Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Ejemplo de modelado de datos relacionales en DynamoDB
En este ejemplo, se describe cómo se modelan los datos relacionales en Amazon DynamoDB. El diseño de las tablas de DynamoDB se corresponde con el esquema relacional de registro de pedidos que se describe en Modelos relacionales. Se ajusta al Patrón de diseño de listas de adyacencia, que es un mecanismo habitual para representar estructuras de datos relacionales en DynamoDB.
En este patrón de diseño, tiene que definir un conjunto de tipos de entidades, que normalmente tendrán correlación con las diferentes tablas del esquema relacional. Los elementos de entidad se agregan después a la tabla utilizando una clave principal compuesta (partición y ordenación). La clave de partición de estos elementos de entidad es el atributo que identifica el elemento de manera inequívoca y al que se hace referencia genéricamente en todos los elementos como PK. El atributo de la clave de ordenación contiene un valor que se puede usar como índice invertido o índice secundario global. Se identifica de forma genérica como SK.
Tiene que definir las siguientes entidades, que admiten el esquema relacional de registro de pedidos:
-
HR-Employee - PK: EmployeeID, SK: Employee Name
-
HR-Region - PK: RegionID, SK: Region Name
-
HR-Country - PK:, SK: CountryId Nombre del país
-
HR-Location - PK: LocationID, SK: Country Name
-
HR-Job - PK: JobID, SK: Job Title
-
HR-Department - PK: DepartmentID, SK: DepartmentID
-
Cliente original: PK: CustomeriD, SK: ID AccountRep
-
OE-Order - PK OrderID, SK: CustomerID
-
OE-Product - PK: ProductID, SK: Product Name
-
OE-Warehouse - PK: WarehouseID, SK: Region Name
