Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Eficiencia de nodos y cargas de trabajo
Ser eficientes con nuestras cargas de trabajo y nodos reduce al complexity/cost mismo tiempo que aumenta el rendimiento y la escalabilidad. Hay muchos factores que se deben tener en cuenta a la hora de planificar esta eficiencia, y lo más fácil es pensar en términos de compensaciones en lugar de establecer una configuración de mejores prácticas para cada función. Analicemos estas ventajas y desventajas en profundidad en la siguiente sección.
Selección de nodos
Si utilizamos tamaños de nodo un poco más grandes (de 4 a 12 veces más), se aumenta el espacio disponible para ejecutar los pods, ya que reduce el porcentaje del nodo que se utiliza para «sobrecargas», por ejemplo, DaemonSets
nota
Dado que, por regla general, el k8s escala horizontalmente, para la mayoría de las aplicaciones no tiene sentido considerar el impacto en el rendimiento del NUMA como tamaño de los nodos, por lo que se recomienda un rango inferior a ese tamaño de nodo.
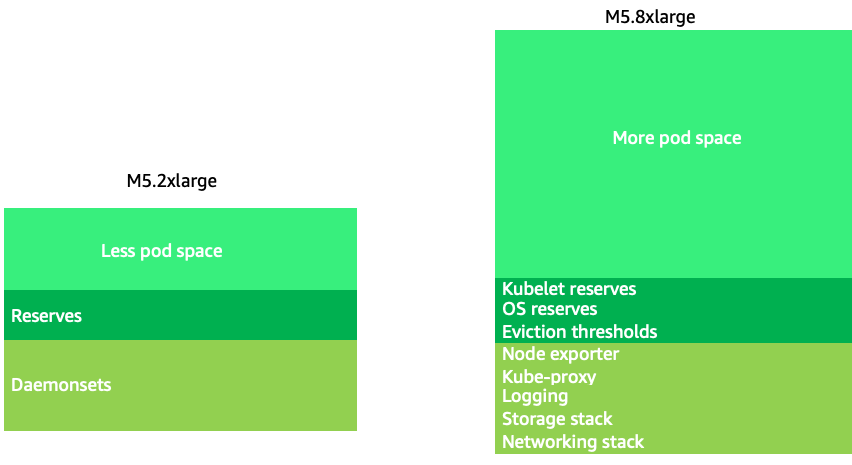
Los tamaños de nodos grandes nos permiten tener un mayor porcentaje de espacio utilizable por nodo. Sin embargo, este modelo se puede llevar al extremo si se empaqueta el nodo con tantos pods que provoque errores o sature el nodo. Supervisar la saturación de los nodos es clave para utilizar correctamente nodos de mayor tamaño.
La selección de nodos rara vez es una one-size-fits-all propuesta. A menudo, es mejor dividir las cargas de trabajo con tasas de abandono drásticamente diferentes en diferentes grupos de nodos. Las cargas de trabajo de lotes pequeños con una alta tasa de abandono se gestionarían mejor con la familia de instancias 4xlarge, mientras que una aplicación a gran escala, como Kafka, que ocupa 8 vCPU y tiene una baja tasa de abandono, se gestionaría mejor con la familia 12xlarge.
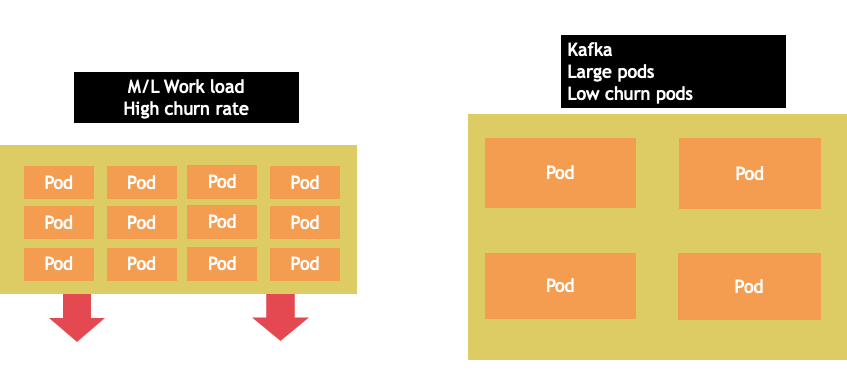
nota
Otro factor a tener en cuenta cuando los nodos son muy grandes es que los CGROUPS no ocultan la cantidad total de vCPU de la aplicación contenerizada. Los tiempos de ejecución dinámicos suelen generar un número no intencionado de subprocesos del sistema operativo, lo que crea una latencia que es difícil de solucionar. Para estas aplicaciones, se recomienda fijar la CPU
Empaquetado en contenedores de nodos
Reglas de Kubernetes frente a Linux
Hay dos conjuntos de reglas que debemos tener en cuenta al tratar las cargas de trabajo en Kubernetes. Las reglas del programador de Kubernetes, que usa el valor de la solicitud para programar los pods en un nodo, y luego lo que ocurre una vez programado el pod, que es el ámbito de Linux, no de Kubernetes.
