Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Personalizar una función de recompensa
Crear una función de recompensa es como diseñar un plan de incentivos. Los parámetros son valores que se pueden utilizar para desarrollar su plan de incentivos.
Según la estrategia de incentivos que se diseñe, el comportamiento del vehículo será diferente. Para incentivar al vehículo a conducir más rápido, intente conceder valores negativos cuando el vehículo tarde demasiado en terminar una vuelta o se salga de la pista. Para evitar patrones de conducción en zigzag, pruebe a definir un límite de ángulo de dirección y premie al coche por conducir menos agresivamente en los tramos rectos de la pista.
Puede utilizar los waypoints, que son marcadores numerados situados a lo largo de la línea central y los bordes exteriores e interiores de la pista, para ayudarle a asociar determinados comportamientos de conducción con características específicas de una pista, como rectas y curvas.
Crear una función de recompensa eficaz es un proceso creativo y repetitivo. Pruebe diferentes estrategias, combine parámetros y, lo más importante, ¡diviértase!
Temas
Editar el código Python para personalizar su función de recompensa
En AWS DeepRacer Student, puede editar ejemplos de funciones de recompensa para diseñar una estrategia de carreras personalizada para su modelo.
Para personalizar su función de recompensa:
-
En la página Paso 5: Personalizar la función de recompensa de la página de AWS DeepRacer Student Crear modelo, seleccione un ejemplo de función de recompensa.
-
Utilice el editor de código situado debajo del selector de funciones de recompensa de ejemplo para personalizar los parámetros de entrada de la función de recompensa mediante el código Python.
-
Seleccione Validar para comprobar si su código funcionará o no. Como alternativa, seleccione Restablecer para volver a empezar.
-
Cuando termine de realizar cambios, seleccione Siguiente.
Utilice Parámetros de entrada de la función de recompensa de AWS DeepRacer para obtener información sobre cada parámetro. Consulte cómo se utilizan los distintos parámetros en los ejemplos de funciones de recompensa.
Parámetros de entrada de la función de recompensa de AWS DeepRacer
La función de recompensa de AWS DeepRacer coge un objeto del diccionario aprobado como variable, params, como entrada.
def reward_function(params) : reward = ... return float(reward)
El objeto del diccionario params contiene los siguientes pares de clave-valor:
{ "all_wheels_on_track": Boolean, # flag to indicate if the agent is on the track "x": float, # agent's x-coordinate in meters "y": float, # agent's y-coordinate in meters "closest_objects": [int, int], # zero-based indices of the two closest objects to the agent's current position of (x, y). "closest_waypoints": [int, int], # indices of the two nearest waypoints. "distance_from_center": float, # distance in meters from the track center "is_crashed": Boolean, # Boolean flag to indicate whether the agent has crashed. "is_left_of_center": Boolean, # Flag to indicate if the agent is on the left side to the track center or not. "is_offtrack": Boolean, # Boolean flag to indicate whether the agent has gone off track. "is_reversed": Boolean, # flag to indicate if the agent is driving clockwise (True) or counter clockwise (False). "heading": float, # agent's yaw in degrees "objects_distance": [float, ], # list of the objects' distances in meters between 0 and track_length in relation to the starting line. "objects_heading": [float, ], # list of the objects' headings in degrees between -180 and 180. "objects_left_of_center": [Boolean, ], # list of Boolean flags indicating whether elements' objects are left of the center (True) or not (False). "objects_location": [(float, float),], # list of object locations [(x,y), ...]. "objects_speed": [float, ], # list of the objects' speeds in meters per second. "progress": float, # percentage of track completed "speed": float, # agent's speed in meters per second (m/s) "steering_angle": float, # agent's steering angle in degrees "steps": int, # number steps completed "track_length": float, # track length in meters. "track_width": float, # width of the track "waypoints": [(float, float), ] # list of (x,y) as milestones along the track center }
Utilice la siguiente referencia para comprender mejor los parámetros de entrada de AWS DeepRacer.
all_wheels_on_track
Tipo: Boolean
Rango: (True:False)
Una bandera Boolean para indicar si el agente está en la pista o fuera de ella. El agente está fuera de la pista (False) si cualquiera de sus ruedas está fuera de los límites de la pista. Está en la pista (True) si todas las ruedas están dentro de los bordes interiores y exteriores de la pista. La siguiente ilustración muestra un agente que está dentro de la pista.

