Prácticas recomendadas para modelar datos relacionales en DynamoDB
Esta sección proporciona las prácticas recomendadas para modelar datos relacionales en Amazon DynamoDB. En primer lugar, presentamos los conceptos tradicionales de modelado de datos. A continuación, describimos las ventajas de utilizar DynamoDB frente a los sistemas tradicionales de administración de bases de datos relacionales: cómo elimina la necesidad de realizar operaciones JOIN y reduce la sobrecarga.
A continuación explicamos cómo diseñar una tabla de DynamoDB que se escale de forma eficiente. Por último, ofrecemos un ejemplo de cómo modelar datos relacionales en DynamoDB.
Modelos tradicionales de bases de datos relacionales
Un sistema tradicional de administración de bases de datos relacionales (RDBMS) almacena los datos en una estructura relacional normalizada. El objetivo del modelo de datos relacional es reducir la duplicación de datos (mediante la normalización) para respaldar la integridad referencial y reducir las anomalías en los datos.
El siguiente esquema es un ejemplo de modelo de datos relacional para una aplicación genérica de entrada de pedidos. La aplicación admite un esquema de recursos humanos que respalda los sistemas operativos y de apoyo empresarial de un fabricante teórico.
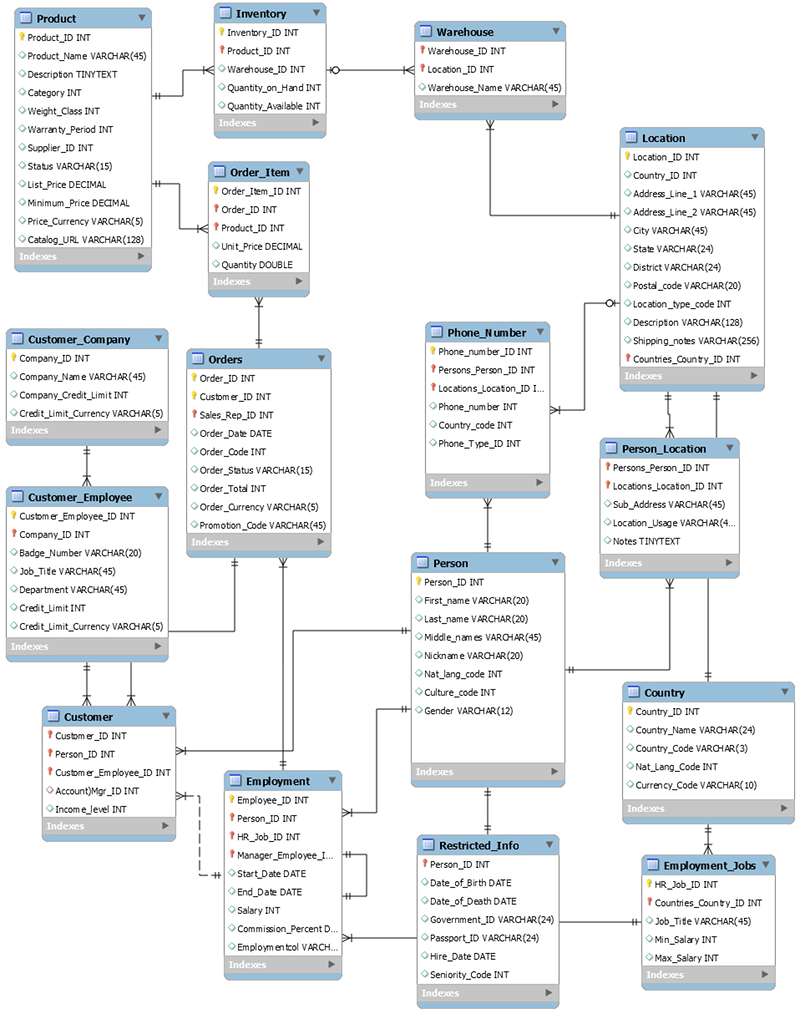
Como servicio de base de datos no relacional, DynamoDB ofrece muchas ventajas sobre los sistemas tradicionales de administración de bases de datos relacionales.
Cómo DynamoDB elimina la necesidad de las operaciones JOIN
Un sistema RDBMS utiliza un lenguaje de consulta estructurado (SQL) para devolver los datos a la aplicación. Debido a la normalización del modelo de datos, estas consultas suelen requerir la utilización del operador JOIN para combinar datos de una o varias tablas.
Por ejemplo, para generar una lista de pedidos de compra ordenados por la cantidad de existencias en todos los almacenes que puede enviar cada elemento, podría emitir la siguiente consulta SQL en el esquema anterior.
SELECT * FROM Orders
INNER JOIN Order_Items ON Orders.Order_ID = Order_Items.Order_ID
INNER JOIN Products ON Products.Product_ID = Order_Items.Product_ID
INNER JOIN Inventories ON Products.Product_ID = Inventories.Product_ID
ORDER BY Quantity_on_Hand DESCLas consultas SQL de este tipo pueden proporcionar una API flexible para obtener acceso a los datos, pero requieren una gran cantidad de procesamiento. Cada unión de la consulta aumenta su complejidad en tiempo de ejecución, porque los datos de cada tabla deben prepararse y, a continuación, reunirse para devolver el conjunto de resultados.