Después de agregar estos elementos de entidad a la tabla, puede definir sus relaciones agregando elementos de límite a las particiones de los elementos de entidad. En la tabla siguiente, se muestra este paso.
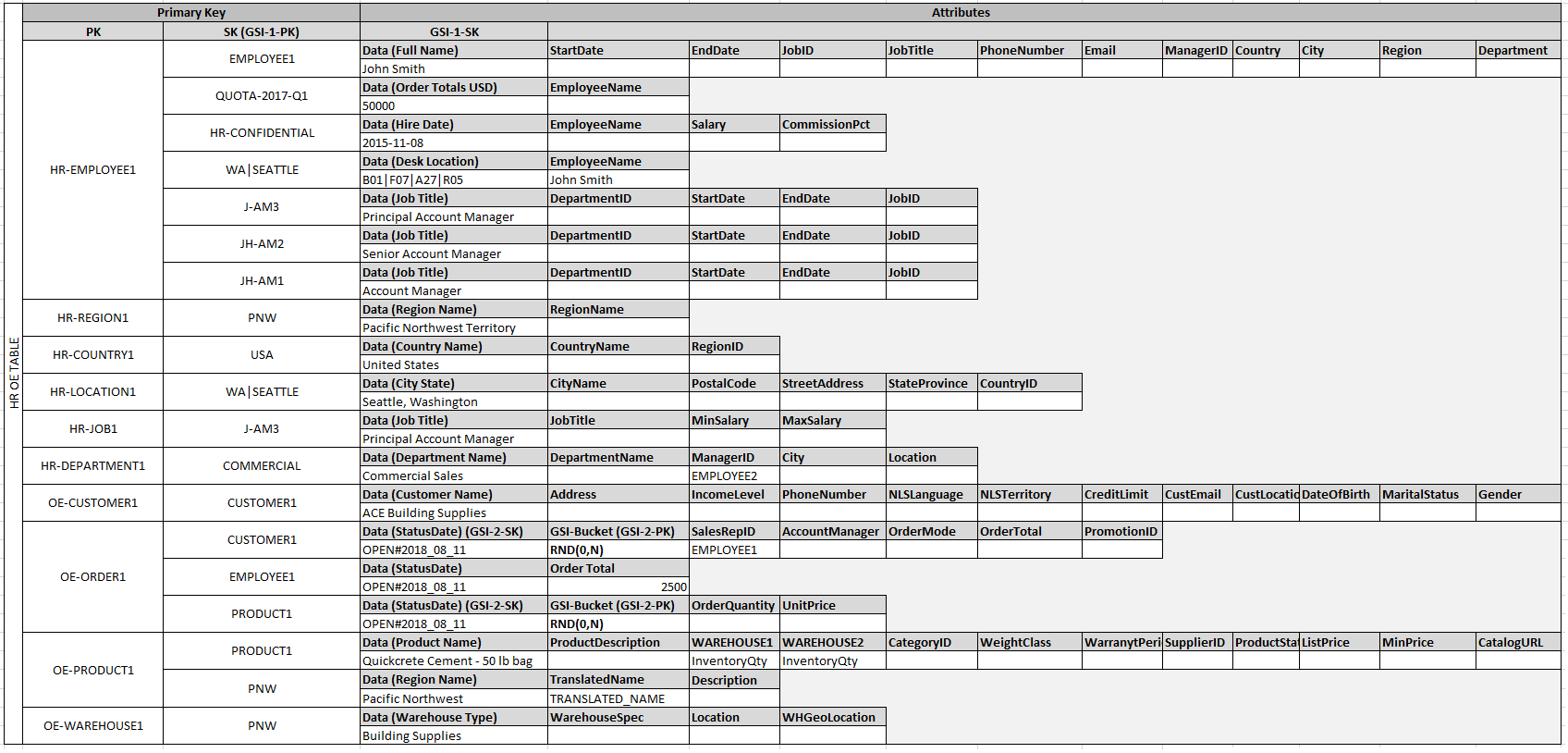
En este ejemplo, las particiones Employee, Order y Product
Entity de la tabla tienen elementos de límite adicionales que contienen marcadores que apuntan a otros elementos de entidad de la tabla. A continuación, debe definir algunos índices secundarios globales (GSI) que admitan todos los patrones de acceso definidos previamente. No todos los elementos de entidad usan el mismo tipo de valor para el atributo de la clave de ordenación o la clave principal. Todo lo que se necesita es que los atributos de la clave de ordenación y la clave principal estén presentes para insertarlos en la tabla.
El hecho de que algunas de estas entidades tengan nombres propios mientras que otras tienen identificadores de identidad como valores de la clave de ordenación permite que el mismo índice secundario global pueda admitir varios tipos de consultas. Esta técnica se denomina sobrecarga de GSI. Elimina de forma eficaz el límite predeterminado de 20 índices secundarios globales de las tablas que contienen varios tipos de elementos. Esto puede verse en el siguiente diagrama como GSI 1.
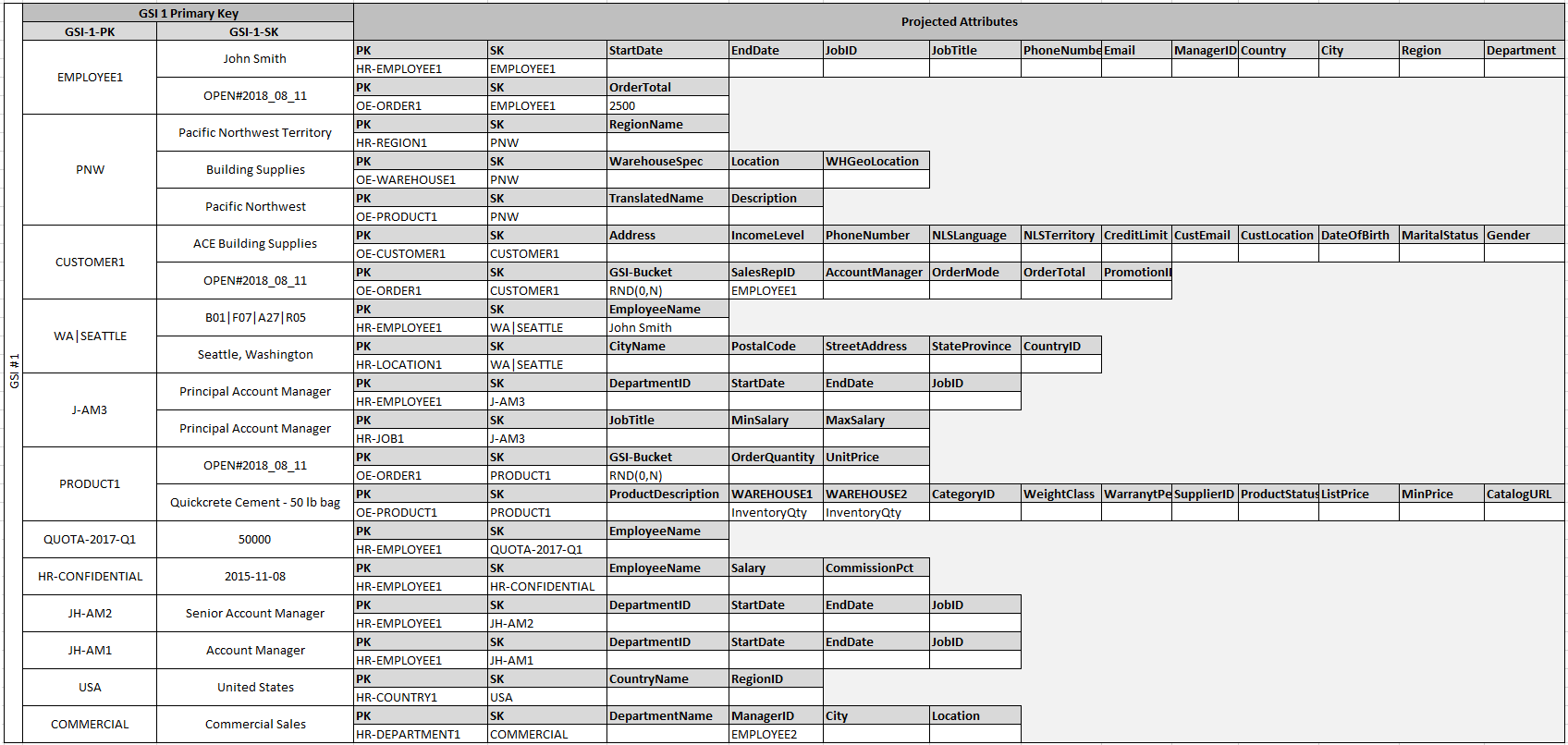
GSI 2 está diseñado para admitir un patrón de acceso de aplicaciones bastante común cuyo objetivo es obtener todos los elementos de la tabla que tienen un determinado estado. En el caso de las tablas grandes que tienen una distribución desigual de los elementos entre los estados disponibles, este patrón de acceso puede constituir un atajo, a menos que los elementos estén distribuidos entre varias particiones lógicas que puedan consultarse en paralelo. Este patrón de diseño se denomina write sharding.
