Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Realizar copias de seguridad de los sistemas de archivos Amazon EFS mediante AWS Data Pipeline
En este tema se proporciona información sobre el uso de AWS Data Pipeline, que es una solución de copia de seguridad y restauración antigua para sistemas de archivos EFS.
nota
AWS Backup es la solución de copia de seguridad y restauración recomendada para los sistemas de archivos EFS. Para obtener más información, consulte Copia de seguridad de los sistemas de archivos de Amazon EFS.
Con AWS Data Pipeline, se crea una canalización de datos mediante el AWS Data Pipeline servicio. Esta canalización copia datos desde su sistema de archivos de Amazon EFS (denominado el sistema de archivos de producción) en otro sistema de archivos de Amazon EFS (denominado el sistema de archivos de copia de seguridad).
AWS Data Pipeline consta de plantillas que implementan lo siguiente:
-
Copias de seguridad automatizadas basadas en un programa que usted defina (por ejemplo, cada hora, cada día, cada semana o cada mes).
-
Rotación automática de los backups, donde el backup más antiguo se sustituirá por el más reciente en función del número de backups que desee conservar.
-
Copias de seguridad más rápidas haciendo copia de seguridad solo de los cambios que se han producido entre una copia de seguridad y la siguiente.
-
Almacenamiento eficaz de backups a través de enlaces físicos. Un enlace físico es una entrada de directorio que asocia un nombre a un archivo de un sistema de archivos. Estableciendo un enlace físico, puede realizar una restauración completa de los datos desde cualquier copia de seguridad, almacenando solo lo que ha cambiado entre copia y copia.
Después de configurar la solución de copia de seguridad, este tutorial le muestra cómo acceder a sus copias para restaurar los datos. Esta solución de copia de seguridad depende de la ejecución de los scripts en los que se alojen y GitHub, por lo tanto, está sujeta a GitHub disponibilidad. Si, en su lugar, prefiere eliminar esta dependencia y alojar los scripts en un bucket de Amazon S3, consulte Alojamiento de los scripts rsync en un bucket de Amazon S3.
importante
Es necesario utilizar AWS Data Pipeline esta solución al Región de AWS igual que su sistema de archivos. Dado que AWS Data Pipeline no es compatible en el Este de EE. UU. (Ohio), esta solución no funcionará en dicha región de AWS . Se recomienda que si desea realizar una copia de seguridad del sistema de archivos con esta solución, utilice el sistema de archivos en uno de los otros sistemas compatibles Región de AWS.
Temas
- Rendimiento de las copias de seguridad de Amazon EFS mediante AWS Data Pipeline
- Consideraciones sobre las copias de seguridad de Amazon EFS mediante AWS Data Pipeline
- Supuestos para el backup de Amazon EFS con AWS Data Pipeline
- Cómo hacer una copia de seguridad de un sistema de archivos Amazon EFS con AWS Data Pipeline
- Recursos adicionales de copia de seguridad
Rendimiento de las copias de seguridad de Amazon EFS mediante AWS Data Pipeline
Al realizar backups de datos y restauraciones, el desempeño del sistema de archivos está sujeto a Rendimiento de Amazon EFS, incluidos el punto de referencia y la capacidad de desempeño de ráfaga. El desempeño que utiliza la solución de copia de seguridad se tiene en cuenta en el desempeño total del sistema de archivos. La siguiente tabla ofrece algunas recomendaciones para los tamaños del sistema de archivos de Amazon EFS de la instancia de Amazon EC2 que son compatibles con esta solución, suponiendo que su período de copia de seguridad sea de 15 minutos de duración.
| Tamaño de EFS (Tamaño medio de archivo 30 MB) | Volumen de cambios diario | Horas de ráfagas restantes | Número mínimo de agentes de copia de seguridad |
|---|---|---|---|
| 256 GB | Menos de 25 GB | 6.75 | 1 - m3.medium |
| 512 GB | Menos de 50 GB | 7.75 | 1 - m3.large |
| 1.0 TB | Menos de 75 GB | 11.75 | 2 - m3.large* |
| 1.5 TB | Menos de 125 GB | 11.75 | 2 - m3.xlarge* |
| 2.0 TB | Menos de 175 GB | 11.75 | 3 - m3.large* |
| 3.0 TB | Menos de 250 GB | 11.75 | 4 - m3.xlarge* |
* Estas estimaciones se basan en la suposición de que los datos almacenados en un sistema de archivos de EFS que tenga 1 TB o más se organiza de forma que el backup se pueda distribuir en varios nodos de backup. Los scripts de ejemplo de varios nodos dividen la carga de backup entre nodos en función del contenido del directorio de primer nivel de su sistema de archivos de EFS.