Una vez finalizado el programador de Kubernetes, se aplica un nuevo conjunto de reglas: el Programador Completamente Justo de Linux (CFS). La conclusión clave es que Linux CFS no tiene el concepto de núcleo. Analizaremos por qué pensar en núcleos puede provocar problemas importantes a la hora de optimizar las cargas de trabajo para adaptarlas a mayor escala.
Pensando en núcleos
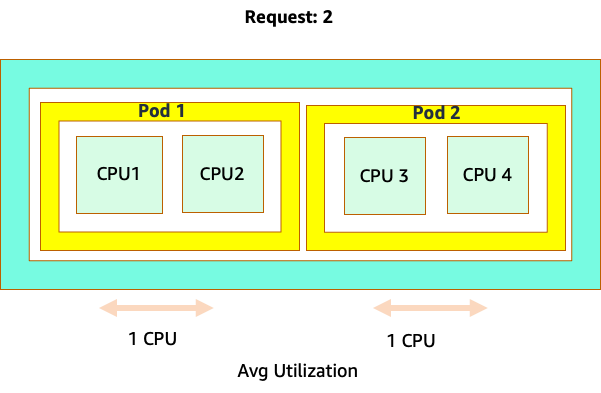
La confusión comienza porque el programador de Kubernetes sí tiene el concepto de núcleos. Desde la perspectiva de un programador de Kubernetes, si analizáramos un nodo con 4 pods de NGINX, cada uno con una solicitud de un conjunto de núcleos, el nodo tendría este aspecto.
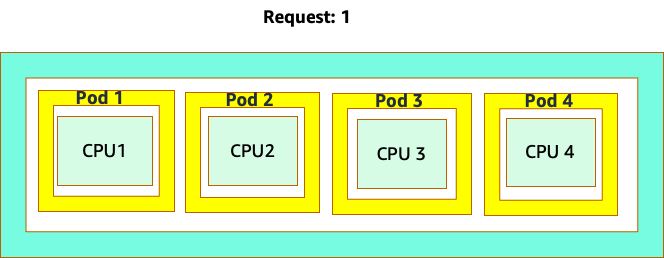
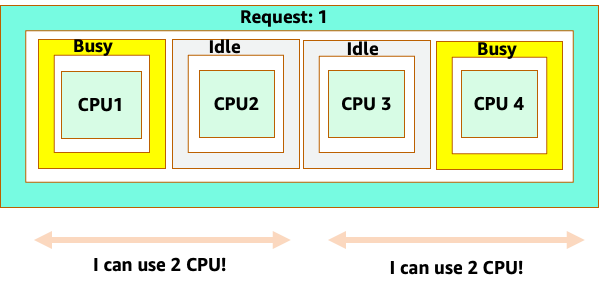
Sin embargo, hagamos un experimento mental sobre qué tan diferente se ve esto desde la perspectiva del CFS de Linux. Lo más importante que hay que recordar al utilizar el sistema CFS de Linux es que los contenedores ocupados (CGROUPS) son los únicos contenedores que se tienen en cuenta para el sistema compartido. En este caso, solo el primer contenedor está ocupado, por lo que se permite usar los 4 núcleos del nodo.
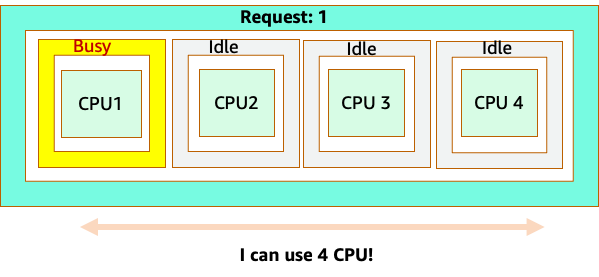
¿Por qué importa esto? Supongamos que realizamos nuestras pruebas de rendimiento en un clúster de desarrollo en el que una aplicación NGINX era el único contenedor ocupado de ese nodo. Cuando pasamos la aplicación a producción, ocurre lo siguiente: la aplicación NGINX necesita 4 vCPU de recursos; sin embargo, dado que todos los demás pods del nodo están ocupados, el rendimiento de nuestra aplicación se ve limitado.
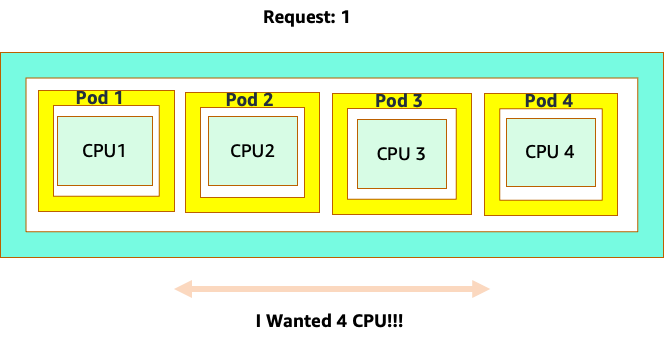
Esta situación nos llevaría a añadir más contenedores de forma innecesaria porque no permitíamos que nuestras aplicaciones se adaptaran a su «punto óptimo». Exploremos este importante concepto de a con un poco más de "sweet spot" detalle.
