Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Teoría de escalado de Kubernetes
Los nodos frente a la tasa de abandono
A menudo, cuando hablamos de la escalabilidad de Kubernetes, lo hacemos en términos del número de nodos que hay en un solo clúster. Curiosamente, esta métrica rara vez es la más útil para entender la escalabilidad. Por ejemplo, un clúster de 5000 nodos con un número grande pero fijo de pods no pondría mucho stress en el plano de control después de la configuración inicial. Sin embargo, si cogiéramos un clúster de 1000 nodos e intentáramos crear 10 000 puestos de trabajo de corta duración en menos de un minuto, se ejercería una gran presión sostenida sobre el plano de control.
El simple hecho de utilizar el número de nodos para entender el escalamiento puede resultar engañoso. Es mejor pensar en términos de la tasa de cambio que se produce dentro de un período de tiempo específico (usemos un intervalo de 5 minutos para esta discusión, ya que esto es lo que las consultas de Prometheus suelen utilizar de forma predeterminada). Exploremos por qué encuadrar el problema en términos de la tasa de cambio puede darnos una mejor idea de qué es lo que debemos ajustar para lograr la escala deseada.
Pensando en consultas por segundo
Kubernetes tiene varios mecanismos de protección para cada componente (el Kubelet, el Scheduler, el Kube Controller Manager y el servidor API) para evitar sobrecargar al siguiente eslabón de la cadena de Kubernetes. Por ejemplo, el Kubelet tiene una bandera para limitar las llamadas al servidor API a una velocidad determinada. Estos mecanismos de protección se expresan generalmente, aunque no siempre, en términos de consultas permitidas por segundo o QPS.
Se debe tener mucho cuidado al cambiar estos ajustes de QPS. Eliminar un obstáculo, como las consultas por segundo en un Kubelet, afectará a otros componentes secundarios. Esto puede sobrecargar al sistema y lo hará a una velocidad superior a determinada, por lo que comprender y monitorear cada parte de la cadena de servicios es clave para escalar correctamente las cargas de trabajo en Kubernetes.
nota
El servidor de API tiene un sistema más complejo, con la introducción de la prioridad y la equidad de la API, que analizaremos por separado.
nota
Precaución: algunas métricas parecen ser las adecuadas, pero de hecho miden otra cosa. Por ejemplo, kubelet_http_inflight_requests se refiere solo al servidor de métricas de Kubelet, no al número de solicitudes de Kubelet a apiserver. Esto podría provocar que configuremos mal el indicador QPS en el Kubelet. Una forma más fiable de comprobar las métricas sería consultar los registros de auditoría de un Kubelet concreto.
Escalar los componentes distribuidos
Como EKS es un servicio gestionado, dividamos los componentes de Kubernetes en dos categorías: componentes gestionados por AWS, que incluyen etcd, Kube Controller Manager y Scheduler (en la parte izquierda del diagrama), y componentes configurables por el cliente, como Kubelet, Container Runtime y los distintos operadores que llaman a AWS, APIs como los controladores de redes y almacenamiento (en la parte derecha del diagrama). Dejamos el servidor de API en el medio aunque esté gestionado por AWS, ya que los clientes pueden configurar los ajustes de Prioridad y Equidad de la API.
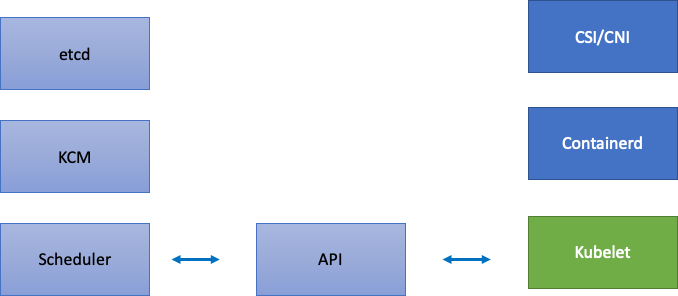
Cuellos de botella ascendentes y descendentes
A medida que supervisamos cada servicio, es importante analizar las métricas en ambas direcciones para detectar cuellos de botella. Aprendamos cómo hacerlo usando Kubelet como ejemplo. Kubelet habla tanto con el servidor API como con el tiempo de ejecución del contenedor. ¿Cómo y qué debemos monitorear para detectar si alguno de los componentes tiene algún problema?
¿Cuántos pods hay por nodo
Si analizamos los números de escalado, como el número de pods que se pueden ejecutar en un nodo, podríamos tomar al pie de la letra los 110 pods por nodo que admite upstream.
Sin embargo, es probable que su carga de trabajo sea más compleja de lo que se probó en una prueba de escalabilidad en Upstream. Para asegurarnos de que podemos dar servicio a la cantidad de módulos que queremos que funcionen en producción, asegurémonos de que el Kubelet está «a la altura» del tiempo de ejecución de Containerd.
