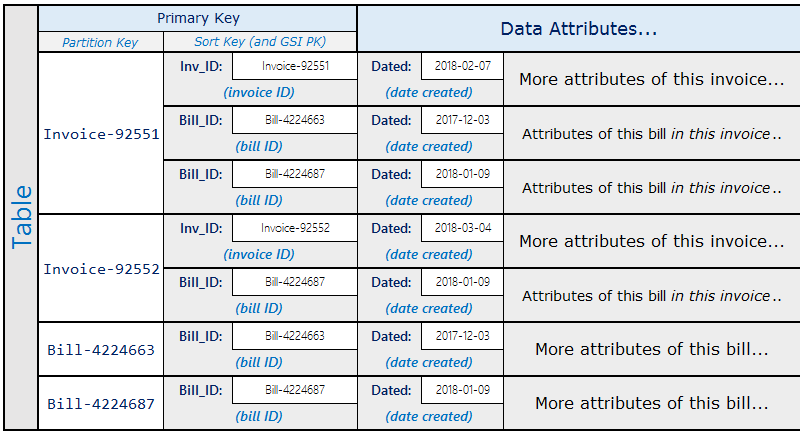
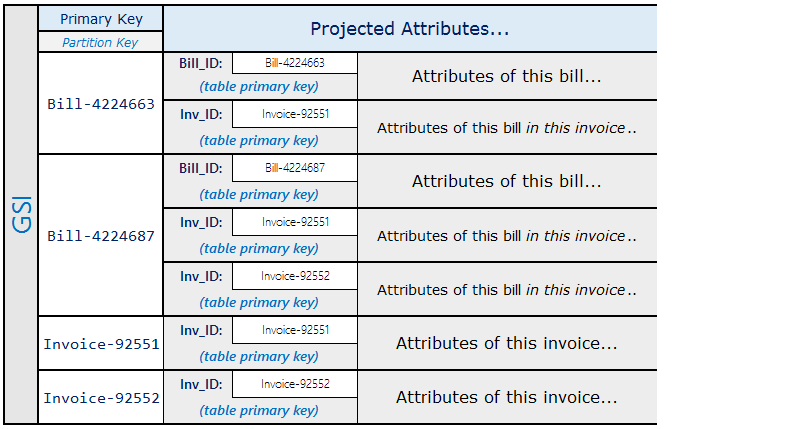
En el esquema anterior, puede ver que las cuentas de una factura pueden consultarse utilizando la clave principal de la tabla. Para buscar todas las facturas que contienen parte de una cuenta, cree un índice secundario global de la clave de ordenación de la tabla.
Las proyecciones del índice secundario global serían similares a las siguientes.
Patrón de gráficos materializados
Muchas aplicaciones se crean en torno a la información que se tiene sobre las clasificaciones entre homólogos, las relaciones comunes entre entidades, el estado de las entidades adyacentes y otros tipos de flujos de trabajo gráficos. En estos tipos de aplicaciones, considere la posibilidad de utilizar el siguiente patrón de diseño de esquemas.