Aplicación: tamaño correcto
Cada aplicación tiene un punto determinado en el que no puede soportar más tráfico. Superar este punto puede aumentar los tiempos de procesamiento e incluso reducir el tráfico si se supera con creces este punto. Esto se conoce como punto de saturación de la aplicación. Para evitar problemas de escalado, debemos intentar escalar la aplicación antes de que alcance su punto de saturación. Llamemos a este punto el punto óptimo.
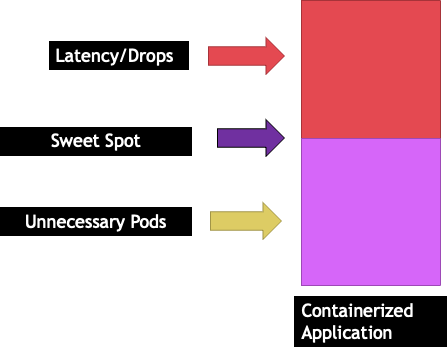
Tenemos que probar cada una de nuestras aplicaciones para entender su punto óptimo. Aquí no habrá una guía universal, ya que cada aplicación es diferente. Durante estas pruebas, intentamos entender cuál es la mejor métrica que muestre el punto de saturación de nuestras aplicaciones. A menudo, las métricas de uso se utilizan para indicar que una aplicación está saturada, pero esto puede provocar rápidamente problemas de escalado (analizaremos este tema en detalle en una sección posterior). Una vez que tengamos este «punto óptimo», podemos usarlo para escalar nuestras cargas de trabajo de manera eficiente.
Por el contrario, ¿qué pasaría si ampliáramos la escala mucho antes del punto óptimo y creáramos cápsulas innecesarias? Exploremos eso en la siguiente sección.
Expansión de vainas
Para ver cómo la creación de cápsulas innecesarias puede salirse de control rápidamente, veamos el primer ejemplo de la izquierda. La escala vertical correcta de este contenedor requiere aproximadamente dos V de CPUs uso cuando se gestionan 100 solicitudes por segundo. Sin embargo, si aprovisionáramos menos del valor de las solicitudes y las estableciéramos en medio núcleo, ahora necesitaríamos 4 módulos por cada uno que realmente necesitáramos. Para agravar aún más este problema, si nuestro HPA
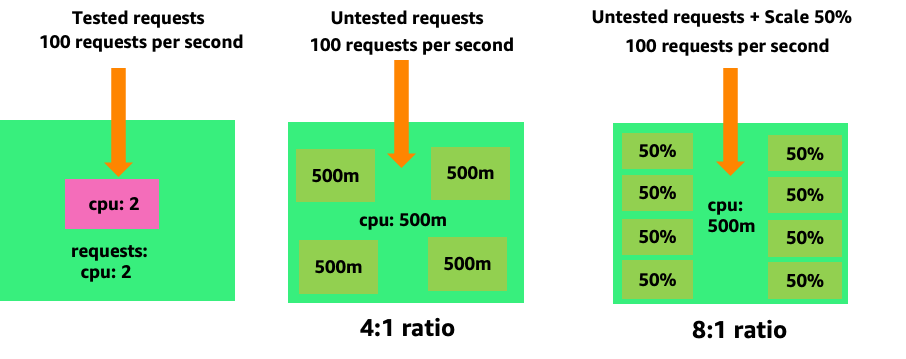
Al ampliar este problema, podemos ver rápidamente cómo se nos puede ir de las manos. Un despliegue de diez módulos con una configuración incorrecta podría llegar rápidamente a 80 módulos y disponer de la infraestructura adicional necesaria para su funcionamiento.
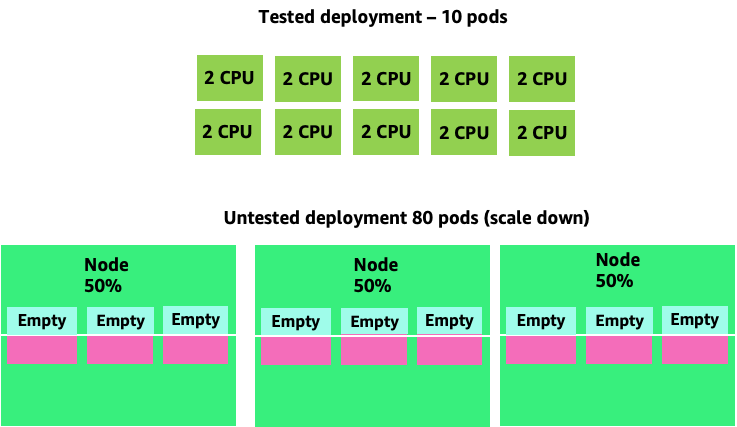
Ahora que entendemos el impacto de no permitir que las aplicaciones funcionen en su punto óptimo, volvamos al nivel de los nodos y preguntemos por qué es tan importante esta diferencia entre el programador de Kubernetes y el CFS de Linux.
