Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
AWS AppSync introducción a la plantilla de mapeo de resolución
nota
Ahora admitimos de forma básica el tiempo de ejecución APPSYNC_JS y su documentación. Considere la opción de utilizar el tiempo de ejecución APPSYNC_JS y sus guías aquí.
AWS AppSync le permite responder a las solicitudes de GraphQL realizando operaciones en sus recursos. Para cada campo de GraphQL en el que desee ejecutar una consulta o mutación, se debe asociar un solucionador a fin de comunicarse con un origen de datos. La comunicación se suele realizar a través de parámetros u operaciones que son exclusivos para cada origen de datos.
Los solucionadores son los conectores entre GraphQL y un origen de datos. Indican AWS AppSync cómo traducir una solicitud de GraphQL entrante en instrucciones para su fuente de datos de backend y cómo traducir la respuesta de esa fuente de datos de nuevo en una respuesta de GraphQL. Están escritas en Apache Velocity Template Language (VTL)
Existen dos tipos de resolutores AWS AppSync que utilizan las plantillas de mapeo de formas ligeramente diferentes:
-
Solucionadores de unidad
-
Solucionadores de canalización
Solucionadores de unidad
Los solucionadores de unidad son entidades autónomas que incluyen solo una plantilla de solicitud y respuesta. Utilícelos para operaciones sencillas y únicas, como enumerar elementos de un único origen de datos.
-
Plantillas de solicitud: toman la solicitud entrante después de analizar una operación de GraphQL y la convierten en una configuración de solicitud para la operación del origen de datos seleccionado.
-
Plantillas de respuesta: interpretan respuestas del origen de datos y las mapean a la forma del tipo de resultado del campo de GraphQL.
Solucionadores de canalización
Los solucionadores de canalización contienen una o varias funciones que se realizan en orden secuencial. Cada función incluye una plantilla de solicitud y otra de respuesta. Un solucionador de canalización también tiene una plantilla Antes y Después alrededor de la secuencia de funciones que contiene la plantilla. La plantilla Después se mapea al tipo de resultado del campo de GraphQL. Los solucionadores de canalización se diferencian de los solucionadores de unidad en la forma en que la plantilla de respuesta mapea el resultado. Un solucionador de canalización puede mapearse a cualquier resultado que desee, incluida la entrada de otra función o la plantilla Después del solucionador de canalización.
Las funciones de solucionador de canalización permiten escribir lógica común que puede reutilizar en varios solucionadores de su esquema. Las funciones están asociadas directamente a un origen de datos y, como un solucionador de unidad, contienen el mismo formato de plantilla de mapeo de solicitudes y respuestas.
En el siguiente diagrama se muestra el flujo de procesos de un solucionador de unidad a la izquierda y un solucionador de canalización a la derecha.
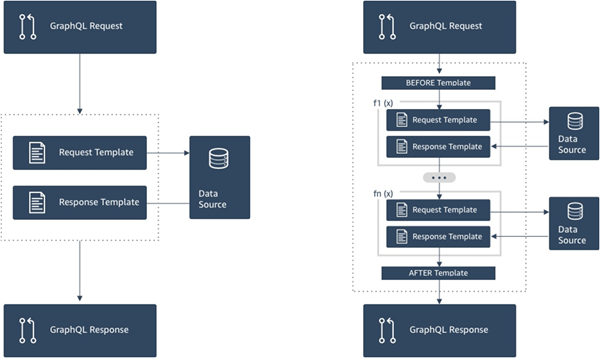
Los solucionadores de canalización contienen un superconjunto de la funcionalidad que admiten los solucionadores de unidad, entre otros, por el coste de un poco más de complejidad.
Anatomía de un solucionador de canalización
Un solucionador de canalización se compone de una plantilla de mapeo Antes, una plantilla de mapeo Después y una lista de funciones. Cada función tiene una plantilla de mapeo de solicitudes y respuestas que ejecuta con un origen de datos. Puesto que un solucionador de canalización delega la ejecución a una lista de funciones, no está vinculado a ningún origen de datos. Las funciones y los solucionadores de unidad son primitivos que ejecutan la operación frente a los orígenes de datos. Para obtener más información, consulte Información general sobre las plantillas de mapeo de solucionador.