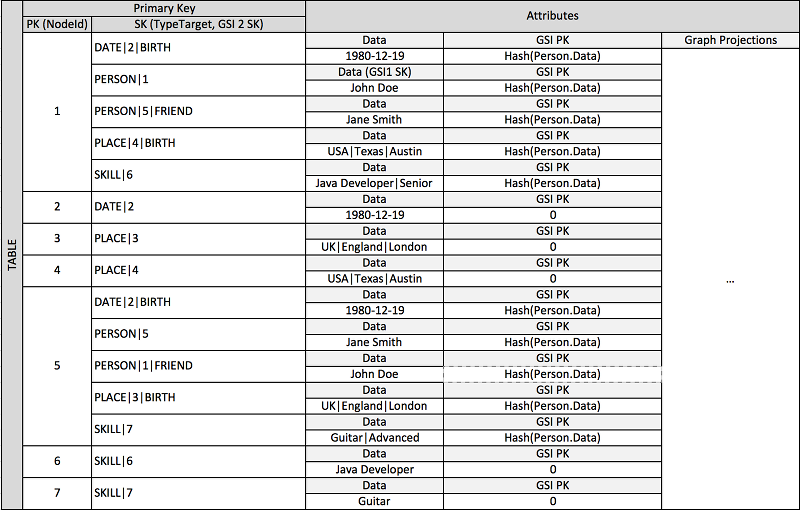
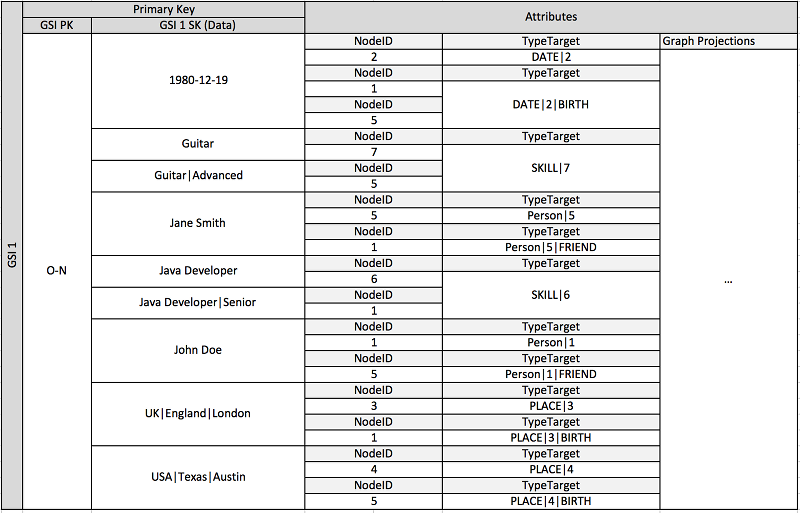
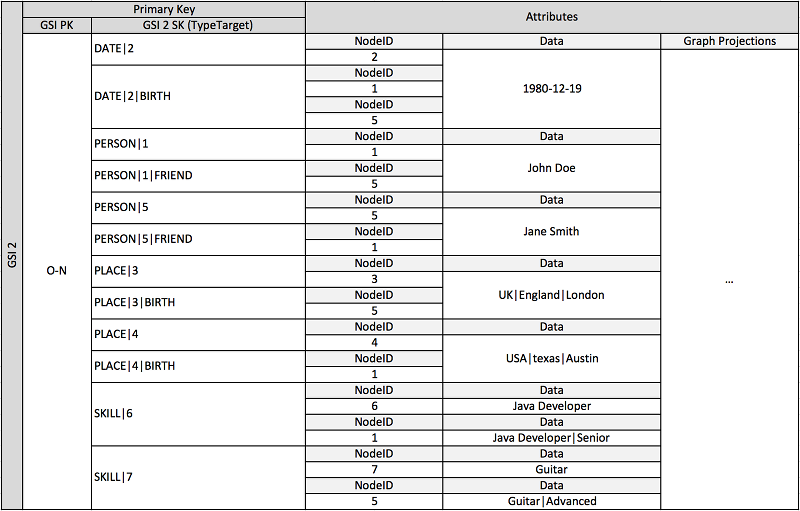
En el esquema anterior, se muestra una estructura de datos gráficos definida por un conjunto de particiones de datos que contienen los elementos que definen los límites y los nodos del gráfico. Los elementos de límite contienen un atributo Target y Type. Estos atributos se utilizan como parte de un nombre clave compuesto «TypeTarget» para identificar el elemento de una partición de la tabla principal o de un segundo índice secundario global.
El primer índice secundario global se basa en el atributo Data. Este atributo utiliza la sobrecarga de índices secundarios globales que se describió anteriormente para indexar varios tipos de atributos diferentes; en este caso, Dates, Names, Places y Skills. Aquí, un índice secundario global es capaz de indexar eficazmente cuatro atributos diferentes.