Al escalar hacia arriba y hacia abajo con HPA, podemos tener un escenario en el que tengamos mucho espacio para asignar más módulos. Sería una mala decisión porque el nodo que se muestra a la izquierda ya utiliza el 100% de la CPU. En un escenario poco realista pero teóricamente posible, podríamos llegar al otro extremo, en el que nuestro nodo esté completamente lleno y, sin embargo, nuestra utilización de la CPU sea nula.
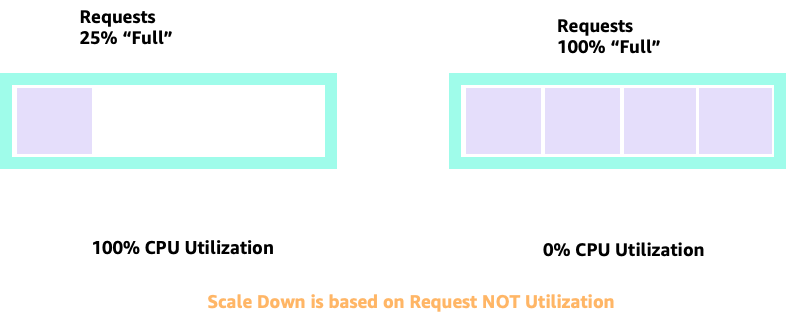
Configuración de solicitudes
Sería tentador fijar la solicitud en el valor ideal para esa aplicación, pero esto provocaría ineficiencias, como se muestra en el siguiente diagrama. En este caso, hemos establecido el valor de la solicitud en 2 vCPU; sin embargo, la utilización media de estos pods solo ejecuta 1 CPU la mayoría de las veces. Esta configuración provocaría que desperdiciáramos el 50% de nuestros ciclos de CPU, lo que sería inaceptable.
Esto nos lleva a la compleja respuesta al problema. No se puede pensar en la utilización de contenedores de forma aislada; hay que tener en cuenta las demás aplicaciones que se ejecutan en el nodo. En el siguiente ejemplo, los contenedores que son de naturaleza explosiva se mezclan con dos contenedores de bajo uso de la CPU que pueden tener limitaciones de memoria. De esta forma, permitimos que los contenedores lleguen a su punto óptimo sin sobrecargar el nodo.
Lo importante que debemos extraer de todo esto es que utilizar el concepto de núcleos del programador de Kubernetes para comprender el rendimiento de los contenedores de Linux puede llevar a una mala toma de decisiones, ya que no están relacionados entre sí.
nota
El CFS de Linux tiene sus puntos fuertes. Esto es especialmente cierto en el caso de las cargas de trabajo I/O basadas. Sin embargo, si su aplicación utiliza núcleos completos sin sidecars y no tiene I/O requisitos, la fijación de la CPU puede eliminar una gran parte de la complejidad de este proceso, por lo que se recomienda tener en cuenta estas advertencias.
Utilización frente a saturación
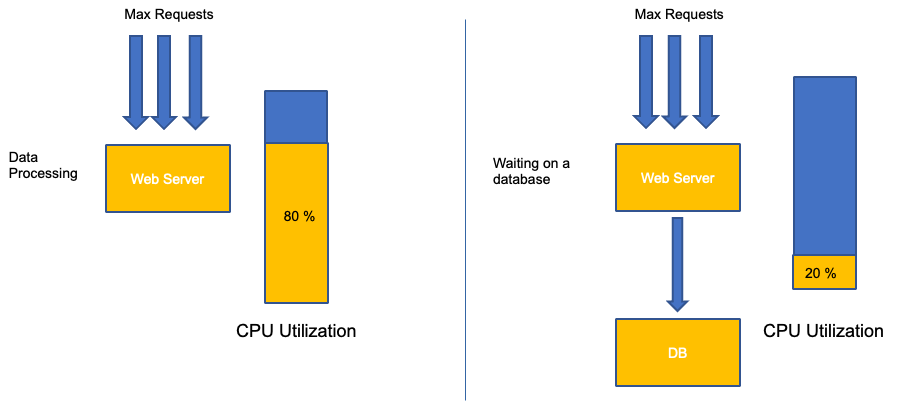
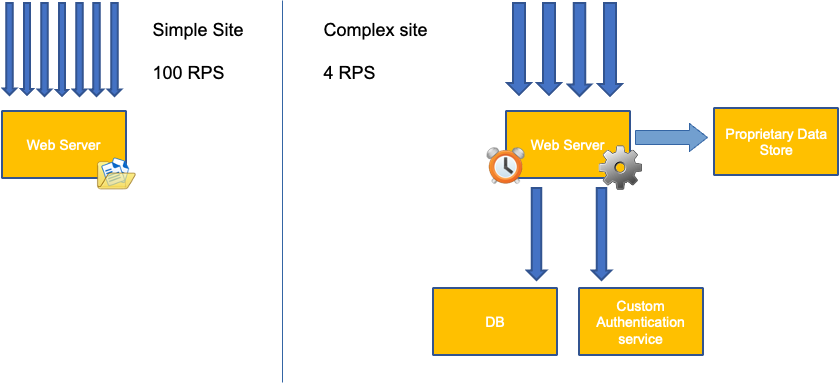
Un error común en el escalado de aplicaciones es utilizar únicamente el uso de la CPU para la métrica de escalado. En aplicaciones complejas, esto casi siempre es un mal indicador de que una aplicación está realmente saturada de solicitudes. En el ejemplo de la izquierda, vemos que todas nuestras solicitudes están llegando al servidor web, por lo que el uso de la CPU va registrando un buen ritmo con la saturación.