Por ejemplo, si hay dos nodos de copia de seguridad, un nodo realiza la copia de seguridad de todos los archivos y directorios pares ubicados en el directorio de primer nivel, mientras que el nodo impar hace lo mismo para los archivos y directorios impares. En otro ejemplo, con seis directorios en el sistema de archivos de Amazon EFS y cuatro nodos de copia de seguridad, el primer nodo realiza una copia de seguridad del primer y quinto directorio. El segundo nodo realiza una copia de seguridad del segundo y sexto directorio, y el tercer y cuarto nodo realizan una copia de seguridad del tercer y cuarto directorio respectivamente.
Consideraciones sobre las copias de seguridad de Amazon EFS mediante AWS Data Pipeline
Tenga en cuenta lo siguiente a la hora de decidir si desea implementar una solución de copia de seguridad de Amazon EFS utilizando AWS Data Pipeline:
-
Este enfoque de backup de EFS implica una serie de AWS recursos. Para esta solución, tiene que crear lo siguiente:
-
Un sistema de archivos de producción y un sistema de archivos de backup que contiene una copia completa del sistema de archivos de producción. El sistema también contiene todos los cambios incrementales efectuados en los datos durante el período de rotación de las copias de seguridad.
-
Instancias de Amazon EC2, cuyos ciclos de vida son gestionados por AWS Data Pipeline, que realizan restauraciones y copias de seguridad programadas.
-
Una programada periódicamente para realizar copias de seguridad de AWS Data Pipeline los datos.
-
Y AWS Data Pipeline para restaurar copias de seguridad.
Cuando se implementa esta solución, estos servicios se facturan en su cuenta. Para obtener más información, consulte las páginas de precios para Amazon EFS
, Amazon EC2 y AWS Data Pipeline . -
-
Esta no es una solución de copia de seguridad sin conexión. Para garantizar un backup completo y coherente, detenga cualquier escritura de archivo en el sistema de archivos o desmonte el sistema de archivos mientras se realiza el backup. Le recomendamos que realice todas las copias de seguridad durante el tiempo de inactividad programado o durante las horas no laborables.
Supuestos para el backup de Amazon EFS con AWS Data Pipeline
En este tutorial se hacen varias suposiciones y se declaran valores de ejemplo de la siguiente manera:
-
Antes de empezar este tutorial se supone que ya completado Introducción.
-
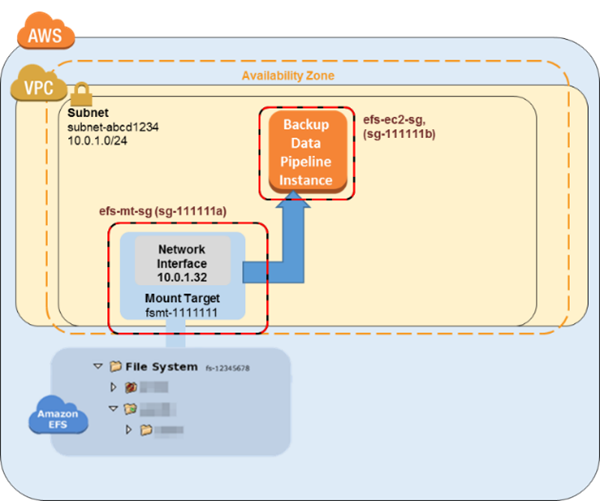
Una vez completado el ejercicio de introducción, dispone de dos grupos de seguridad, una subred de VPC y un destino de montaje de sistema de archivos para el sistema de archivos del que desea realizar un backup. Para el resto de este tutorial, utilice los siguientes valores de ejemplo:
-
El ID del sistema de archivos del que realiza un backup en este tutorial es
fs-12345678. -
El grupo de seguridad del sistema de archivos que se asocia con el destino de montaje se denomina
efs-mt-sg (sg-1111111a). -
El grupo de seguridad que concede a las instancias Amazon EC2 la capacidad de conectarse al punto de montaje de EFS de producción se denomina
efs-ec2-sg (sg-1111111b). -
La subred de VPC tiene el valor de ID de
subnet-abcd1234. -
La dirección IP del destino de montaje del sistema de archivos de origen para el sistema de archivos del que desea realizar un backup es
10.0.1.32:/. -
El ejemplo supone que el sistema de archivos de producción es un sistema de administración de contenido que ofrece archivos multimedia con un tamaño promedio de 30 MB.
