Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Funcionamiento de las bases de conocimientos de Amazon Bedrock
Las bases de conocimiento de Amazon Bedrock le ayudan a aprovechar la generación aumentada de recuperación (RAG), una técnica popular que consiste en extraer información de un almacén de datos para aumentar las respuestas generadas por los modelos de lenguaje de gran tamaño (). LLMs Al configurar una base de conocimientos con la fuente de datos, la aplicación puede consultarla para obtener información que permita responder a la consulta, ya sea con citas directas de las fuentes o con respuestas naturales generadas a partir de los resultados de la consulta.
Con las bases de conocimiento de Amazon Bedrock, puede crear aplicaciones que se enriquezcan con el contexto que se recibe al consultar una base de conocimientos. Permite una comercialización más rápida, ya que evita la ardua tarea de crear canalizaciones y le proporciona una solución out-of-the-box RAG para reducir el tiempo de creación de su aplicación. Añadir una base de conocimientos también aumenta la rentabilidad, ya que elimina la necesidad de entrenar continuamente el modelo para poder aprovechar sus datos privados.
Los siguientes diagramas ilustran esquemáticamente cómo se lleva a cabo la RAG. La base de conocimientos simplifica la configuración e implementación de la RAG al automatizar varios pasos de este proceso.
Procesamiento previo de datos no estructurados
Para permitir la recuperación efectiva de datos privados no estructurados (datos que no existen en un almacén de datos estructurados), una práctica habitual consiste en convertir los datos en texto y dividirlos en partes manejables. A continuación, estos fragmentos se convierten en incrustaciones y se escriben en un índice vectorial, manteniendo una correspondencia con el documento original. Estas incrustaciones se utilizan para determinar la similitud semántica entre las consultas y el texto de los orígenes de datos. La siguiente imagen ilustra el preprocesamiento de los datos para la base de datos vectorial.
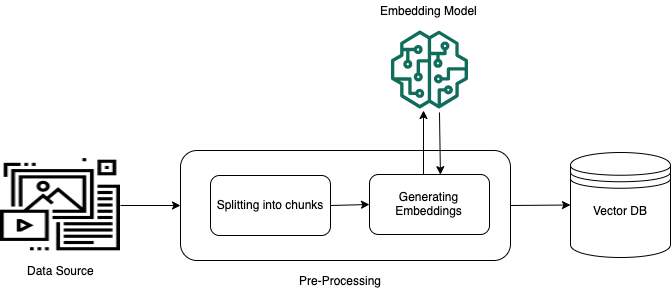
Las incrustaciones vectoriales son una serie de números que representan cada fragmento de texto. Un modelo convierte cada fragmento de texto en series de números, conocidas como vectores, para que los textos se puedan comparar matemáticamente. Estos vectores pueden ser números de punto flotante (float32) o números binarios. La mayoría de los modelos de incrustaciones compatibles con Amazon Bedrock utilizan vectores de punto flotante de forma predeterminada. Sin embargo, algunos modelos admiten vectores binarios. Si elige un modelo de incrustación binario, también debe elegir un modelo y un almacén de vectores que admitan vectores binarios.
Los vectores binarios, que utilizan solo 1 bit por dimensión, no son tan costosos de almacenar como los vectores de punto flotante (float32), que utilizan 32 bits por dimensión. Sin embargo, los vectores binarios no son tan precisos como los vectores de punto flotante en su representación del texto.
El siguiente ejemplo muestra un fragmento de texto en tres representaciones:
| Representación | Valor |
|---|---|
| Texto | «Amazon Bedrock utiliza modelos básicos de alto rendimiento de las principales empresas de IA y Amazon». |
| Vector de punto flotante | [0.041..., 0.056..., -0.018..., -0.012..., -0.020...,
...] |
| Vector binario | [1,1,0,0,0, ...] |
Ejecución en tiempo de ejecución
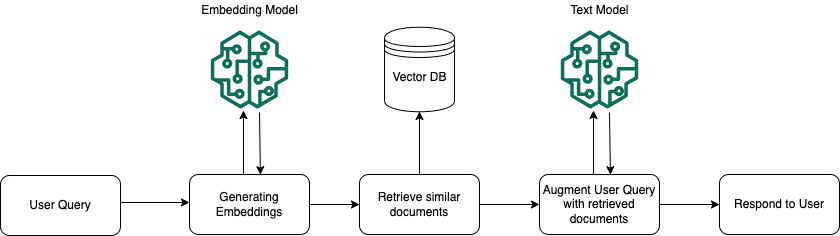
En tiempo de ejecución, se utiliza un modelo de incrustación para convertir la consulta del usuario en un vector. A continuación, se consulta el índice vectorial para buscar fragmentos semánticamente similares a la consulta del usuario, comparando los vectores del documento con el vector de consulta del usuario. En el último paso, la petición del usuario se aumenta con el contexto adicional de los fragmentos que se recuperan del índice vectorial. Luego, la petición, junto con el contexto adicional, se envía al modelo para generar una respuesta para el usuario. La siguiente imagen ilustra cómo funciona la RAG en tiempo de ejecución para aumentar las respuestas a las consultas de los usuarios.
Para obtener más información sobre cómo convertir los datos en una base de conocimientos, cómo consultarla después de configurarla y las personalizaciones que puede aplicar a la fuente de datos durante la ingesta, consulte los siguientes temas:
Temas