En las aplicaciones del mundo real, es probable que algunas de esas solicitudes sean atendidas por una capa de base de datos o una capa de autenticación, etc. En este caso más común, observe que la CPU no realiza el seguimiento debido a la saturación, ya que la solicitud está siendo atendida por otras entidades. En este caso, la CPU es un indicador muy pobre de saturación.
El uso de una métrica incorrecta en el rendimiento de las aplicaciones es la principal razón por la que se produce un escalado innecesario e impredecible en Kubernetes. Debes tener mucho cuidado al elegir la métrica de saturación correcta para el tipo de aplicación que utilices. Es importante tener en cuenta que no existe una recomendación única que se pueda dar a todos. Según el idioma utilizado y el tipo de aplicación en cuestión, existe un conjunto diverso de métricas de saturación.
Podríamos pensar que este problema se debe únicamente a la utilización de la CPU, sin embargo, otras métricas comunes, como la solicitud por segundo, también pueden tener exactamente el mismo problema que el descrito anteriormente. Tenga en cuenta que la solicitud también puede ir a capas de bases de datos, capas de autenticación, y no ser atendida directamente por nuestro servidor web, por lo que no es una métrica adecuada para medir la verdadera saturación del propio servidor web.
Lamentablemente, no hay respuestas fáciles a la hora de elegir la métrica de saturación correcta. Estas son algunas pautas a tener en cuenta:
-
Conozca el entorno de ejecución de su idioma: los lenguajes con varios subprocesos del sistema operativo reaccionarán de forma diferente que las aplicaciones con un solo subproceso, lo que afectará de forma diferente al nodo.
-
Conozca la escala vertical correcta: ¿cuánto búfer desea en la escala vertical de sus aplicaciones antes de escalar un nuevo pod?
-
¿Qué métricas reflejan realmente la saturación de su aplicación? La métrica de saturación de un productor de Kafka sería muy diferente a la de una aplicación web compleja.
-
¿Cómo se afectan entre sí todas las demás aplicaciones del nodo? El rendimiento de las aplicaciones no se realiza de forma aislada, sino que las demás cargas de trabajo del nodo tienen un impacto importante.
Para cerrar esta sección, sería fácil descartar lo anterior por ser demasiado complejo e innecesario. A menudo puede darse el caso de que tengamos un problema, pero desconozcamos la verdadera naturaleza del problema porque estamos utilizando métricas incorrectas. En la siguiente sección veremos cómo podría ocurrir eso.
Saturación de nodos
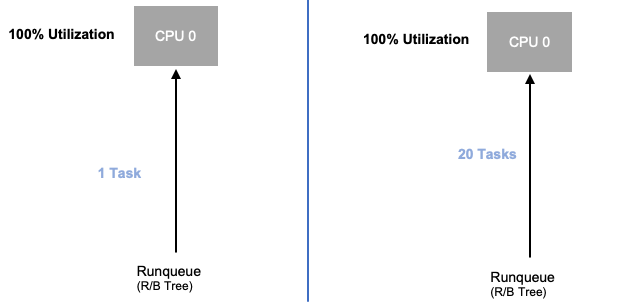
Ahora que hemos explorado la saturación de aplicaciones, veamos este mismo concepto desde el punto de vista de los nodos. Tomemos dos CPUs que se utilizan al 100% para ver la diferencia entre la utilización y la saturación.
La vCPU de la izquierda se utiliza al 100%, sin embargo, no hay otras tareas esperando a ejecutarse en esta vCPU, por lo que, en un sentido puramente teórico, esto es bastante eficiente. Mientras tanto, en el segundo ejemplo, tenemos 20 aplicaciones de un solo subproceso esperando ser procesadas por una vCPU. Las 20 aplicaciones ahora experimentarán algún tipo de latencia mientras esperan su turno para que la vCPU las procese. En otras palabras, la vCPU de la derecha está saturada.
No solo no veríamos este problema si solo analizáramos la utilización, sino que podríamos atribuir esta latencia a algo no relacionado, como las redes, lo que nos llevaría por el camino equivocado.