-
Los supuestos y ejemplos anteriores se reflejan en el diagrama de configuración inicial siguiente.
Cómo hacer una copia de seguridad de un sistema de archivos Amazon EFS con AWS Data Pipeline
Siga los pasos descritos en esta sección para realizar una copia de seguridad o restaurar su sistema de archivos de Amazon EFS con AWS Data Pipeline.
Temas
Paso 1: Crear su sistema de archivos de Amazon EFS de copia de seguridad
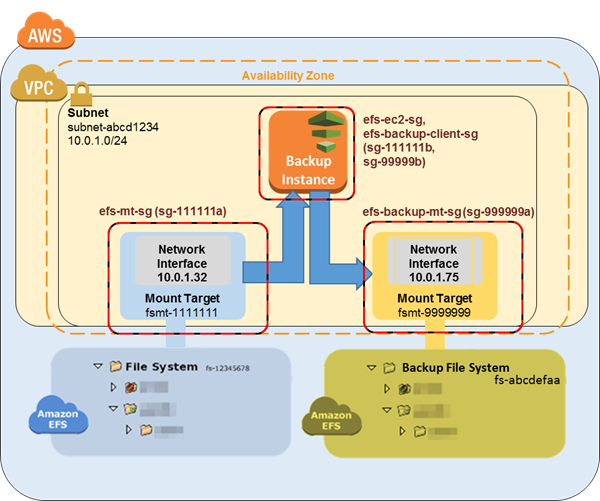
En este tutorial, crea grupos de seguridad independientes, sistemas de archivos y puntos de montaje para separar los backups del origen de datos. En este primer paso, crea dichos recursos:
-
En primer lugar, cree dos nuevos grupos de seguridad. El grupo de seguridad de ejemplo para el destino de montaje de backup es
efs-backup-mt-sg (sg-9999999a). El grupo de seguridad de ejemplo para que la instancia EC2 tenga acceso el destino de montaje esefs-backup-ec2-sg (sg-9999999b). Recuerde crear estos grupos de seguridad en la misma VPC que el volumen de EFS cuyo backup desee realizar. En este ejemplo, la VPC asociada a la subredsubnet-abcd1234. Para obtener más información sobre la creación de grupos de seguridad, consulte Creación de grupos de seguridad. -
A continuación, cree un sistema de archivos de Amazon EFS de copia de seguridad. En este ejemplo, el ID del sistema de archivos es
fs-abcdefaa. Para obtener más información sobre la creación de sistemas de archivos, consulte Creación de sistemas de archivos de Amazon EFS. -
Por último, cree un punto de montaje para el sistema de archivos de backup de EFS y suponga que tiene el valor de
10.0.1.75:/. Para obtener más información sobre la creación de destinos de montaje, consulte Creación y administración de destinos de montaje y grupos de seguridad.
Una vez completado este primer paso, la configuración debe tener un aspecto similar al siguiente diagrama de ejemplo.
Paso 2: Descargue la AWS Data Pipeline plantilla para las copias de seguridad
AWS Data Pipeline le ayuda a procesar y mover datos de manera confiable entre diferentes servicios de AWS cómputo y almacenamiento a intervalos específicos. Con la AWS Data Pipeline consola, puede crear definiciones de canalización preconfiguradas, conocidas como plantillas. Puede utilizar estas plantillas para empezar a utilizarlas AWS Data Pipeline rápidamente. En este tutorial se proporciona una plantilla para facilitar el proceso de configuración de la canalización de backup.