Otros factores que pueden influir en el tiempo que tardan en ejecutarse las consultas son el tamaño de las tablas y si las columnas que se unen tienen índices. La consulta anterior inicia consultas complejas en varias tablas y, a continuación, ordena el conjunto de resultados.
En la esencia del modelado de datos NoSQL se encuentra la eliminación de la necesidad de JOINs. Ese es el motivo por el que creamos DynamoDB para que fuera compatible con Amazon.com y, por eso, DynamoDB puede ofrecer un rendimiento coherente a cualquier escala. Dada la complejidad en tiempo de ejecución de las consultas SQL y JOINs, el rendimiento del RBDMS no es constante a escala. Esto provoca problemas de rendimiento a medida que crecen las aplicaciones de los clientes.
Aunque la normalización de los datos reduce la cantidad de datos almacenados en el disco, a menudo los recursos más limitados que repercuten en el rendimiento son el tiempo de CPU y la latencia de red.
DynamoDB se creó para minimizar ambas restricciones mediante la eliminación de JOINs (y el fomento de la desnormalización de los datos) y la optimización de la arquitectura de base de datos para responder completamente a la consulta de una aplicación con una única solicitud a un elemento. Estas cualidades permiten a DynamoDB ofrecer un rendimiento de un solo dígito en milisegundos a cualquier escala. Esto se debe a que la complejidad del tiempo de ejecución de las operaciones de DynamoDB es constante, independientemente del tamaño de los datos, para los patrones de acceso habituales.
Cómo las transacciones de DynamoDB eliminan la sobrecarga del proceso de escritura
Otro factor que puede ralentizar un sistema RDBMS es el uso de transacciones para escribir en un esquema normalizado. Como se muestra en el ejemplo, las estructuras de datos relacionales que se utilizan en la mayoría de aplicaciones de procesamiento de transacciones online (OLTP) deben dividirse y distribuirse por varias tablas lógicas cuando se almacenan en un sistema RDBMS.
Por tanto, se necesita un marco de transacciones compatible con ACID que evite las condiciones de carrera y los problemas de integridad de datos que podrían darse si una aplicación intentara leer un objeto que se estuviera escribiendo en ese momento. Un marco de transacciones de este tipo, cuando se combina con un esquema relacional, puede agregar una sobrecarga significativa al proceso de escritura.
La implementación de transacciones en DynamoDB prohíbe los problemas comunes de escalado que se encuentran con un RDBMS. DynamoDB lo hace emitiendo una transacción como una única llamada a la API y limitando el número de elementos a los que se puede acceder en esa única transacción. Las transacciones de larga duración pueden causar problemas operativos al mantener bloqueados los datos durante mucho tiempo o de forma perpetua, porque la transacción nunca se cierra.
Para evitar estos problemas en DynamoDB, las transacciones se implementaron con dos operaciones de la API distintas: TransactWriteItems y TransactGetItems. Estas operaciones de la API no tienen la semántica de inicio y fin que es común en un sistema RDBMS. Además, DynamoDB tiene un límite de acceso de 100 elementos en una transacción para evitar de forma similar las transacciones de larga duración. Para obtener más información sobre las transacciones de DynamoDB, consulte Uso de transacciones.
Por estos motivos, cuando su empresa requiere una respuesta de baja latencia ante consultas con mucho tráfico, suele aportar más ventaja el uso de un sistema NoSQL tanto desde un punto de vista técnico como económico. Amazon DynamoDB ayuda a resolver los problemas que limitan la escalabilidad del sistema relacional evitándolos.
El rendimiento de un sistema RDBMS no suele escalar bien por los siguientes motivos:
-
Utiliza uniones caras para generar las vistas necesarias con los resultados de la consulta.
-
Normalizan los datos y los guardan en varias tablas que requieren muchas consultas para escribir en el disco.
-
Normalmente, hay que sumar los costos de desempeño de un sistema de transacciones compatible con ACID.
DynamoDB escala bien por los siguientes motivos:
-
La flexibilidad del esquema permite que DynamoDB pueda almacenar datos jerárquicos complejos en un solo elemento.
-
El diseño de la clave compuesta permite almacenar elementos relacionados próximos entre sí en la misma tabla.
-
Las transacciones se realizan en una sola operación. El límite para el número de elementos a los que se puede acceder es de 100, para evitar operaciones de larga duración.
Las consultas que se realizan en el almacén de datos son mucho más sencillas y suelen tener la forma siguiente:
SELECT * FROM Table_X WHERE Attribute_Y = "somevalue"
DynamoDB trabaja mucho menos para devolver los datos solicitados que el sistema RDBMS del ejemplo anterior.