Para realizar esta operación en GSI 2, la aplicación agrega el atributo de clave principal de GSI 2 a cada elemento Order. Lo rellena con un número aleatorio en el rango de 0 a N, donde N puede calcularse genéricamente utilizando la siguiente fórmula, a menos que haya una razón específica para hacer lo contrario.
ItemsPerRCU = 4KB / AvgItemSize PartitionMaxReadRate = 3K * ItemsPerRCU N = MaxRequiredIO / PartitionMaxReadRate
Por ejemplo, supongamos que sus previsiones son las siguientes:
-
Habrá hasta 2 millones de pedidos en el sistema, una cifra que aumentará hasta los 3 millones en 5 años.
-
Hasta un 20 por ciento de estos pedidos tendrán el estado OPEN en un momento dado.
-
El registro de pedido promedio es de unos 100 bytes, con tres OrderItem registros en la partición de pedidos de unos 50 bytes cada uno, lo que da un tamaño medio de la entidad de pedido de 250 bytes.
En esa tabla, el cálculo del factor N sería similar al siguiente.
ItemsPerRCU = 4KB / 250B = 16 PartitionMaxReadRate = 3K * 16 = 48K N = (0.2 * 3M) / 48K = 13
En este caso, tendrá que distribuir todos los pedidos entre al menos 13 particiones lógicas de GSI 2 para garantizar que la lectura de todos los elementos Order con el estado OPEN no genera una partición "caliente" en la capa de almacenamiento físico. Es conveniente dejar margen suficiente en este número para permitir anomalías en el conjunto de datos. Por tanto, es muy probable que un modelo con N = 15 resulte adecuado. Como se mencionó anteriormente, lo hace agregando el valor aleatorio de 0 a N al atributo ISG 2 PK de cada registro Order y OrderItem que se inserta en la tabla.