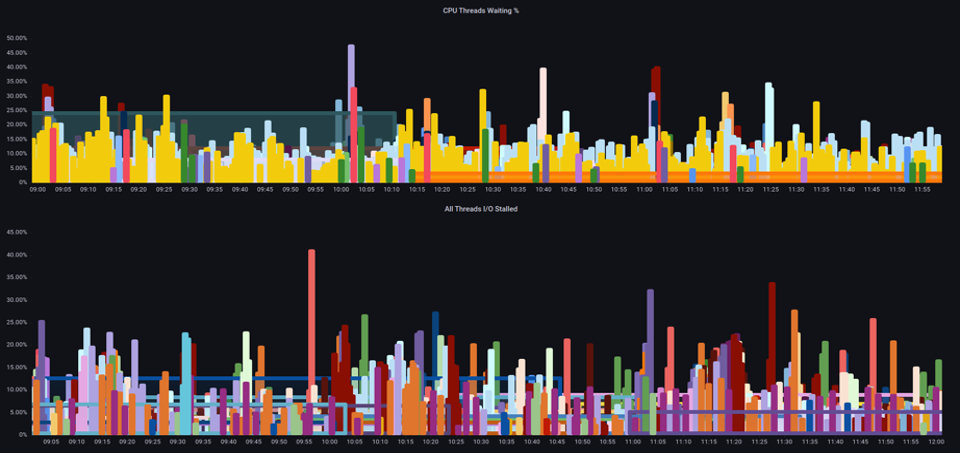
Al aumentar el número total de pods que se ejecutan en un nodo en un momento dado, es importante ver las métricas de saturación, no solo las métricas de uso, ya que podemos pasar por alto fácilmente el hecho de que hemos sobresaturado un nodo. Para esta tarea, podemos utilizar las métricas de información sobre el estancamiento de presión, como se muestra en el siguiente gráfico.
ProMQL: E/S estancada
topk(3, ((irate(node_pressure_io_stalled_seconds_total[1m])) * 100))
nota
Para obtener más información sobre las métricas de bloqueo de presión, consulte https://facebookmicrosites.github. io/psi/docs/overview
Con estas métricas, podemos saber si los subprocesos están esperando en la CPU o incluso si todos los subprocesos de la caja están estancados esperando un recurso como la memoria o I/O. For example, we could see what percentage every thread on the instance was stalled waiting on I/O durante un período de 1 minuto.
topk(3, ((irate(node_pressure_io_stalled_seconds_total[1m])) * 100))
Con esta métrica, podemos ver en el gráfico anterior que todos los hilos de la caja estaban parados el 45% del tiempo esperando I/O en el punto más alto, lo que significa que estábamos desperdiciando todos esos ciclos de CPU en ese minuto. Entender lo que está sucediendo puede ayudarnos a recuperar una cantidad significativa de tiempo de vCPU, lo que hace que el escalado sea más eficiente.
HPA V2
Se recomienda utilizar la versión autoscaling/v2 de la API HPA. Las versiones anteriores de la API HPA podían tener problemas de escalado en algunos casos extremos. También se limitaba a que los módulos solo se duplicaran durante cada paso de escalado, lo que generaba problemas en las implementaciones pequeñas que necesitaban escalarse rápidamente.
AutoScaling/v2 nos permite tener más flexibilidad a la hora de incluir varios criterios a partir de los cuales escalar y, además, una gran flexibilidad a la hora de utilizar métricas personalizadas y externas (distintas de las métricas de K8).
Por ejemplo, podemos escalar en función del mayor de los tres valores (ver más abajo). Escalamos si la utilización media de todos los módulos supera el 50%, si las métricas personalizadas indican que los paquetes por segundo de entrada superan la media de 1000 o si el objeto de entrada supera las 10 000 solicitudes por segundo.
nota
Esto es solo para demostrar la flexibilidad de la API de autoscalamiento. Recomendamos evitar las reglas demasiado complejas que pueden resultar difíciles de solucionar en producción.
apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: php-apache spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: php-apache minReplicas: 1 maxReplicas: 10 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 50 - type: Pods pods: metric: name: packets-per-second target: type: AverageValue averageValue: 1k - type: Object object: metric: name: requests-per-second describedObject: apiVersion: networking.k8s.io/v1 kind: Ingress name: main-route target: type: Value value: 10k
Sin embargo, nos dimos cuenta del peligro que supone utilizar este tipo de métricas para aplicaciones web complejas. En este caso, sería mejor utilizar una métrica personalizada o externa que refleje con precisión la saturación de nuestra aplicación en comparación con la utilización. HPAv2 lo permite al tener la capacidad de escalar de acuerdo con cualquier métrica; sin embargo, aún necesitamos encontrar esa métrica y exportarla a Kubernetes para su uso.
Por ejemplo, podemos ver el recuento de colas de subprocesos activos en Apache. Esto suele crear un perfil de escalado «más fluido» (pronto hablaremos de ese término). Si un subproceso está activo, no importa si ese subproceso está esperando en una capa de base de datos o atendiendo una solicitud de forma local; si se están utilizando todos los subprocesos de la aplicación, es un buen indicio de que la aplicación está saturada.