Cuando se realiza la implementación, esta plantilla crea una canalización de datos que lanza una instancia de Amazon EC2 única en el programa que especifique para crear datos de copia de seguridad desde el sistema de archivos de producción al sistema de archivos de copia de seguridad. Esta plantilla tiene una serie de valores de marcador. Los valores coincidentes de esos marcadores de posición se proporcionan en la sección Parámetros de la AWS Data Pipeline consola. Descargue la AWS Data Pipeline plantilla para las copias de seguridad en 1-Node-EFS BackupDataPipeline
nota
Esta plantilla también hace referencia y ejecuta un script para realizar los comandos de backup. Puede descargar el script antes de crear la canalización para revisar lo que hace. Para revisar el script, descargue efs-backup.sh desde.
Paso 3: Crear una canalización de datos para copias de seguridad
Utilice el siguiente procedimiento para crear su canalización de datos.
Para crear una canalización de datos para copias de seguridad de Amazon EFS
-
Abra la AWS Data Pipeline consola en https://console.aws.amazon.com/datapipeline/
. importante
Asegúrese de trabajar de la Región de AWS misma manera que sus sistemas de archivos de Amazon EFS.
-
Elija Create new pipeline (Crear nueva canalización).
-
Añada valores para Name (Nombre) y, opcionalmente, para Description (Descripción).
-
En Source (Origen), elija Import a definition (Importar definición) y después Load local file (Cargar archivo local).
-
En el explorador de archivos, acceda a la plantilla que ha guardado en Paso 2: Descargue la AWS Data Pipeline plantilla para las copias de seguridad y, a continuación, seleccione Open (Abrir).
-
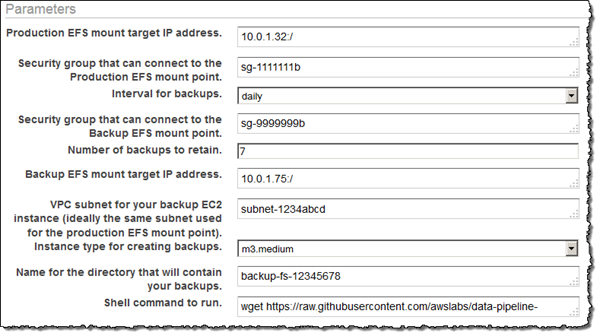
En Parameters (Parámetros), proporcione los detalles de sus sistemas de archivos de EFS de producción y de copia de seguridad.
-
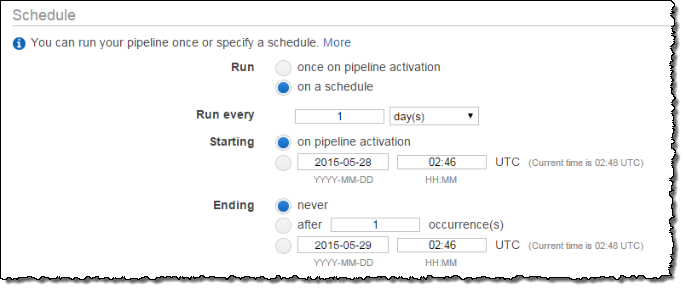
Configure las opciones en Programar para definir el programa de copia de seguridad de Amazon EFS. El backup del ejemplo se ejecuta una vez al día y los backups se conservan durante una semana. Cuando un backup tiene siete días, se sustituye por el siguiente backup más antiguo.
nota
Le recomendamos que especifique un tiempo de ejecución que tenga lugar fuera de las horas punta.
-
(Opcional) Especificar una ubicación de Amazon S3 para almacenar los registros de canalización, configurar un rol de IAM personalizado o añadir etiquetas para describir la canalización.
-
Cuando la canalización esté configurada, seleccione Activate (Activar).
Ya ha configurado y activado su canalización de datos de copia de seguridad de Amazon EFS. Para obtener más información al respecto AWS Data Pipeline, consulte la Guía para AWS Data Pipeline desarrolladores. En este momento, puede realizar el backup ahora como una prueba o puede esperar hasta que el backup se realice a la hora programada.
Paso 4: Acceder a las copias de seguridad de Amazon EFS
La copia de seguridad de Amazon EFS ya se ha creado, activado y se ejecuta según el programa que se ha definido. En este paso se explica cómo puede obtener acceso a sus copias de seguridad de EFS. Los backups se almacenan en el sistema de archivos de backup de EFS que ha creado en el siguiente formato.
backup-efs-mount-target:/efs-backup-id/[backup interval].[0-backup retention]-->
Utilizando los valores del escenario de ejemplo, el backup del sistema de archivos se encuentra en 10.1.0.75:/fs-12345678/daily.[0-6], donde daily.0 es el backup más reciente y daily.6 es el más antiguo de los siete backups en rotación.
