Uso del AWS Serverless Application Repository para implementar un conector de origen de datos de Hive
Para implementar un conector de origen de datos de Athena para Hive, puede utilizar AWS Serverless Application Repository
Para usar el AWS Serverless Application Repository para implementar un conector de origen de datos para Hive en su cuenta
-
Inicie sesión en la AWS Management Console y abra el repositorio de aplicaciones sin servidor.
-
En el panel de navegación, elija Aplicaciones disponibles.
-
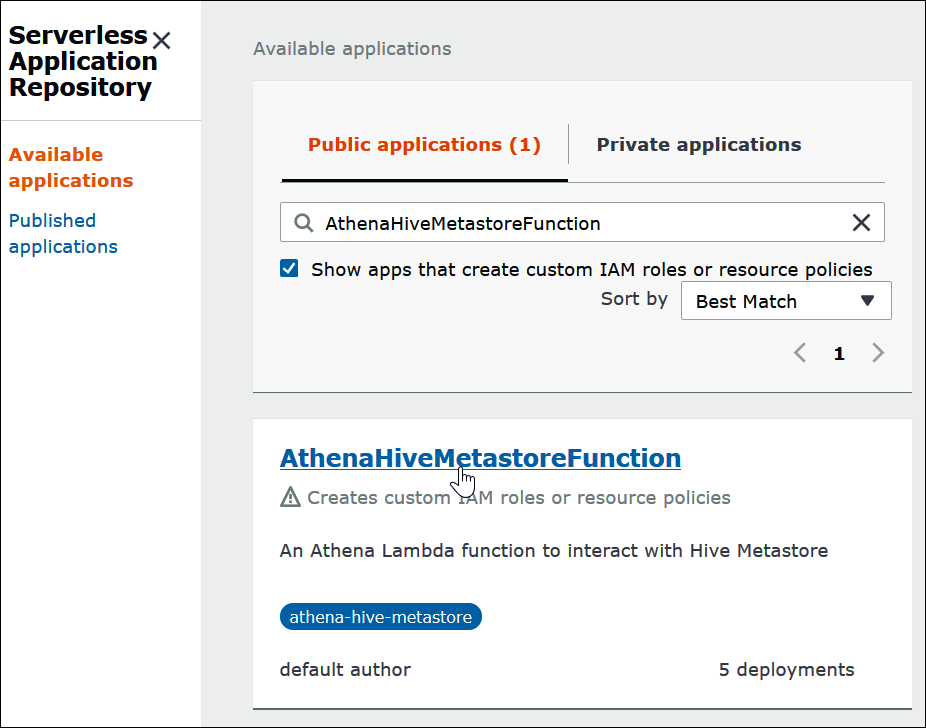
Seleccione la opción Show apps that create custom IAM roles or resource policies (Mostrar aplicaciones que crean roles de IAM personalizados o políticas de recursos).
-
En el cuadro de búsqueda, escriba
Hive. Los conectores que aparecen incluyen los dos siguientes:-
AthenaHiveMetastoreFunction: archivo
.jarde la función de Lambda Uber. -
AthenaHiveMetastoreFunctionWithLayer: capa de Lambda y archivo
.jarde función delgada de Lambda.
Las dos aplicaciones tienen la misma funcionalidad y difieren solo en su implementación. Puede utilizar cualquiera de ellas para crear una función de Lambda que conecte Athena al metaalmacén de Hive.
-
-
Elija el nombre del conector que desea usar. En este tutorial se utiliza AthenaHiveMetastoreFunction.
En Configuración de aplicación, ingrese los parámetros de la función de Lambda.
-
LambdaFuncName: Proporcione un nombre para la función. Por ejemplo, myHiveMetastore.
-
SpillLocation: especifique una ubicación de Amazon S3 en esta cuenta para contener los metadatos de desbordamiento si el tamaño de la respuesta de la función de Lambda supera los 4 MB.
-
HMSUris: ingrese el URI de su host del metaalmacén de Hive que utiliza el protocolo Thrift en el puerto 9083. Utilice la sintaxis
thrift://<host_name>:9083. -
LambdaMemory: especifique un valor comprendido entre 128 y 3008 MB. A la función de Lambda se le asignan ciclos de CPU proporcionales a la cantidad de memoria que configure. El valor predeterminado es 1024.
-
LambdaTimeout: especifique el tiempo máximo permitido de ejecución de invocación Lambda en segundos de 1 a 900 (900 segundos es 15 minutos). El valor predeterminado es 300 segundos (5 minutos).
-
VPCSecurityGroupIds: ingrese una lista separada por comas de ID de grupo de seguridad de la VPC para el metaalmacén de Hive.
-
VPCSubnetIds: ingrese una lista separada por comas de ID de subred de la VPC para el metaalmacén de Hive.
-
-
En la parte inferior derecha de la página Application details (Detalles de la aplicación), seleccione I acknowledge that this app creates custom IAM roles (Confirmo que esta aplicación puede crear roles de IAM personalizados) y, a continuación, elija Deploy (Implementar).
En este punto, puede configurar Athena para que utilice la función de Lambda para conectarse al metaalmacén de Hive. Para ver los pasos, consulte Configuración de Athena para utilizar un conector de almacén de metadatos de Hive implementado.