Plantilla de mapeo Antes
La plantilla de mapeo de solicitudes de un solucionador de canalización, también denominado paso Antes, permite realizar alguna lógica de preparación antes de ejecutar las funciones definidas.
Lista de funciones
La lista de funciones de un solucionador de canalización se ejecutará de forma secuencial. El resultado evaluado de la plantilla de mapeo de solicitud del solucionador de canalización estará disponible para la primera función como $ctx.prev.result. Cada resultado de función está disponible para la siguiente función como $ctx.prev.result.
Plantilla de mapeo After (Después)
La plantilla de mapeo de respuestas de un solucionador de canalización, también denominado paso Después, permite realizar alguna lógica de mapeo final a partir del resultado de la última función al tipo de campo de GraphQL esperado. El resultado de la última función en lista de funciones está disponible en la plantilla de mapeo del solucionador de canalización como $ctx.prev.result o $ctx.result.
Flujo de la ejecución
Con un solucionador de canalización compuesto por dos funciones, la lista siguiente representa el flujo de ejecución cuando se invoca el solucionador:

-
Plantilla de mapeo Antes de solucionador de canalización
-
Función 1: Plantilla de mapeo de solicitud de función
-
Función 1: Invocación de origen de datos
-
Función 1: Plantilla de mapeo de respuesta de función
-
Función 2: Plantilla de mapeo de solicitud de función
-
Función 2: Invocación de origen de datos
-
Función 2: Plantilla de mapeo de respuesta de función
-
Plantilla de mapeo Después de solucionador de canalización
nota
El flujo de ejecución del solucionador de canalización es unidireccional y se define estáticamente en el solucionador.
Utilidades prácticas de Apache Velocity Template Language (VTL)
A medida que aumenta la complejidad de una aplicación, las utilidades y directivas de VTL están para facilitar la productividad de desarrollo. Las siguientes utilidades pueden ayudar cuando se trabaja con solucionadores de canalización.
$ctx.stash
El "stash" es un Map que está disponible dentro de cada solucionador y plantilla de mapeo de funciones. La misma instancia stash vive en una única ejecución de solucionador. Esto significa que puede utilizar el stash para transferir datos arbitrarios en plantillas de mapeo de solicitudes y respuestas, así como en funciones de un solucionador de canalización. El stash expone los mismos métodos que la estructura de datos del mapa de Java
$ctx.prev.result
El $ctx.prev.result representa el resultado de la operación anterior que se ha ejecutado en el solucionador de canalización.
Si la operación anterior era la plantilla de mapeo Antes del solucionador de canalización, entonces $ctx.prev.result representa el resultado de la evaluación de la plantilla y estará disponible para la primera función de la canalización. Si la operación anterior era la primera función, entonces $ctx.prev.result representa el resultado de la primera función y estará disponible para la segunda función de la canalización. Si la operación anterior era la última función, entonces $ctx.prev.result representa el resultado de la última función y estará disponible para la plantilla de mapeo Después del solucionador de canalización.
#return(data: Object)
La directiva #return(data: Object) es útil si necesita para devolver de forma prematura de cualquier plantilla de mapeo. #return(data: Object) es análogo a la palabra clave de return (devolución) en los lenguajes de programación, ya que vuelve desde el bloque de lógica del ámbito más cercano. Esto significa que utilizar #return dentro de una plantilla de mapeo vuelve desde el solucionador. El uso de #return(data: Object) en una plantilla de mapeo de solucionador establece data en el campo GraphQL. Además, el uso de #return(data: Object) partir de una plantilla de mapeo de función vuelve desde la función y continúa la ejecución a la siguiente función en la canalización o a la plantilla de mapeo de respuesta del solucionador.
#return
Equivale a #return(data: Object), pero se devolverá null en su lugar.
$util.error
La utilidad $util.error es útil para lanzar un error de campo. El uso de $util.error dentro de una plantilla de mapeo de función genera un error de campo inmediatamente, lo que impide que se ejecuta funciones posteriores. Para obtener información más detallada y otras firmas de $util.error, visite el artículo sobre la referencia de utilidad de la plantilla de mapeo de solucionador.