La siguiente ilustración muestra un agente que no está en la pista debido a que dos ruedas están fuera de los bordes de la pista.

Ejemplo: una función de recompensa utilizando el parámetro all_wheels_on_track.
def reward_function(params): ############################################################################# ''' Example of using all_wheels_on_track and speed ''' # Read input variables all_wheels_on_track = params['all_wheels_on_track'] speed = params['speed'] # Set the speed threshold based your action space SPEED_THRESHOLD = 1.0 if not all_wheels_on_track: # Penalize if the car goes off track reward = 1e-3 elif speed < SPEED_THRESHOLD: # Penalize if the car goes too slow reward = 0.5 else: # High reward if the car stays on track and goes fast reward = 1.0 return float(reward)
closest_waypoints
Tipo: [int, int]
Rango: [(0:Max-1),(1:Max-1)]
Los índices de base cero de los dos waypoint más cercanos a la posición actual (x, y) del agente. La distancia se mide por la distancia euclidiana desde el centro del agente. El primer elemento se refiere al punto de ruta más cercano detrás del agente y el segundo elemento hace referencia al punto de ruta más cercano delante del agente. Max es la longitud de la lista de puntos de ruta. En la ilustración que se muestra en waypoints, los closest_waypoints son [16, 17].
En el siguiente ejemplo, se muestra cómo utilizar la función de recompensa waypoints y closest_waypoints, así como heading para calcular las recompensas inmediatas.
AWS DeepRacer es compatible con las siguientes bibliotecas de Python: math, random, numpy, scipy y shapely. Para utilizarlas, añada una declaración de importación, import , antes de la definición de la función, supported
librarydef
reward_function(params).
Ejemplo: una función de recompensa utilizando el parámetro closest_waypoints.
# Place import statement outside of function (supported libraries: math, random, numpy, scipy, and shapely) # Example imports of available libraries # # import math # import random # import numpy # import scipy # import shapely import math def reward_function(params): ############################################################################### ''' Example of using waypoints and heading to make the car point in the right direction ''' # Read input variables waypoints = params['waypoints'] closest_waypoints = params['closest_waypoints'] heading = params['heading'] # Initialize the reward with typical value reward = 1.0 # Calculate the direction of the centerline based on the closest waypoints next_point = waypoints[closest_waypoints[1]] prev_point = waypoints[closest_waypoints[0]] # Calculate the direction in radius, arctan2(dy, dx), the result is (-pi, pi) in radians track_direction = math.atan2(next_point[1] - prev_point[1], next_point[0] - prev_point[0]) # Convert to degree track_direction = math.degrees(track_direction) # Calculate the difference between the track direction and the heading direction of the car direction_diff = abs(track_direction - heading) if direction_diff > 180: direction_diff = 360 - direction_diff # Penalize the reward if the difference is too large DIRECTION_THRESHOLD = 10.0 if direction_diff > DIRECTION_THRESHOLD: reward *= 0.5 return float(reward)
closest_objects
Tipo: [int, int]
Rango: [(0:len(object_locations)-1),
(0:len(object_locations)-1]
Índices basados en cero de los dos objetos más cercanos a la posición actual (x,y) del agente. El primer índice hace referencia al objeto más cercano situado detrás del agente, mientas que el segundo índice hace referencia al objeto más cercano situado delante. Si solo hay un objeto, ambos índices serán 0.
distance_from_center
Tipo: float
Rango: 0:~track_width/2
Desplazamiento, en metros, entre el centro del agente y el centro de la pista. El desplazamiento máximo observable se produce cuando cualquiera de las ruedas del agente están fuera del límite de la pista y, en función de la anchura de la pista, puede ser ligeramente más pequeña o más grande que la mitad de track_width.

