Esta página es solo para los clientes actuales del servicio S3 Glacier que utilizan Vaults y la API de REST original de 2012.
Si busca soluciones de almacenamiento de archivos, se recomienda que utilice las clases de almacenamiento de S3 Glacier en Amazon S3, S3 Glacier Instant Retrieval, S3 Glacier Flexible Retrieval y S3 Glacier Deep Archive. Para obtener más información sobre estas opciones de almacenamiento, consulte Clases de almacenamiento de S3 Glacier
Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Cálculo de sumas de comprobación
Al cargar un archivo, debe incluir los encabezados x-amz-sha256-tree-hash y x-amz-content-sha256. El encabezado x-amz-sha256-tree-hash es una suma de comprobación de la carga del cuerpo de la solicitud. En este tema, se describe cómo calcular el encabezado x-amz-sha256-tree-hash. El encabezado x-amz-content-sha256 es un hash de toda la carga y es necesario para poder llevar a cabo la autorización. Para obtener más información, consulte Ejemplo del cálculo de una firma para la API de streaming.
La carga de la solicitud puede ser:
-
Un archivo completo: cuando se carga un archivo en una única solicitud mediante la API Upload Archive, se envía todo el archivo en el cuerpo de la solicitud. En ese caso, debe incluirse la suma de comprobación de todo el archivo.
-
Parte de un archivo: cuando se carga un archivo en partes mediante la API de carga multiparte, solamente se envía una parte del archivo en el cuerpo de la solicitud. En ese caso, debe incluirse la suma de comprobación de la parte del archivo correspondiente. Una vez cargadas todas las partes, es necesario enviar una solicitud de tipo Complete Multipart Upload, que debe contener la suma de comprobación de todo el archivo.
La suma de comprobación de la carga es un algoritmo hash en árbol SHA-256. Se denomina "hash en árbol" porque, en el proceso para calcular la suma de comprobación, lo que se calcula es un árbol de valores hash SHA-256. El valor hash de la raíz es la suma de comprobación de todo el archivo.
nota
En esta sección, se describe un método para calcular el hash en árbol SHA-256. Sin embargo, puede utilizar cualquier procedimiento, siempre y cuando se obtenga el mismo resultado.
El hash en árbol SHA-256 se calcula del modo siguiente:
-
En cada fragmento de 1 MB de los datos de carga, calcule el hash SHA-256. El último fragmento de datos puede ser inferior a 1 MB. Por ejemplo, si carga un archivo de 3,2 MB, calculará los valores hash SHA-256 de cada uno de los tres primeros fragmentos de 1 MB y luego el hash SHA-256 de los 0,2 MB de datos restantes. Estos valores hash conforman los nodos de hoja del árbol.
-
Cree el siguiente nivel del árbol.
-
Concatene los valores hash de dos nodos secundarios consecutivos y calcule el hash SHA-256 de estos valores concatenados. Al concatenar y generar el hash SHA-256, se crea un nodo principal para los dos nodos secundarios.
-
Si solo queda un nodo secundario, promueva ese valor hash al siguiente nivel del árbol.
-
-
Repita el paso 2 hasta que el árbol resultante tenga una raíz. La raíz del árbol representa el hash de todo el archivo, mientras que la raíz del subárbol correspondiente representa el hash de una de las partes de una carga multiparte.
Temas
Ejemplo 1 de hash en árbol: cargar un archivo a través de una única solicitud
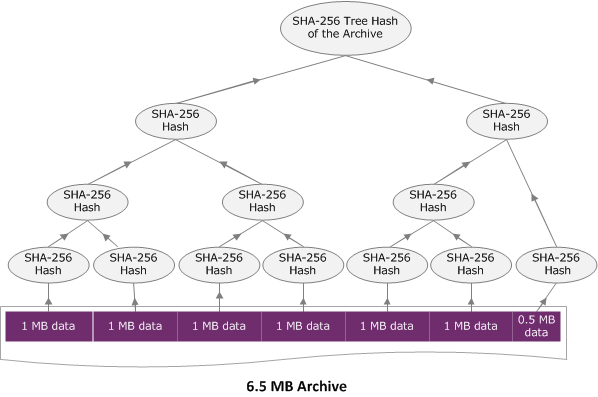
Cuando se carga un archivo a través de una única solicitud utilizando la API Upload Archive (consulte Carga de archivo (POST archivo)), la carga de la solicitud contiene todo el archivo. Por tanto, deberá incluir el algoritmo hash en árbol de todo el archivo en el encabezado x-amz-sha256-tree-hash de la solicitud. Supongamos que desea cargar un archivo de 6,5 MB. En el diagrama siguiente, se ilustra el proceso de creación del hash SHA-256 del archivo. Debe leer el archivo y calcular el hash SHA-256 de cada fragmento de 1 MB. También debe calcular el hash de los 0,5 MB de datos restantes y crear después el árbol, tal y como se describe en el procedimiento anterior.