El acceso a los backups le ofrece la posibilidad de restablecer datos en su sistema de archivos de producción. Puede optar por restaurar todo un sistema de archivos o puede elegir restaurar archivos individuales.
Paso 4.1: Restaurar una copia de seguridad de Amazon EFS completa
La restauración de una copia de seguridad de un sistema de archivos Amazon EFS requiere otra AWS Data Pipeline, similar a la que configuróPaso 3: Crear una canalización de datos para copias de seguridad. Sin embargo, esta canalización de restauración funciona al revés que la canalización de copia de seguridad. Por lo general, estas restauraciones no están programadas para iniciarse automáticamente.
Al igual que con los backups, las restauraciones se pueden realizar de forma paralela para cumplir el objetivo de tiempo de recuperación. Tenga en cuenta que, al crear una canalización de datos, tiene que programar cuándo desea ejecutarla. Si decide ejecutarla en la activación, inicie el proceso de restauración inmediatamente. Le recomendamos que cree solo una canalización de restauración cuando necesite hacer una restauración o cuando ya tenga un ventana de tiempo específica en mente.
Tanto la EFS de copia de seguridad como la EFS de restauración consumen capacidad de ráfaga. Para obtener más información acerca del desempeño, consulte Rendimiento de Amazon EFS. El siguiente procedimiento le muestra cómo crear e implementar su canalización de restauración.
Para crear una canalización de datos para restauración de datos de EFS
-
Descargue la plantilla de canalización de datos para restaurar los datos de su sistema de archivos de EFS de backup. Esta plantilla lanza una instancia de Amazon EC2 única en función del tamaño especificado. Se lanza solo cuando especifica que se lance. Descargue la AWS Data Pipeline plantilla para las copias de seguridad en 1-Node-EFS RestoreDataPipeline
.json desde. GitHub nota
Esta plantilla también hace referencia y ejecuta un script para realizar los comandos de restauración. Puede descargar el script antes de crear la canalización para revisar lo que hace. Para revisar el script, descargue efs-restore.sh desde.
GitHub -
Abra la AWS Data Pipeline consola en https://console.aws.amazon.com/datapipeline/
. importante
Asegúrese de trabajar de la Región de AWS misma manera que sus sistemas de archivos Amazon EFS y Amazon EC2.
-
Elija Create new pipeline (Crear nueva canalización).
-
Añada valores para Name (Nombre) y, opcionalmente, para Description (Descripción).
-
En Source (Origen), elija Import a definition (Importar definición) y después Load local file (Cargar archivo local).
-
En el explorador de archivos, acceda a la plantilla que ha guardado en Paso 1: Crear su sistema de archivos de Amazon EFS de copia de seguridad y, a continuación, seleccione Open (Abrir).
-
En Parameters (Parámetros), proporcione los detalles de sus sistemas de archivos de EFS de producción y de copia de seguridad.

-
Dado que normalmente solo se realizan restauraciones cuando se necesitan, puede programar la restauración para que se ejecute una vez que se activa la canalización. O programe un restablecimiento único en un momento futuro de su elección, por ejemplo durante una ventana de tiempo fuera de las horas punta.
-
(Opcional) Especificar una ubicación de Amazon S3 para almacenar los registros de canalización, configurar un rol de IAM personalizado o añadir etiquetas para describir la canalización.
-
Cuando la canalización esté configurada, seleccione Activate (Activar).
Ya ha configurado y activado su canalización de datos de restauración de Amazon EFS. Ahora, cuando necesite restaurar una copia de seguridad en su sistema de archivos EFS de producción, solo tiene que activarla desde la AWS Data Pipeline consola. Para obtener más información, consulte la Guía para desarrolladores de AWS Data Pipeline .