En este desglose, se presupone que el patrón de acceso que tiene que recopilar todas las facturas OPEN tiene lugar con escasa frecuencia, de modo que puede utilizarse la capacidad de ráfagas para cumplimentar la solicitud. Puede consultar el siguiente índice secundario global utilizando una condición de clave de ordenación State y Date Range para generar un subconjunto o todos los elementos Orders que tienen un determinado estado, según sea necesario.

En este ejemplo, los elementos se distribuyen aleatoriamente entre las 15 particiones lógicas. Esta estructura funciona porque el patrón de acceso requiere que se recuperen un gran número de elementos. Por tanto, es improbable que alguno de los 15 subprocesos devuelva conjuntos de resultados vacíos, lo que podría significar que hay capacidad que se está desaprovechando. Una consulta siempre utiliza una unidad de capacidad de lectura (RCU) o una unidad de capacidad de escritura (WCU), incluso si no se devuelve nada o no se escribe ningún dato.
Si el patrón de acceso necesita hacer una consulta de alta velocidad en este índice secundario global que devuelve un conjunto con escasos resultados, probablemente sea mejor usar un algoritmo hash para distribuir los elementos que un patrón aleatorio. En este caso, puede seleccionar un atributo que se conoce cuando la consulta se ejecuta en tiempo de ejecución y ese atributo se divide en un espacio de clave de 0 a 14 cuando se insertan los elementos. De ese modo, podría leerse de forma eficaz en el índice secundario global.
Por último, puede volver a consultar los patrones de acceso que se definieron anteriormente. A continuación, se muestra la lista con los patrones de acceso y las condiciones de consulta que utilizará con la nueva versión de DynamoDB de la aplicación para acomodarlos.
| Patrones de acceso | Condiciones de la consulta | |
|---|---|---|
|
1 |
Buscar detalles de empleado por ID de empleado |
Clave principal en la tabla, ID="HR-EMPLOYEE" |
|
2 |
Consultar detalles de empleado por nombre de empleado |
Usar GSI-1, PK="Employee Name" |
|
3 |
Obtener solo los detalles actuales del trabajo de un empleado |
Clave principal en la tabla, PK=HR-EMPLOYEE-1, SK empieza por “JH” |
|
4 |
Obtener pedidos de un cliente en un intervalo de fechas |
Utilice GSI-1, PK=CUSTOMER1, SK="STATUS-DATE» para cada StatusCode |
|
5 |
Mostrar todos los pedidos en estado OPEN en un intervalo de fechas en todos los clientes |
Usar GSI-2, PK=consulta en paralelo para el intervalo [0..N], SK entre OPEN-Date1 y OPEN-Date2 |
|
6 |
Todos los empleados contratados recientemente |
Usar GSI-1, PK="HR-CONFIDENTIAL", SK > date1 |
|
7 |
Buscar todos los empleados en un almacén específico |
Usar GSI-1, PK=WAREHOUSE1 |
|
8 |
Obtener todos los artículos del pedido de un producto, incluidos los inventarios de la ubicación del almacén |
Usar GSI-1, PK=PRODUCT1 |
|
9 |
Obtener clientes por representante de cuenta |
Usar GSI-1, PK=ACCOUNT-REP |
|
10 |
Obtener pedidos por representante de cuenta y fecha |
Utilice GSI-1, PK=ACCOUNT-REP, SK="STATUS-DATE» para cada StatusCode |
|
11 |
Obtener todos los empleados con un cargo específico |
Usar GSI-1, PK=JOBTITLE |
|
12 |
Obtener inventario por producto y almacén |
Clave principal en la tabla, PK=OE-PRODUCT1,SK=PRODUCT1 |
|
13 |
Obtener inventario total de productos |
Clave principal en la tabla, PK=OE-PRODUCT1, SK=PRODUCT1 |
|
14 |
Obtener los representantes de cuenta clasificados por el total de pedidos y el periodo de ventas |
Utilice GSI-1, scanIndexForward PK=YYYY-Q1, =False |
