Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Conector para HBase de Amazon Athena
El conector de Amazon Athena HBase permite a Amazon Athena comunicarse con las instancias de Apache HBase para que pueda consultar los datos de HBase con SQL.
A diferencia de los almacenes de datos relacionales tradicionales, las colecciones de HBase no tienen ningún esquema establecido. HBase no tiene un almacén de metadatos. Cada entrada de una colección de HBase puede tener diferentes campos y tipos de datos.
El conector de HBase admite dos mecanismos para generar información de esquema de la tabla: inferencia básica de esquemas y metadatos de AWS Glue Data Catalog.
La inferencia de esquemas es la opción predeterminada. Esta opción escanea una pequeña cantidad de documentos de la colección, forma una unión de todos los campos y fuerza a los campos que no tienen tipos de datos superpuestos. Esta opción funciona bien para colecciones que, en su mayoría, tienen entradas uniformes.
Para las recopilaciones con una mayor variedad de tipos de datos, el conector admite la recuperación de metadatos de AWS Glue Data Catalog. Si el conector ve una base de datos y una tabla de AWS Glue que coinciden con los nombres del espacio de nombres y de las colecciones de HBase, obtiene la información del esquema de la tabla de AWS Glue. Al crear la tabla de AWS Glue, le recomendamos que la convierta en un superconjunto de todos los campos a los que quiera acceder desde su colección de HBase.
Si Lake Formation está habilitado en la cuenta, el rol de IAM del conector de Lambda federado de Athena que haya implementado en AWS Serverless Application Repository debe tener acceso de lectura en Lake Formation para AWS Glue Data Catalog.
Requisitos previos
Implemente el conector en su Cuenta de AWS mediante la consola de Athena o AWS Serverless Application Repository. Para obtener más información, consulte Implementación de un conector de origen de datos o Uso de AWS Serverless Application Repository para implementar un conector de origen de datos.
Parámetros
Use las variables de entorno de Lambda de esta sección para configurar el conector de HBase.
-
spill_bucket: especifica el bucket de Amazon S3 para los datos que superen los límites de la función de Lambda.
-
spill_prefix: (opcional) de forma predeterminada, se establece una subcarpeta en la carpeta especificada
spill_bucketllamadaathena-federation-spill. Le recomendamos configurar un ciclo de vida de almacenamiento de Amazon S3 en esta ubicación para eliminar vertidos de más de un número predeterminado de días u horas. -
spill_put_request_headers: (opcional) un mapa codificado en JSON de encabezados y valores de solicitudes para la solicitud
putObjectde Amazon S3 que se usa para el vertidos (por ejemplo,{"x-amz-server-side-encryption" : "AES256"}). Para ver otros encabezados posibles, consulte PutObject en la referencia de la API de Amazon Simple Storage Service. -
kms_key_id: (opcional) de forma predeterminada, los datos que se vierten a Amazon S3 se cifran mediante el modo de cifrado autenticado AES-GCM y una clave generada aleatoriamente. Para que la función de Lambda use claves de cifrado más seguras generadas por KMS, como
a7e63k4b-8loc-40db-a2a1-4d0en2cd8331, puede especificar un ID de clave de KMS. -
disable_spill_encryption: (opcional) cuando se establece en
True, desactiva el cifrado del vertido. El valor predeterminado esFalse, de modo que los datos que se vierten a S3 se cifran mediante AES-GCM, ya sea mediante una clave generada aleatoriamente o KMS para generar claves. La desactivación del cifrado de vertido puede mejorar el rendimiento, especialmente si su ubicación de vertido usa cifrado del servidor. -
disable_glue: (opcional) si está presente y se establece en true (verdadero), el conector no intentará recuperar metadatos complementarios de AWS Glue.
-
glue_catalog: (opcional) use esta opción para especificar un catálogo de AWS Glue entre cuentas. De forma predeterminada, el conector intenta obtener los metadatos de su propia cuenta de AWS Glue.
-
default_hbase: si está presente, especifica una cadena de conexión de HBase que se utilizará cuando no exista ninguna variable de entorno específica del catálogo.
Especificación de cadenas de conexión
Puede proporcionar una o más propiedades que definan los detalles de conexión de HBase para las instancias de HBase que utiliza con el conector. Para ello, defina una variable de entorno de Lambda que corresponda al nombre del catálogo que quiere usar en Athena. Por ejemplo, suponga que quiere usar las siguientes consultas para consultar dos instancias de HBase diferentes desde Athena:
SELECT * FROM "hbase_instance_1".database.table
SELECT * FROM "hbase_instance_2".database.table
Antes de poder usar estas dos instrucciones SQL, debe agregar dos variables de entorno a la función de Lambda: hbase_instance_1 y hbase_instance_2. El valor de cada una debe ser una cadena de conexión de HBase con el siguiente formato:
master_hostname:hbase_port:zookeeper_port
Uso de los secretos
Si lo desea, puede usar AWS Secrets Manager para obtener parte o la totalidad del valor de los detalles de la cadena de conexión. Para utilizar la característica Consulta federada de Athena con Secrets Manager, la VPC conectada a la función de Lambda debe tener acceso a Internet
Si usa la sintaxis ${my_secret} para poner el nombre de un secreto de Secrets Manager en la cadena de conexión, el conector reemplaza el nombre secreto por los valores de nombre de usuario y contraseña de Secrets Manager.