Paso 4.2: Restaurar archivos individuales desde sus copias de seguridad de Amazon EFS
Puede restaurar archivos desde las copias de seguridad de su sistema de archivos de Amazon EFS lanzando una instancia de Amazon EC2 para montar temporalmente tanto los sistemas de archivos de EFS de producción como de copia de seguridad. La instancia EC2 debe ser miembro de los dos grupos de seguridad de clientes de EFS (en este ejemplo, efs-ec2-sg y). efs-backup-clients-sg Esta instancia de restauración puede montar ambos destinos de montaje de EFS. Por ejemplo, una instancia EC2 de recuperación puede crear los siguientes puntos de montaje. Aquí, la opción -o ro se utiliza para montar el EFS de copia de seguridad como de solo lectura y evitar su modificación accidental cuando se intenta restaurar a partir de la copia de seguridad.
mount -t nfssource-efs-mount-target:/ /mnt/data
mount -t nfs -o robackup-efs-mount-target:/fs-12345678/daily.0 /mnt/backup>
Una vez montados los destinos, puede copiar archivos desde /mnt/backup en la ubicación adecuada en /mnt/data en el terminal utilizando el comando cp
-p. Por ejemplo, un directorio principal completo (con su sistema de permisos de archivo) se puede copiar recursivamente con el siguiente comando.
sudo cp -rp /mnt/backup/users/my_home /mnt/data/users/my_home
Puede restablecer un archivo único ejecutando el siguiente comando.
sudo cp -p /mnt/backup/user/my_home/.profile /mnt/data/users/my_home/.profile
aviso
Cuando restaure manualmente archivos de datos individuales, tenga cuidado de no modificar accidentalmente la propia copia de seguridad. De lo contrario, podría dañarla.
Recursos adicionales de copia de seguridad
La solución de respaldo que se presenta en este tutorial utiliza plantillas para. AWS Data Pipeline Las plantillas utilizadas en Paso 2: Descargue la AWS Data Pipeline plantilla para las copias de seguridad y Paso 4.1: Restaurar una copia de seguridad de Amazon EFS completa usan una única instancia de Amazon EC2 única para realizar su trabajo. Sin embargo, no hay un límite en el número de instancias en paralelo que puede ejecutar para realizar copias de seguridad o restaurar sus datos en sistemas de archivos de Amazon EFS. En este tema, encontrará enlaces a otras AWS Data Pipeline plantillas configuradas para varias instancias de EC2 que puede descargar y usar para su solución de respaldo. También encontrará instrucciones para modificar las plantillas e incluir instancias adicionales.
Temas
Uso de plantillas adicionales
Puede descargar las siguientes plantillas adicionales desde GitHub:
-
EFS BackupPipeline .json de 2 nodos
: esta plantilla inicia dos instancias de Amazon EC2 paralelas para hacer copias de seguridad del sistema de archivos Amazon EFS de producción. -
EFS RestorePipeline .json de 2 nodos
: esta plantilla inicia dos instancias de Amazon EC2 paralelas para restaurar una copia de seguridad del sistema de archivos Amazon EFS de producción.
Añadir instancias adicionales de copia de seguridad
Puede añadir nodos adicionales a las plantillas de backup que se utilizan en este tutorial. Para añadir un nodo, modifique las secciones siguientes de la plantilla 2-Node-EFSBackupDataPipeline.json.
importante
Si está utilizando nodos adicionales, no puede utilizar espacios en los nombres de archivos y directorios almacenados en el directorio de nivel superior. Si lo hace, no se realiza la copia de seguridad o restauración de dichos archivos y directorios. Se realizará la copia de seguridad y la restauración de todos los archivos y subdirectorios que están al menos un nivel por debajo del nivel superior según lo previsto.
-
Cree un EC2Resource adicional para cada nodo adicional que desee crear (en este ejemplo, una cuarta instancia EC2).
{ "id": "EC2Resource4", "terminateAfter": "70 Minutes", "instanceType": "#{myInstanceType}", "name": "EC2Resource4", "type": "Ec2Resource", "securityGroupIds" : [ "#{mySrcSecGroupID}","#{myBackupSecGroupID}" ], "subnetId": "#{mySubnetID}", "associatePublicIpAddress": "true" }, -
Cree una actividad de canalización de datos adicional para cada nodo adicional (en este caso, actividad
BackupPart4), asegúrese de configurar las secciones siguientes:-
Actualice la referencia
runsOnpara que apunte al EC2Resource creado anteriormente (EC2Resource4en el ejemplo siguiente). -
Aumente los dos últimos valores
scriptArgumentpara igualar la parte de backup que es responsabilidad de cada nodo y el número total de nodos. Para"2"y"3"en el siguiente ejemplo, la parte de copia de seguridad es"3"para el nodo cuarto porque en este ejemplo nuestra lógica del módulo debe contar a partir de 0.