$util.appendError
El $util.appendError es similar a $util.error(), siendo la principal diferencia que no interrumpe la evaluación de la plantilla de mapeo. En su lugar, indica que hubo un error con el campo, pero permite evaluar la plantilla y, por tanto, devolver los datos. El uso de $util.appendError dentro de una función no interrumpe el flujo de ejecución de la canalización. Para obtener información más detallada y otras firmas de $util.error, visite el artículo sobre la referencia de utilidad de la plantilla de mapeo de solucionador.
Plantilla de ejemplo
Supongamos que tiene un origen de datos de DynamoDB y un solucionador de unidad para un campo llamado getPost(id:ID!) que devuelve un tipo Post con la consulta de GraphQL siguiente:
getPost(id:1){ id title content }
La plantilla del solucionador puede ser parecida a la siguiente:
{ "version" : "2018-05-29", "operation" : "GetItem", "key" : { "id" : $util.dynamodb.toDynamoDBJson($ctx.args.id) } }
Esto sustituiría el valor 1 del parámetro de entrada id para ${ctx.args.id} y generaría el siguiente JSON:
{ "version" : "2018-05-29", "operation" : "GetItem", "key" : { "id" : { "S" : "1" } } }
AWS AppSync utiliza esta plantilla para generar instrucciones para comunicarse con DynamoDB y obtener datos (o realizar otras operaciones, según proceda). Una vez que se devuelven los datos, AWS AppSync los pasa por una plantilla de mapeo de respuesta opcional que puede utilizar para dar forma los datos o efectuar operaciones lógicas. Por ejemplo, cuando se obtienen los resultados de DynamoDB podrían tener este aspecto:
{ "id" : 1, "theTitle" : "AWS AppSync works offline!", "theContent-part1" : "It also has realtime functionality", "theContent-part2" : "using GraphQL" }
Puede elegir unir dos de los campos en uno solo con la siguiente plantilla de mapeo de respuesta:
{ "id" : $util.toJson($context.data.id), "title" : $util.toJson($context.data.theTitle), "content" : $util.toJson("${context.data.theContent-part1} ${context.data.theContent-part2}") }
Esta es la forma de los datos después de aplicarles la plantilla:
{ "id" : 1, "title" : "AWS AppSync works offline!", "content" : "It also has realtime functionality using GraphQL" }
Estos datos se entregan como respuesta al cliente de este modo:
{ "data": { "getPost": { "id" : 1, "title" : "AWS AppSync works offline!", "content" : "It also has realtime functionality using GraphQL" } } }
Observe que, en la mayoría de los casos, las plantillas de mapeo de respuesta simplemente transfieren los datos, y en ellas la máxima diferencia consiste en devolver un elemento individual o una lista de elementos. En el caso de un elemento individual la transferencia es:
$util.toJson($context.result)
Para las listas, la transferencia suele ser:
$util.toJson($context.result.items)
Para ver más ejemplos de solucionadores de unidad y canalización, consulte los tutoriales de solucionadores.
Reglas de deserialización de plantillas de mapeo evaluadas
Las plantillas de asignación se evalúan en función de una cadena. En AWS AppSync, la cadena de salida debe seguir una estructura JSON para ser válida.
Además, se aplican las siguientes reglas de deserialización.
No se permiten claves duplicadas en objetos JSON
Si la cadena de la plantilla de asignación evaluada representa un objeto JSON o contiene un objeto con claves duplicadas, la plantilla de asignación devuelve el siguiente mensaje de error:
Duplicate field 'aField' detected on Object. Duplicate JSON keys are not
allowed.
Ejemplo de una clave duplicada en una plantilla de asignación de solicitudes evaluada:
{ "version": "2018-05-29", "operation": "Invoke", "payload": { "field": "getPost", "postId": "1", "field": "getPost" ## key 'field' has been redefined } }
Para corregir este error, no redefina las claves en objetos JSON.
No se permiten caracteres finales en objetos JSON
Si la cadena de la plantilla de asignación evaluada representa un objeto JSON y contiene caracteres extraños al final, la plantilla de asignación devuelve el siguiente mensaje de error:
Trailing characters at the end of the JSON string are not allowed.
Ejemplo de caracteres finales en una plantilla de asignación de solicitudes evaluada:
{ "version": "2018-05-29", "operation": "Invoke", "payload": { "field": "getPost", "postId": "1", } }extraneouschars
Para corregir este error, asegúrese de que las plantillas evaluadas se evalúen estrictamente en función de JSON.