Por ejemplo, supongamos que establece la variable de entorno de Lambda para hbase_instance_1 en el siguiente valor:
${hbase_host_1}:${hbase_master_port_1}:${hbase_zookeeper_port_1}
El SDK de federación de consultas de Athena intenta recuperar automáticamente un secreto llamado hbase_instance_1_creds de Secrets Manager e inyecta ese valor en lugar de ${hbase_instance_1_creds}. Cualquier parte de la cadena de conexión que se incluya en la combinación de caracteres ${
} se interpreta como un secreto de Secrets Manager. Si especifica un nombre secreto que el conector no puede encontrar en Secrets Manager, el conector no reemplaza el texto.
Configuración de bases de datos y tablas en AWS Glue
La inferencia de esquema integrada del conector solo admite valores que se serializan en HBase como cadenas (por ejemplo, String.valueOf(int)). Debido a que la capacidad de inferencia de esquemas integrada del conector es limitada, es posible que quiera usar AWS Glue como alternativa para obtener metadatos. Para habilitar una tabla de AWS Glue con la intención de usarla con HBase, debe disponer de una tabla y una base de datos de AWS Glue con nombres que coincidan con el espacio de nombres y la tabla de HBase a los que quiere proporcionar metadatos complementarios. El uso de convenciones de nomenclatura de familias de columnas de HBase es opcional y no obligatorio.
Para usar una tabla de AWS Glue para metadatos complementarios
-
Al editar la tabla y la base de datos en la consola de AWS Glue, agregue las siguientes propiedades de tablas:
hbase-metadata-flag: esta propiedad indica al conector de HBase que este puede usar la tabla para obtener metadatos adicionales. Puede proporcionar cualquier valor para
hbase-metadata-flagsiempre y cuando lahbase-metadata-flagesté presente en la lista de propiedades de la tabla.-
hbase-native-storage-flag: utilice este indicador para alternar los dos modos de serialización de valores admitidos por el conector. De forma predeterminada, cuando este campo no está presente, el conector asume que todos los valores se almacenan en HBase como cadenas. Como tal, intentará analizar tipos de datos como
INT,BIGINTyDOUBLEde HBase como cadenas. Si este campo se establece con cualquier valor de la tabla en AWS Glue, el conector cambia al modo de almacenamiento “nativo” e intenta leerINT,BIGINT,BITyDOUBLEcomo bytes mediante las siguientes funciones:ByteBuffer.wrap(value).getInt() ByteBuffer.wrap(value).getLong() ByteBuffer.wrap(value).get() ByteBuffer.wrap(value).getDouble()
-
Asegúrese de usar los tipos de datos adecuados para AWS Glue, como se indica en este documento.
Modelado de familias de columnas
El conector de HBase de Athena admite dos formas de modelar familias de columnas de HBase: nombres totalmente cualificados (aplanados) como family:column, o usar objetos STRUCT.
En el modelo STRUCT, el nombre del campo STRUCT debe coincidir con la familia de columnas y los elementos secundarios de STRUCT deben coincidir con los nombres de las columnas de la familia. Sin embargo, dado que las lecturas de columnas y de inserción de predicados aún no son totalmente compatibles con los tipos complejos como STRUCT, no se recomienda usar STRUCT en este momento.
En la siguiente imagen, se muestra una tabla configurada en AWS Glue que utiliza una combinación de los dos enfoques.