{ "id": "BackupPart4", "name": "BackupPart4", "runsOn": { "ref": "EC2Resource4" }, "command": "wget https://raw.githubusercontent.com/awslabs/data-pipeline-samples/master/samples/EFSBackup/efs-backup-rsync.sh\nchmod a+x efs-backup-rsync.sh\n./efs-backup-rsync.sh $1 $2 $3 $4 $5 $6 $7", "scriptArgument": ["#{myEfsSource}","#{myEfsBackup}", "#{myInterval}", "#{myRetainedBackups}","#{myEfsID}", "3", "4"], "type": "ShellCommandActivity", "dependsOn": { "ref": "InitBackup" }, "stage": "true" }, -
-
Incremente el último valor en todos los valores
scriptArgumentexistentes al número de nodos (en este ejemplo,"4").{ "id": "BackupPart1", ... "scriptArgument": ["#{myEfsSource}","#{myEfsBackup}", "#{myInterval}", "#{myRetainedBackups}","#{myEfsID}", "1", "4"], ... }, { "id": "BackupPart2", ... "scriptArgument": ["#{myEfsSource}","#{myEfsBackup}", "#{myInterval}", "#{myRetainedBackups}","#{myEfsID}", "2", "4"], ... }, { "id": "BackupPart3", ... "scriptArgument": ["#{myEfsSource}","#{myEfsBackup}", "#{myInterval}", "#{myRetainedBackups}","#{myEfsID}", "0", "4"], ... }, -
Actualice la actividad
FinalizeBackupy añada la nueva actividad de backup a la listadependsOn(BackupPart4en este caso).{ "id": "FinalizeBackup", "name": "FinalizeBackup", "runsOn": { "ref": "EC2Resource1" }, "command": "wget https://raw.githubusercontent.com/awslabs/data-pipeline-samples/master/samples/EFSBackup/efs-backup-end.sh\nchmod a+x efs-backup-end.sh\n./efs-backup-end.sh $1 $2", "scriptArgument": ["#{myInterval}", "#{myEfsID}"], "type": "ShellCommandActivity", "dependsOn": [ { "ref": "BackupPart1" }, { "ref": "BackupPart2" }, { "ref": "BackupPart3" }, { "ref": "BackupPart4" } ], "stage": "true"
Añadir instancias de restauración adicionales
Puede añadir nodos a las plantillas de restauración que se utilizan en este tutorial. Para añadir un nodo, modifique las secciones siguientes de la plantilla 2-Node-EFSRestorePipeline.json.
-
Cree un EC2Resource adicional para cada nodo adicional que desea crear (en este caso, una tercera instancias EC2 denominada
EC2Resource3).{ "id": "EC2Resource3", "terminateAfter": "70 Minutes", "instanceType": "#{myInstanceType}", "name": "EC2Resource3", "type": "Ec2Resource", "securityGroupIds" : [ "#{mySrcSecGroupID}","#{myBackupSecGroupID}" ], "subnetId": "#{mySubnetID}", "associatePublicIpAddress": "true" }, -
Cree una actividad de canalización de datos adicional para cada nodo adicional (en este caso, la actividad
RestorePart3). Asegúrese de configurar las secciones siguientes:-
Actualice la referencia
runsOnpara que apunte alEC2Resourcecreado anteriormente (en este ejemplo,EC2Resource3). -
Aumente los dos últimos valores
scriptArgumentpara igualar la parte de backup que es responsabilidad de cada nodo y el número total de nodos. Para"2"y"3"en el siguiente ejemplo, la parte de copia de seguridad es"3"para el nodo cuarto porque en este ejemplo nuestra lógica del módulo debe contar a partir de 0.