Ejemplo: una función de recompensa utilizando el parámetro distance_from_center.
def reward_function(params): ################################################################################# ''' Example of using distance from the center ''' # Read input variable track_width = params['track_width'] distance_from_center = params['distance_from_center'] # Penalize if the car is too far away from the center marker_1 = 0.1 * track_width marker_2 = 0.5 * track_width if distance_from_center <= marker_1: reward = 1.0 elif distance_from_center <= marker_2: reward = 0.5 else: reward = 1e-3 # likely crashed/ close to off track return float(reward)
heading
Tipo: float
Rango: -180:+180
La dirección del rumbo, en grados, del agente con respecto al eje x del sistema de coordenadas.

Ejemplo: una función de recompensa utilizando el parámetro heading.
Para obtener más información, consulte closest_waypoints.
is_crashed
Tipo: Boolean
Rango: (True:False)
Una bandera Boolean que indica si el agente se chocado contra otro objeto (True) o no (False) como estado de terminación.
is_left_of_center
Tipo: Boolean
Rango: [True : False]
Una bandera Boolean que indica si el agente está a la izquierda del centro de la pista (True) o no está a la izquierda del centro de la pista (False).
is_offtrack
Tipo: Boolean
Rango: (True:False)
Una bandera Boolean que indica si las cuatro ruedas del agente se han desplazado fuera de los bordes interiores o exteriores de la pista (True) o no (False).
is_reversed
Tipo: Boolean
Rango: [True:False]
Una bandera Boolean que indica si el agente conduce en el sentido de las agujas del reloj (True) o en el sentido contrario a las agujas del reloj (False).
Se utiliza cuando se habilita el cambio de dirección para cada episodio.
objects_distance
Tipo: [float, … ]
Rango: [(0:track_length), … ]
Una lista de distancias entre objetos del entorno en relación con la línea de salida. El elemento ith mide la distancia en metros entre el objeto ith y la línea de salida a lo largo de la línea central de la pista.
nota
abs | (var1) - (var2)| = a qué distancia está el coche de un objeto, WHEN var1 = ["objects_distance"][index] y var2 = params["progress"]*params["track_length"]
Para obtener un índice del objeto más cercano delante del vehículo y del objeto más cercano detrás del vehículo, utilice el parámetro closest_objects.
objects_heading
Tipo: [float, … ]
Rango: [(-180:180), … ]
Lista de los encabezados de los objetos en grados. El elemento ith mide el encabezado del objeto ith. Los encabezados de los objetos estacionarios son 0. Para un vehículo robot, el valor del elemento correspondiente es el ángulo de dirección del vehículo robot.
objects_left_of_center
Tipo: [Boolean, … ]
Rango: [True|False, … ]
Lista de banderas Boolean. El valor del elemento ith indica si el objeto ith está en el lado izquierdo (True) o derecho (False) del centro de la pista.
objects_location
Tipo: [(x,y), ...]
Rango: [(0:N,0:N), ...]
Este parámetro almacena todas las ubicaciones de los objetos. Cada ubicación es una tupla de (x, y).
El tamaño de la lista es igual al número de objetos en la pista. Los objetos de la lista incluyen tanto obstáculos estacionarios como vehículos robot en movimiento.
objects_speed
Tipo: [float, … ]
Rango: [(0:12.0), … ]
Lista de velocidades (metros por segundo) para los objetos en la pista. En objetos estacionarios, las velocidades son 0. En un vehículo robot, el valor es la velocidad que se establece en el entrenamiento.
progress
Tipo: float
Rango: 0:100
Porcentaje de pista completado.
Ejemplo: una función de recompensa utilizando el parámetro progress.
Para obtener más información, consulte pasos.
speed
Tipo: float
Rango: 0.0:5.0
La velocidad observada del agente, en metros por segundo (m/s).