Ejemplo 2 de hash en árbol: cargar un archivo a través de una carga multiparte
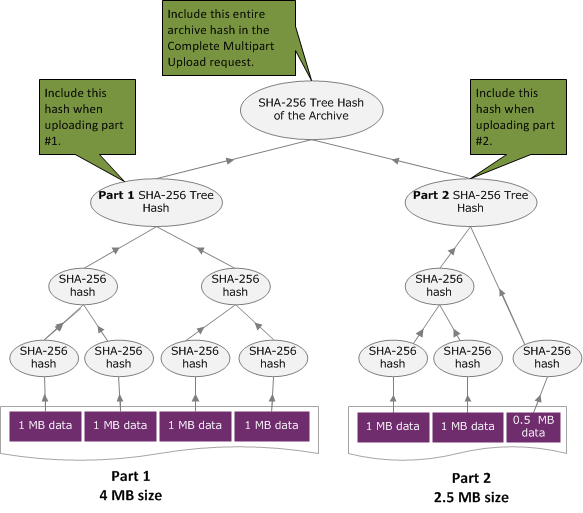
El proceso para calcular el algoritmo hash en árbol cuando el archivo se carga a través de una carga multiparte es el mismo que cuando se carga a través de una única solicitud. La única diferencia es que, en la carga multiparte, solo se carga una parte del archivo en cada solicitud (a través de la API Carga de partes (PUT uploadID)) y, por tanto, solo debe proporcionarse la suma de comprobación de la parte en el encabezado x-amz-sha256-tree-hash de la solicitud. Sin embargo, una vez que se hayan cargado todas las partes, debe enviarse la solicitud Complete Multipart Upload (consulte Finalización de una carga multiparte (POST uploadID)) con un hash en árbol de todo el archivo en el encabezado x-amz-sha256-tree-hash de la solicitud.
Cálculo del hash en árbol de un archivo
Los algoritmos que se muestran aquí se han seleccionado con fines ilustrativos. Puede optimizar el código según sea necesario para adaptarlo a su escenario de implementación. Si usa un SDK de Amazon para programar en Amazon S3 Glacier (S3 Glacier), el cálculo del hash en árbol se realiza automáticamente y solo es necesario proporcionar la referencia del archivo.
ejemplo 1: Ejemplo de Java
El siguiente ejemplo muestra cómo calcular el hash de SHA256 árbol de un archivo mediante Java. Puede ejecutar este ejemplo proporcionando la ubicación de un archivo como argumento o utilizando el método TreeHashExample.computeSHA256TreeHash directamente en el código.