{ "id": "RestorePart3", "name": "RestorePart3", "runsOn": { "ref": "EC2Resource3" }, "command": "wget https://raw.githubusercontent.com/awslabs/data-pipeline-samples/master/samples/EFSBackup/efs-restore-rsync.sh\nchmod a+x efs-restore-rsync.sh\n./efs-backup-rsync.sh $1 $2 $3 $4 $5 $6 $7", "scriptArgument": ["#{myEfsSource}","#{myEfsBackup}", "#{myInterval}", "#{myBackup}","#{myEfsID}", "2", "3"], "type": "ShellCommandActivity", "dependsOn": { "ref": "InitBackup" }, "stage": "true" }, -
-
Incremente el último valor en todos los valores
scriptArgumentexistentes al número de nodos (en este ejemplo,"3").{ "id": "RestorePart1", ... "scriptArgument": ["#{myEfsSource}","#{myEfsBackup}", "#{myInterval}", "#{myBackup}","#{myEfsID}", "1", "3"], ... }, { "id": "RestorePart2", ... "scriptArgument": ["#{myEfsSource}","#{myEfsBackup}", "#{myInterval}", "#{myBackup}","#{myEfsID}", "0", "3"], ... },
Alojamiento de los scripts rsync en un bucket de Amazon S3
Esta solución de respaldo depende de la ejecución de scripts rsync alojados en un repositorio de Internet. GitHub Por lo tanto, esta solución de respaldo está sujeta a la disponibilidad del GitHub repositorio. Este requisito significa que si el GitHub repositorio elimina estos scripts o si el GitHub sitio web se desconecta, la solución de copia de seguridad implementada anteriormente no funcionará.
Si prefiere eliminar esta GitHub dependencia, puede optar por alojar los scripts en un bucket de Amazon S3 de su propiedad. A continuación se describen los pasos necesarios para alojar los scripts.
Para alojar los scripts rsync en su propio bucket de Amazon S3
-
Inscríbase AWS y cree un usuario administrativo: si ya tiene uno Cuenta de AWS, continúe y pase al siguiente paso. De lo contrario, consulte Configuración.
-
Cree un bucket de Amazon S3: si ya dispone de un bucket donde desea alojar los scripts rsync, continúe con el siguiente paso. De lo contrario, consulte Creación de un Bucket en la Guía del usuario de Amazon Simple Storage Service.
-
Descargue los scripts y plantillas de rsync: descargue todos los scripts y plantillas de rsync de la carpeta EFSBackup
desde. GitHub Anote la ubicación de su equipo en la que ha descargado estos archivos. -
Cargue los scripts rsync a su bucket de S3: para obtener instrucciones acerca de cómo cargar objetos en su bucket de S3, consulte Añadir un objeto a un bucket en la Guía del usuario de Amazon Simple Storage Service.
-
Cambie los permisos de los scripts rsync cargados para que Everyone (Cualquiera) los pueda Open/Download (Abrir/Descargar). Para obtener instrucciones acerca de cómo cambiar los permisos de un objeto en el bucket de S3, consulte Edición de permisos de objeto en la Guía del usuario de Amazon Simple Storage Service.
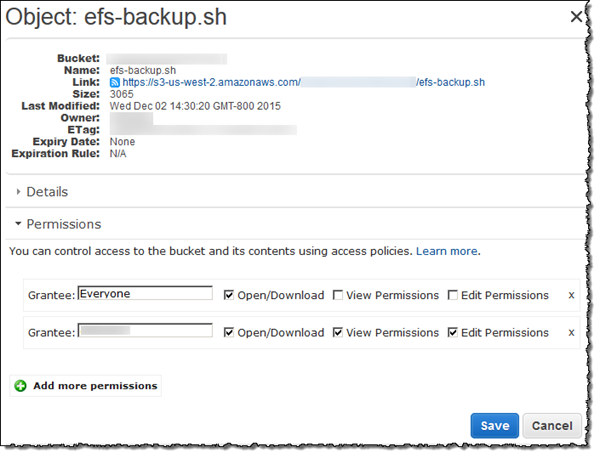
-
Actualice las plantillas: modifique la declaración
wgeten el parámetroshellCmdpara apuntar al bucket de Amazon S3 en el que coloca el script de startup. Guarde la plantilla actualizada y utilice dicha plantilla cuando esté siguiendo el procedimiento en Paso 3: Crear una canalización de datos para copias de seguridad.nota
Le recomendamos que limite el acceso a su bucket de Amazon S3 para incluir la cuenta de IAM que activa esta solución de respaldo. AWS Data Pipeline Para obtener más información, consulte Editar permisos de bucket en la Guía del usuario de Amazon Simple Storage Service.
Ahora aloja los scripts rsync para esta solución de respaldo y sus copias de seguridad ya no dependen GitHub de la disponibilidad.