Podemos utilizar el agotamiento de los subprocesos como señal para crear un nuevo pod con un conjunto de subprocesos totalmente disponible. Esto también nos permite controlar el tamaño del búfer que queremos que absorba la aplicación en momentos de tráfico intenso. Por ejemplo, si tuviéramos un total de 10 subprocesos, escalarlos a 4 subprocesos utilizados frente a los 8 subprocesos utilizados tendría un gran impacto en el búfer del que disponemos al escalar la aplicación. Una configuración de 4 tendría sentido para una aplicación que necesita escalarse rápidamente con una carga pesada, mientras que una configuración de 8 sería más eficiente con nuestros recursos si tuviéramos tiempo suficiente para escalar, ya que el número de solicitudes aumenta de forma lenta o pronunciada con el tiempo.
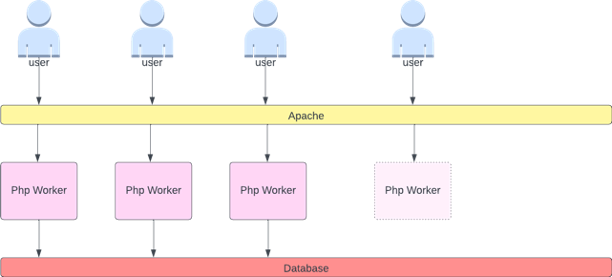
¿Qué queremos decir con el término «suave» cuando se trata de escalar? Observe el siguiente gráfico en el que utilizamos la CPU como métrica. Los módulos de esta implementación se incrementarán en poco tiempo, pasando de 50 módulos a 250 módulos, para luego volver a reducirse inmediatamente. Esto es muy ineficiente, el escalado es la principal causa de la pérdida de clientes en los clústeres.
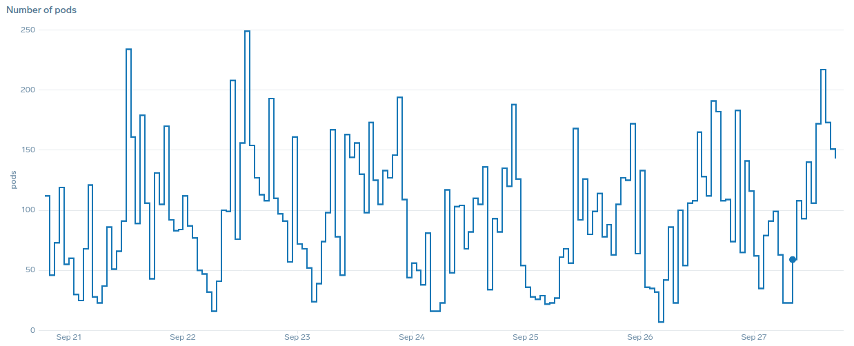
Observe cómo, después de cambiar a una métrica que refleje el punto óptimo correcto de nuestra aplicación (parte media del gráfico), podemos escalar sin problemas. Nuestro escalado ahora es eficiente y nuestros módulos pueden ampliarse completamente con el margen de maniobra que les proporcionábamos al ajustar la configuración de las solicitudes. Ahora, un grupo más pequeño de cápsulas está haciendo el trabajo que cientos de cápsulas hacían antes. Los datos del mundo real muestran que este es el factor número uno en la escalabilidad de los clústeres de Kubernetes.
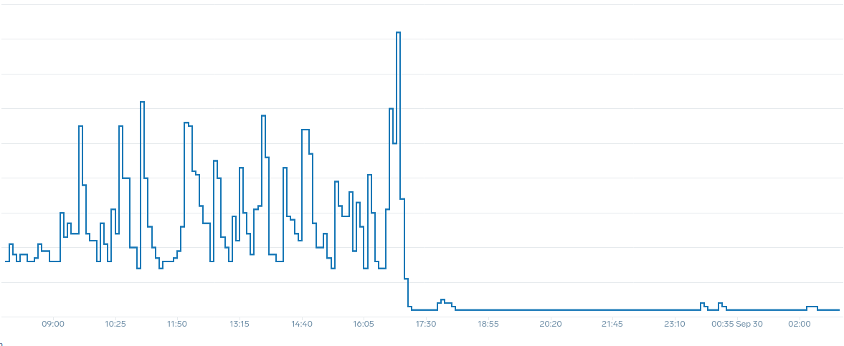
La conclusión clave es que la utilización de la CPU es solo una dimensión del rendimiento de las aplicaciones y los nodos. Utilizar el uso de la CPU como único indicador del estado de nuestros nodos y aplicaciones crea problemas de escalado, rendimiento y coste, conceptos todos ellos estrechamente relacionados. Cuanto más rendimiento tengan la aplicación y los nodos, menos tendrá que escalar, lo que, a su vez, reducirá sus costes.
Encontrar y usar las métricas de saturación correctas para escalar una aplicación en particular también le permite monitorear y alertar sobre los verdaderos cuellos de botella de esa aplicación. Si se omite este paso fundamental, los informes sobre problemas de rendimiento serán difíciles, si no imposibles, de entender.
Establecer límites de CPU
Para completar esta sección sobre temas mal entendidos, trataremos los límites de la CPU. En resumen, los límites son metadatos asociados al contenedor que tiene un contador que se restablece cada 100 ms. Esto ayuda a Linux a realizar un seguimiento de cuántos recursos de CPU utiliza un contenedor específico en todo el nodo en un período de 100 ms.