A medida que inserta elementos en la tabla, puede utilizar una estrategia de fragmentación inteligente para distribuir conjuntos de elementos con grandes agregaciones (Birthdate, Skill) entre tantas particiones lógicas de los índices secundarios globales como sean necesarias y evitar así el problema de que se creen puntos de lectura o escritura "calientes".
El resultado de esta combinación de patrones de diseño es un almacén de datos sólido para flujos de trabajo gráficos en tiempo real de gran eficacia. Estos flujos de trabajo pueden proporcionar consultas de agregación de estado y límite de entidades adyacentes de gran rendimiento para motores de recomendaciones, aplicaciones de redes sociales, clasificaciones de nodos, agregaciones de subárboles y otros casos de uso gráficos habituales.
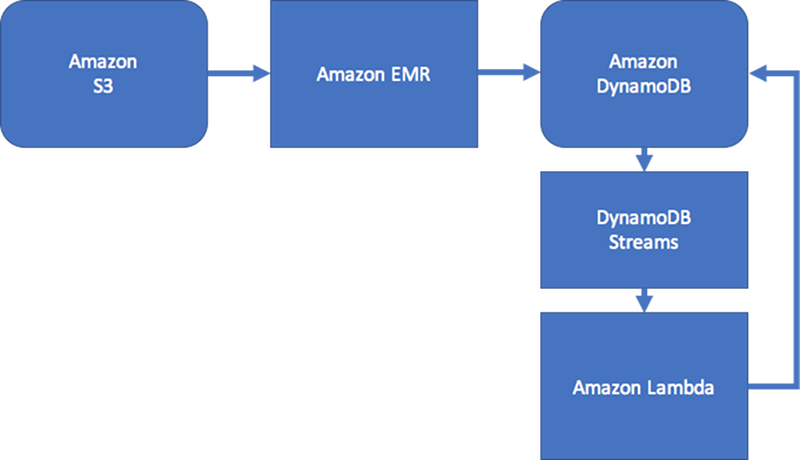
Si en el caso de uso no es importante la coherencia de datos en tiempo real, puede utilizar un proceso de Amazon EMR programado para rellenar los bordes con agregaciones de resumen de gráficos que sean relevantes para los flujos de trabajo. Si la aplicación no necesita saber inmediatamente cuándo se agrega un límite al gráfico, pude utilizar un proceso programado para agregar resultados.
Para mantener cierto nivel de consistencia, el diseño podría incluir Amazon DynamoDB Streams y AWS Lambda a la hora de procesar actualizaciones de borde. También podría usar un trabajo de Amazon EMR para validar los resultados a intervalos periódicos. Ente enfoque se ilustra en el siguiente diagrama. Normalmente, se emplea en aplicaciones de redes sociales, donde el costo de una consulta en tiempo real es elevado y la necesidad de conocer inmediatamente las actualizaciones de cada usuario es baja.
Por lo general, las aplicaciones de seguridad y administración de servicios de TI (ITSM) tienen que responder en tiempo real a los cambios de estado de las entidades que se componen de agregaciones de límites complejas. Este tipo de aplicaciones necesitan un sistema que pueda admitir varias agregaciones en tiempo real de relaciones de segundo y tercer nivel en nodos o recorridos de límites complejos. Si el caso de uso requiere estos tipos de flujos de trabajo de consultas de gráficos en tiempo real, le recomendamos que considere la posibilidad de utilizar Amazon Neptune para administrarlos.
nota
Si necesita consultar conjuntos de datos muy conectados o ejecutar consultas que deban recorrer varios nodos (también conocidas como consultas multisalto) con una latencia de milisegundos, debería considerar la posibilidad de utilizar Amazon Neptune. Amazon Neptune es un motor de base de datos de gráficos de alto rendimiento, optimizado para almacenar miles de millones de relaciones y consultar el gráfico con una latencia de milisegundos.
