Prácticas recomendadas para implementar un sistema de bases de datos híbrido
En determinadas circunstancias, es posible que no resulte provechoso migrar de uno o varios sistemas de administración de base de datos relacional (RDBMS, por sus sigas en inglés) a Amazon DynamoDB. En estos casos, es preferible crear un sistema híbrido.
Si no quiere migrar todo a DynamoDB
Por ejemplo, algunas organizaciones han hecho grandes inversiones en un código que genera multitud de informes necesarios para la contabilidad y las operaciones. Para estas organizaciones, no es importante el tiempo que se tarda en generar los informes. La flexibilidad de un sistema relacional se adapta bien a este tipo de tarea, mientras que volver a crear todos estos informes en un contexto NoSQL podría resultar extraordinariamente difícil.
Además, algunas organizaciones conservan una variedad de sistemas relacionales existentes que han adquirido o heredado a lo largo de décadas. Migrar los datos de estos sistemas podría resultar demasiado arriesgado y caro como para justificar el esfuerzo.
Sin embargo, es posible que estas organizaciones se estén encontrando ahora con el hecho de que sus operaciones dependen de sitios web orientados a los clientes que tienen un tráfico elevado y donde la respuesta en milisegundos resulta esencial. Los sistemas relacionales solo pueden escalarse para satisfacer esta necesidad a un precio exorbitado (y, a menudo, inaceptable).
En estas situaciones, la solución podría consistir en establecer un sistema híbrido en el que DynamoDB cree una vista materializada de los datos almacenados en uno o varios sistemas relacionales y administrar las solicitudes con mucho tráfico en esta vista. Este tipo de sistema podría reducir los costos, ya que se eliminaría el hardware de los servidores, las tareas de mantenimiento y las licencias de RDBMS que se necesitaban anteriormente para administrar el tráfico orientado al cliente.
Cómo puede implementarse un sistema híbrido
DynamoDB puede utilizar DynamoDB Streams y AWS Lambda para integrarse a la perfección con uno o varios sistemas de base de datos relacional existentes:
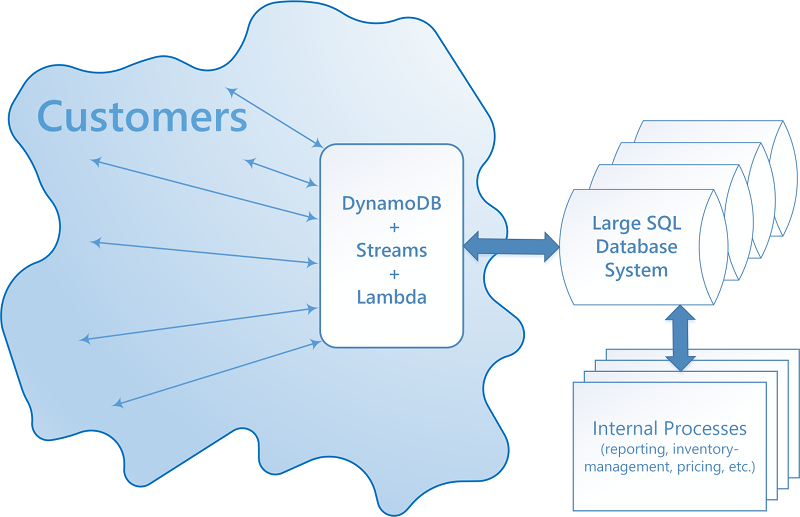
Un sistema que integra DynamoDB Streams y AWS Lambda puede brindar ciertas ventajas:
-
Puede funcionar como una caché persistente de vistas materializadas.
-
Puede configurarse para que se vaya llenando gradualmente con los datos a medida que estos se consultan y modifican en el sistema SQL. Esto significa que no es necesario rellenar previamente toda la vista. Esto, a su vez, significa que es más probable que se utilice de manera eficiente la capacidad de rendimiento aprovisionada.
-
Tiene pocos costos administrativos y ofrece una gran disponibilidad y fiabilidad.
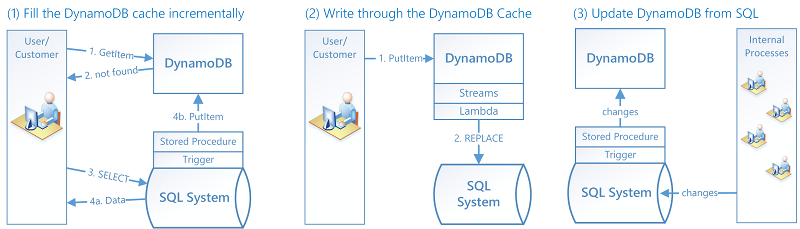
Para que este tipo de integración se implemente, deben darse principalmente tres tipos de interoperaciones:
-
Rellenar la caché de DynamoDB progresivamente. Cuando se necesita un elemento, se busca primero en DynamoDB. Si no está ahí, se busca en el sistema SQL y se carga en DynamoDB.
-
Escribir a través de una caché de DynamoDB. Cuando un cliente cambia un valor en DynamoDB, se desencadena una función Lambda que escribe los datos de nuevo en el sistema SQL.
-
Actualizar DynamoDB desde el sistema SQL. Cuando los procesos internos, como la administración de inventarios o los precios, cambian un valor en el sistema SQL, se desencadena un procedimiento almacenado para propagar el cambio a la vista materializada de DynamoDB.
Estas operaciones son sencillas y no siempre se necesitan todas.
Una solución híbrida también podría resultar útil si quisiera utilizar principalmente DynamoDB, pero también quisiera mantener un pequeño sistema relacional para las consultas puntuales o las operaciones que necesitan una seguridad especial o en las que el tiempo no resulta un factor esencial.