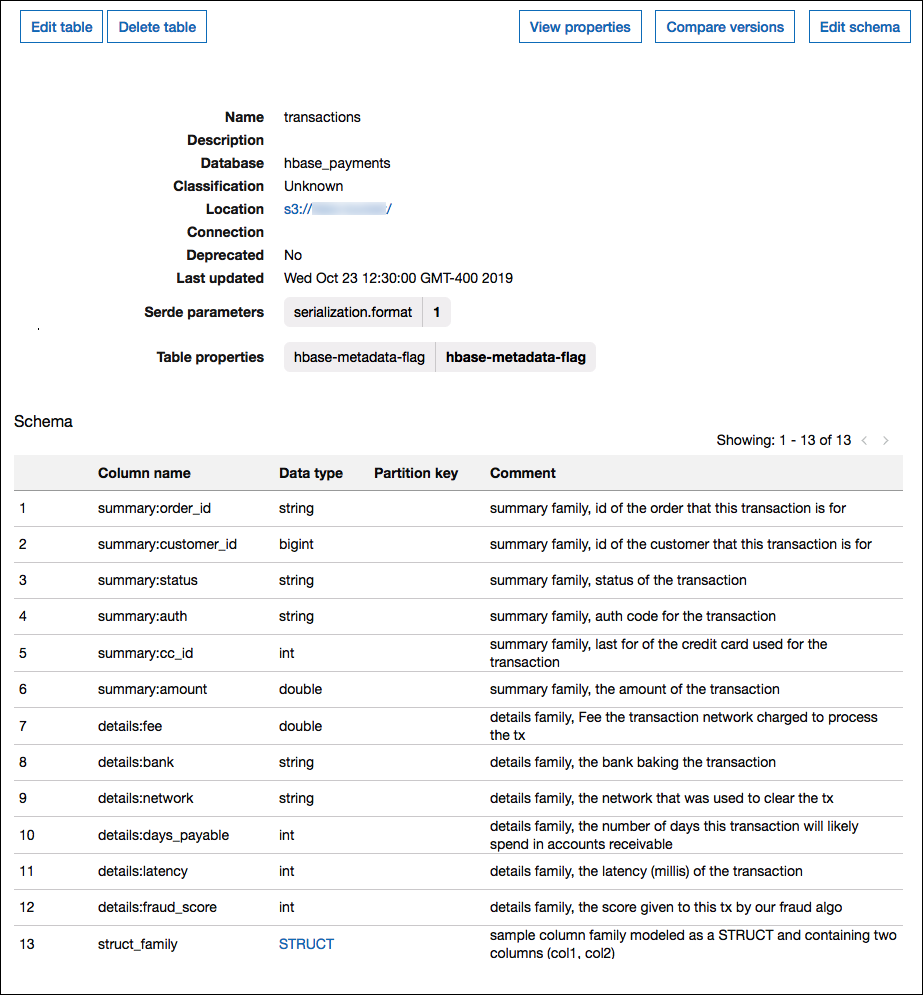
Compatibilidad con tipos de datos
El conector recupera todos los valores de HBase como el tipo de byte básico. A continuación, en función de cómo haya definido las tablas en AWS Glue Data Catalog, asigna los valores a uno de los tipos de datos de Apache Arrow en la siguiente tabla.
| Tipos de datos de AWS Glue | Tipo de datos de Apache Arrow |
|---|---|
| int | INT |
| bigint | BIGINT |
| double | FLOAT8 |
| float | FLOAT4 |
| booleano | BIT |
| binario | VARBINARY |
| string | VARCHAR |
nota
Si no usa AWS Glue para complementar los metadatos, la inferencia de esquemas del conector utiliza solo los tipos de datos BIGINT, FLOAT8 y VARCHAR.
Permisos necesarios
Para obtener información completa sobre las políticas de IAM que requiere este conector, consulte la sección Policies del archivo athena-hbase.yaml
-
Acceso de escritura a Amazon S3: el conector requiere acceso de escritura a una ubicación de Amazon S3 para volcar los resultados de consultas de gran tamaño.
-
Athena GetQueryExecution: el conector usa este permiso para fallar rápidamente cuando finaliza la consulta ascendente de Athena.
-
AWS Glue Data Catalog: el conector de HBase requiere acceso de solo lectura a AWS Glue Data Catalog para obtener información sobre el esquema.
-
Registros de CloudWatch: el conector requiere acceso a Registros de CloudWatch para almacenar registros.
-
Acceso de lectura de AWS Secrets Manager: si decide almacenar los detalles del punto de conexión de HBase en Secrets Manager, debe conceder al conector acceso a esos secretos.
-
Acceso a la VPC: el conector requiere la capacidad de conectar y desconectar interfaces a la VPC para que pueda conectarse a ella y comunicarse con las instancias de HBase.
Desempeño
El conector de HBase de Athena intenta paralelizar las consultas con la instancia de HBase al leer cada servidor de región en paralelo. El conector HBase de Athena inserta predicados para reducir los datos analizados en la consulta.
La función de Lambda también realiza la inserción de proyecciones para reducir los datos analizados por la consulta. Sin embargo, a veces, la selección de un subconjunto de columnas provoca un tiempo de ejecución de consultas más prolongado. Las cláusulas LIMIT reducen la cantidad de datos analizados; sin embargo, si no proporciona un predicado, es probable que las consultas SELECT con una cláusula LIMIT analicen al menos 16 MB de datos.
HBase es propenso a errores en las consultas y a tiempos de ejecución de consulta variables. Es probable que tenga que realizar las consultas varias veces para que se ejecuten correctamente. El conector para HBase resiste las limitaciones debidas a la simultaneidad.
Información sobre licencias
El proyecto del conector de HBase de Amazon Athena tiene una Licencia Apache-2.0
Véase también
Para obtener más información acerca de este conector, consulte el sitio correspondiente