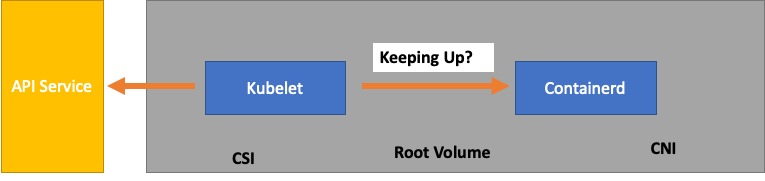
Para simplificar demasiado, el Kubelet obtiene el estado de los pods a partir del tiempo de ejecución del contenedor (en nuestro caso, Containerd). ¿Qué pasaría si muchos pods cambiaran de estado demasiado rápido? Si la tasa de cambio es demasiado alta, las solicitudes [al entorno de ejecución del contenedor] pueden agotarse.
nota
Kubernetes está en constante evolución y, actualmente, este subsistema está experimentando cambios. https://github.com/kubernetes/mejoras/problemas/3386

En el gráfico anterior, vemos una línea plana que indica que acabamos de alcanzar el valor de tiempo de espera de la métrica de duración de la generación de eventos del ciclo de vida del pod. Si quieres ver esto en tu propio clúster, puedes usar la siguiente sintaxis de ProMQL.
increase(kubelet_pleg_relist_duration_seconds_bucket{instance="$instance"}[$__rate_interval])
Si observamos este comportamiento de tiempo de espera, sabremos que hemos llevado al nodo por encima del límite que era capaz de soportar. Tenemos que corregir la causa del tiempo de espera antes de continuar. Esto puede lograrse reduciendo el número de módulos por nodo o buscando errores que puedan estar provocando un gran volumen de reintentos (lo que repercutiría en la tasa de abandono). La conclusión importante es que las métricas son la mejor manera de saber si un nodo es capaz de gestionar la tasa de abandono de los pods asignados en lugar de utilizar un número fijo.
Escale por métricas
Si bien el concepto de usar métricas para optimizar los sistemas es antiguo, a menudo se pasa por alto cuando las personas comienzan su viaje a Kubernetes. En lugar de centrarnos en números específicos (es decir, 110 módulos por nodo), centramos nuestros esfuerzos en encontrar las métricas que nos ayudan a detectar los cuellos de botella en nuestro sistema. Comprender los umbrales correctos para estas métricas puede darnos un alto grado de confianza en que nuestro sistema está configurado de manera óptima.
El impacto de los cambios
Un patrón común que podría causarnos problemas es centrarnos en el primer error métrico o logarítmico que parezca sospechoso. Cuando vimos que el Kubelet estaba agotando el tiempo de espera, podríamos probar cosas al azar, como aumentar la velocidad por segundo que el Kubelet puede enviar, etc. Sin embargo, es aconsejable analizar primero el panorama completo de todas las fases posteriores al error que encontremos. Realice cada cambio con un propósito y respaldado por datos.
Tras el Kubelet, estaría el tiempo de ejecución de Containerd (errores del pod), DaemonSets como el controlador de almacenamiento (CSI) y el controlador de red (CNI) que se comunican con la API, etc. EC2
Continuemos con el ejemplo anterior en el que el Kubelet no está a la altura del tiempo de ejecución. Hay varios puntos en los que podríamos empaquetar un nodo tan densamente que provocara errores.

A la hora de diseñar el tamaño de nodo adecuado para nuestras cargas de trabajo, se trata de easy-to-overlook señales que podrían estar ejerciendo una presión innecesaria sobre el sistema, lo que limitaría tanto nuestra escala como nuestro rendimiento.
El coste de los errores innecesarios
Los controladores Kubernetes se destacan a la hora de volver a intentarlo cuando se presentan condiciones de error, pero esto tiene un coste. Estos reintentos pueden aumentar la presión sobre componentes como el Kube Controller Manager. Supervisar este tipo de errores es un elemento importante de las pruebas de escala.
Cuando se producen menos errores, es más fácil detectar los problemas en el sistema. Al asegurarnos periódicamente de que nuestros clústeres estén libres de errores antes de realizar operaciones importantes (como las actualizaciones), podemos simplificar los registros de solución de problemas cuando se producen imprevistos.
Ampliando nuestra visión
En los clústeres a gran escala con miles de nodos, no queremos buscar cuellos de botella de forma individual. En ProMQL podemos encontrar los valores más altos de un conjunto de datos mediante una función llamada topk; siendo K una variable, colocamos el número de elementos que queremos. Aquí utilizamos tres nodos para hacernos una idea de si todos los Kubelets del clúster están saturados. Hemos estado analizando la latencia hasta este punto, ahora veamos si el Kubelet descarta los eventos.
topk(3, increase(kubelet_pleg_discard_events{}[$__rate_interval]))
Desglosando esta afirmación.
-
Usamos la variable Grafana
$__rate_intervalpara asegurarnos de que obtiene las cuatro muestras que necesita. Esto evita un tema complejo de monitoreo con una variable simple. -
topknos da solo los mejores resultados y el número 3 limita esos resultados a tres. Esta es una función útil para las métricas de todo el clúster. -
{}Si nos dice que no hay filtros, normalmente pondría el nombre del trabajo, sea cual sea la regla de extracción. Sin embargo, dado que estos nombres varían, lo dejaremos en blanco.
Dividir el problema por la mitad
Para solucionar un cuello de botella en el sistema, adoptaremos el enfoque de encontrar una métrica que muestre que hay un problema en sentido ascendente o descendente, ya que esto nos permite dividir el problema por la mitad. También será un principio fundamental de la forma en que mostraremos los datos de nuestras métricas.
Un buen punto de partida para este proceso es el servidor de API, ya que nos permite ver si hay algún problema con una aplicación cliente o con el plano de control.