import java.io.File; import java.io.FileInputStream; import java.io.IOException; import java.security.MessageDigest; import java.security.NoSuchAlgorithmException; public class TreeHashExample { static final int ONE_MB = 1024 * 1024; /** * Compute the Hex representation of the SHA-256 tree hash for the specified * File * * @param args * args[0]: a file to compute a SHA-256 tree hash for */ public static void main(String[] args) { if (args.length < 1) { System.err.println("Missing required filename argument"); System.exit(-1); } File inputFile = new File(args[0]); try { byte[] treeHash = computeSHA256TreeHash(inputFile); System.out.printf("SHA-256 Tree Hash = %s\n", toHex(treeHash)); } catch (IOException ioe) { System.err.format("Exception when reading from file %s: %s", inputFile, ioe.getMessage()); System.exit(-1); } catch (NoSuchAlgorithmException nsae) { System.err.format("Cannot locate MessageDigest algorithm for SHA-256: %s", nsae.getMessage()); System.exit(-1); } } /** * Computes the SHA-256 tree hash for the given file * * @param inputFile * a File to compute the SHA-256 tree hash for * @return a byte[] containing the SHA-256 tree hash * @throws IOException * Thrown if there's an issue reading the input file * @throws NoSuchAlgorithmException */ public static byte[] computeSHA256TreeHash(File inputFile) throws IOException, NoSuchAlgorithmException { byte[][] chunkSHA256Hashes = getChunkSHA256Hashes(inputFile); return computeSHA256TreeHash(chunkSHA256Hashes); } /** * Computes a SHA256 checksum for each 1 MB chunk of the input file. This * includes the checksum for the last chunk even if it is smaller than 1 MB. * * @param file * A file to compute checksums on * @return a byte[][] containing the checksums of each 1 MB chunk * @throws IOException * Thrown if there's an IOException when reading the file * @throws NoSuchAlgorithmException * Thrown if SHA-256 MessageDigest can't be found */ public static byte[][] getChunkSHA256Hashes(File file) throws IOException, NoSuchAlgorithmException { MessageDigest md = MessageDigest.getInstance("SHA-256"); long numChunks = file.length() / ONE_MB; if (file.length() % ONE_MB > 0) { numChunks++; } if (numChunks == 0) { return new byte[][] { md.digest() }; } byte[][] chunkSHA256Hashes = new byte[(int) numChunks][]; FileInputStream fileStream = null; try { fileStream = new FileInputStream(file); byte[] buff = new byte[ONE_MB]; int bytesRead; int idx = 0; int offset = 0; while ((bytesRead = fileStream.read(buff, offset, ONE_MB)) > 0) { md.reset(); md.update(buff, 0, bytesRead); chunkSHA256Hashes[idx++] = md.digest(); offset += bytesRead; } return chunkSHA256Hashes; } finally { if (fileStream != null) { try { fileStream.close(); } catch (IOException ioe) { System.err.printf("Exception while closing %s.\n %s", file.getName(), ioe.getMessage()); } } } } /** * Computes the SHA-256 tree hash for the passed array of 1 MB chunk * checksums. * * This method uses a pair of arrays to iteratively compute the tree hash * level by level. Each iteration takes two adjacent elements from the * previous level source array, computes the SHA-256 hash on their * concatenated value and places the result in the next level's destination * array. At the end of an iteration, the destination array becomes the * source array for the next level. * * @param chunkSHA256Hashes * An array of SHA-256 checksums * @return A byte[] containing the SHA-256 tree hash for the input chunks * @throws NoSuchAlgorithmException * Thrown if SHA-256 MessageDigest can't be found */ public static byte[] computeSHA256TreeHash(byte[][] chunkSHA256Hashes) throws NoSuchAlgorithmException { MessageDigest md = MessageDigest.getInstance("SHA-256"); byte[][] prevLvlHashes = chunkSHA256Hashes; while (prevLvlHashes.length > 1) { int len = prevLvlHashes.length / 2; if (prevLvlHashes.length % 2 != 0) { len++; } byte[][] currLvlHashes = new byte[len][]; int j = 0; for (int i = 0; i < prevLvlHashes.length; i = i + 2, j++) { // If there are at least two elements remaining if (prevLvlHashes.length - i > 1) { // Calculate a digest of the concatenated nodes md.reset(); md.update(prevLvlHashes[i]); md.update(prevLvlHashes[i + 1]); currLvlHashes[j] = md.digest(); } else { // Take care of remaining odd chunk currLvlHashes[j] = prevLvlHashes[i]; } } prevLvlHashes = currLvlHashes; } return prevLvlHashes[0]; } /** * Returns the hexadecimal representation of the input byte array * * @param data * a byte[] to convert to Hex characters * @return A String containing Hex characters */ public static String toHex(byte[] data) { StringBuilder sb = new StringBuilder(data.length * 2); for (int i = 0; i < data.length; i++) { String hex = Integer.toHexString(data[i] & 0xFF); if (hex.length() == 1) { // Append leading zero. sb.append("0"); } sb.append(hex); } return sb.toString().toLowerCase(); } }
ejemplo 2: Ejemplo de C# .NET
El siguiente ejemplo muestra cómo calcular el hash de SHA256 árbol de un archivo. Puede ejecutar este ejemplo suministrando la ubicación de un archivo como argumento.