Ejemplo: una función de recompensa utilizando el parámetro speed.
Para obtener más información, consulte la sección all_wheels_on_track.
steering_angle
Tipo: float
Rango: -30:30
Ángulo de dirección, en grados, de las ruedas delanteras desde la línea central del agente. El signo negativo (-) significa maniobrar hacia la derecha y el signo positivo (+) significa maniobrar hacia la izquierda. La línea central del agente no es necesariamente paralela a la línea central de la pista, como se muestra en la siguiente ilustración.

Ejemplo: una función de recompensa utilizando el parámetro steering_angle.
def reward_function(params): ''' Example of using steering angle ''' # Read input variable abs_steering = abs(params['steering_angle']) # We don't care whether it is left or right steering # Initialize the reward with typical value reward = 1.0 # Penalize if car steer too much to prevent zigzag ABS_STEERING_THRESHOLD = 20.0 if abs_steering > ABS_STEERING_THRESHOLD: reward *= 0.8 return float(reward)
pasos
Tipo: int
Rango: 0:Nstep
Número de pasos finalizados. Un paso corresponde a una secuencia de observación-acción completada por el agente utilizando la política actual.
Ejemplo: una función de recompensa utilizando el parámetro steps.
def reward_function(params): ############################################################################# ''' Example of using steps and progress ''' # Read input variable steps = params['steps'] progress = params['progress'] # Total num of steps we want the car to finish the lap, it will vary depends on the track length TOTAL_NUM_STEPS = 300 # Initialize the reward with typical value reward = 1.0 # Give additional reward if the car pass every 100 steps faster than expected if (steps % 100) == 0 and progress > (steps / TOTAL_NUM_STEPS) * 100 : reward += 10.0 return float(reward)
track_length
Tipo: float
Rango: [0:Lmax]
La longitud de la pista en metros. Lmax is track-dependent.
track_width
Tipo: float
Rango: 0:Dtrack
Ancho de la pista en metros.

Ejemplo: una función de recompensa utilizando el parámetro track_width.
def reward_function(params): ############################################################################# ''' Example of using track width ''' # Read input variable track_width = params['track_width'] distance_from_center = params['distance_from_center'] # Calculate the distance from each border distance_from_border = 0.5 * track_width - distance_from_center # Reward higher if the car stays inside the track borders if distance_from_border >= 0.05: reward = 1.0 else: reward = 1e-3 # Low reward if too close to the border or goes off the track return float(reward)
x, y
Tipo: float
Rango: 0:N
Localización, en metros, del centro del agente a lo largo de los ejes x e y del entorno simulado que contiene la pista. El origen se encuentra en el ángulo inferior izquierdo del entorno simulado.

waypoints
Tipo: list de [float, float]
Rango: [[xw,0,yw,0] …
[xw,Max-1,
yw,Max-1]]
Una lista ordenada de hitos Max dependientes de la pista a lo largo del centro de la pista. Cada hito se describe mediante una coordenada de (xw,i, yw,i). Para una pista en bucle, el primer y el último señalador son los mismos. Para una pista recta u otra pista no en bucle, el primer y el último señalador son distintos.
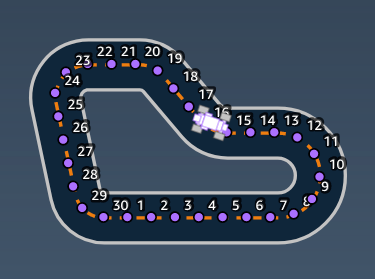
Ejemplo: una función de recompensa utilizando el parámetro waypoints.
Para obtener más información, consulte closest_waypoints.