using System; using System.IO; using System.Security.Cryptography; namespace ExampleTreeHash { class Program { static int ONE_MB = 1024 * 1024; /** * Compute the Hex representation of the SHA-256 tree hash for the * specified file * * @param args * args[0]: a file to compute a SHA-256 tree hash for */ public static void Main(string[] args) { if (args.Length < 1) { Console.WriteLine("Missing required filename argument"); Environment.Exit(-1); } FileStream inputFile = File.Open(args[0], FileMode.Open, FileAccess.Read); try { byte[] treeHash = ComputeSHA256TreeHash(inputFile); Console.WriteLine("SHA-256 Tree Hash = {0}", BitConverter.ToString(treeHash).Replace("-", "").ToLower()); Console.ReadLine(); Environment.Exit(-1); } catch (IOException ioe) { Console.WriteLine("Exception when reading from file {0}: {1}", inputFile, ioe.Message); Console.ReadLine(); Environment.Exit(-1); } catch (Exception e) { Console.WriteLine("Cannot locate MessageDigest algorithm for SHA-256: {0}", e.Message); Console.WriteLine(e.GetType()); Console.ReadLine(); Environment.Exit(-1); } Console.ReadLine(); } /** * Computes the SHA-256 tree hash for the given file * * @param inputFile * A file to compute the SHA-256 tree hash for * @return a byte[] containing the SHA-256 tree hash */ public static byte[] ComputeSHA256TreeHash(FileStream inputFile) { byte[][] chunkSHA256Hashes = GetChunkSHA256Hashes(inputFile); return ComputeSHA256TreeHash(chunkSHA256Hashes); } /** * Computes a SHA256 checksum for each 1 MB chunk of the input file. This * includes the checksum for the last chunk even if it is smaller than 1 MB. * * @param file * A file to compute checksums on * @return a byte[][] containing the checksums of each 1MB chunk */ public static byte[][] GetChunkSHA256Hashes(FileStream file) { long numChunks = file.Length / ONE_MB; if (file.Length % ONE_MB > 0) { numChunks++; } if (numChunks == 0) { return new byte[][] { CalculateSHA256Hash(null, 0) }; } byte[][] chunkSHA256Hashes = new byte[(int)numChunks][]; try { byte[] buff = new byte[ONE_MB]; int bytesRead; int idx = 0; while ((bytesRead = file.Read(buff, 0, ONE_MB)) > 0) { chunkSHA256Hashes[idx++] = CalculateSHA256Hash(buff, bytesRead); } return chunkSHA256Hashes; } finally { if (file != null) { try { file.Close(); } catch (IOException ioe) { throw ioe; } } } } /** * Computes the SHA-256 tree hash for the passed array of 1MB chunk * checksums. * * This method uses a pair of arrays to iteratively compute the tree hash * level by level. Each iteration takes two adjacent elements from the * previous level source array, computes the SHA-256 hash on their * concatenated value and places the result in the next level's destination * array. At the end of an iteration, the destination array becomes the * source array for the next level. * * @param chunkSHA256Hashes * An array of SHA-256 checksums * @return A byte[] containing the SHA-256 tree hash for the input chunks */ public static byte[] ComputeSHA256TreeHash(byte[][] chunkSHA256Hashes) { byte[][] prevLvlHashes = chunkSHA256Hashes; while (prevLvlHashes.GetLength(0) > 1) { int len = prevLvlHashes.GetLength(0) / 2; if (prevLvlHashes.GetLength(0) % 2 != 0) { len++; } byte[][] currLvlHashes = new byte[len][]; int j = 0; for (int i = 0; i < prevLvlHashes.GetLength(0); i = i + 2, j++) { // If there are at least two elements remaining if (prevLvlHashes.GetLength(0) - i > 1) { // Calculate a digest of the concatenated nodes byte[] firstPart = prevLvlHashes[i]; byte[] secondPart = prevLvlHashes[i + 1]; byte[] concatenation = new byte[firstPart.Length + secondPart.Length]; System.Buffer.BlockCopy(firstPart, 0, concatenation, 0, firstPart.Length); System.Buffer.BlockCopy(secondPart, 0, concatenation, firstPart.Length, secondPart.Length); currLvlHashes[j] = CalculateSHA256Hash(concatenation, concatenation.Length); } else { // Take care of remaining odd chunk currLvlHashes[j] = prevLvlHashes[i]; } } prevLvlHashes = currLvlHashes; } return prevLvlHashes[0]; } public static byte[] CalculateSHA256Hash(byte[] inputBytes, int count) { SHA256 sha256 = System.Security.Cryptography.SHA256.Create(); byte[] hash = sha256.ComputeHash(inputBytes, 0, count); return hash; } } }