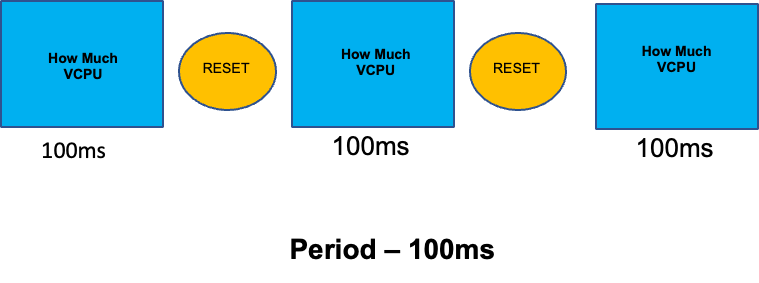
Un error común al establecer límites es suponer que la aplicación es de un solo subproceso y que solo se ejecuta en su vCPU «`asignada"`. En la sección anterior, aprendimos que el CFS no asigna núcleos y, en realidad, un contenedor que ejecute grandes grupos de subprocesos programará todas las CPU virtuales disponibles en la caja.
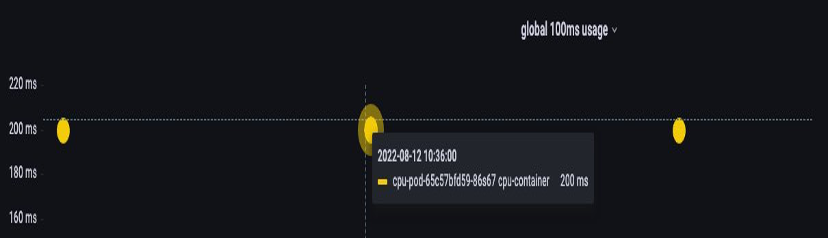
Si 64 subprocesos del sistema operativo se ejecutan en 64 núcleos disponibles (desde la perspectiva de los nodos de Linux), haremos que la factura total del tiempo de CPU utilizado en un período de 100 ms sea bastante alta después de sumar el tiempo de ejecución de todos esos 64 núcleos. Como esto solo puede ocurrir durante un proceso de recolección de basura, es muy fácil pasar por alto algo como esto. Por eso es necesario utilizar métricas para asegurarnos de que tenemos el uso correcto a lo largo del tiempo antes de intentar establecer un límite.
Afortunadamente, tenemos una forma de ver exactamente la cantidad de vCPU que utilizan todos los subprocesos de una aplicación. Usaremos la métrica container_cpu_usage_seconds_total para este propósito.
Como la lógica de regulación se produce cada 100 ms y esta métrica es una métrica por segundo, utilizaremos PromQL para igualar este período de 100 ms. Si desea profundizar en este trabajo de declaraciones de ProMQL, consulte el siguiente blog.
Consulta de ProMQL:
topk(3, max by (pod, container)(rate(container_cpu_usage_seconds_total{image!="", instance="$instance"}[$__rate_interval]))) / 10

Una vez que consideremos que tenemos el valor correcto, podemos poner el límite a la producción. Luego, es necesario comprobar si nuestra solicitud se está retrasando debido a algo inesperado. Esto lo podemos hacer mirando container_cpu_throttled_seconds_total
topk(3, max by (pod, container)(rate(container_cpu_cfs_throttled_seconds_total{image!=``""``, instance=``"$instance"``}[$__rate_interval]))) / 10
Memoria
La asignación de memoria es otro ejemplo en el que es fácil confundir el comportamiento de programación de Kubernetes con el comportamiento de Linux. CGroup Este es un tema más matizado, ya que se han producido cambios importantes en la forma en que la CGroup versión 2 gestiona la memoria en Linux y Kubernetes ha cambiado su sintaxis para reflejar estos cambios; lee este blog para obtener más información.
A diferencia de las solicitudes de CPU, las solicitudes de memoria no se utilizan una vez finalizado el proceso de programación. Esto se debe a que no podemos comprimir la memoria en la CGroup versión 1 de la misma manera que lo hacemos con la CPU. Esto nos deja solo con los límites de memoria, que están diseñados para actuar a prueba de fallos en caso de pérdidas de memoria al cerrar el módulo por completo. Se trata de una propuesta de todo o nada, pero ahora se nos han dado nuevas formas de abordar este problema.
En primer lugar, es importante entender que configurar la cantidad correcta de memoria para los contenedores no es tan sencillo como parece. El sistema de archivos de Linux utilizará la memoria como caché para mejorar el rendimiento. Esta memoria caché aumentará con el paso del tiempo y puede resultar difícil saber cuánta memoria es buena tener para ella, pero se puede recuperar sin que ello repercuta de forma significativa en el rendimiento de las aplicaciones. Esto suele provocar una mala interpretación del uso de la memoria.
Tener la capacidad de «comprimir» la memoria fue uno de los principales impulsores de la CGroup versión 2. Para obtener más información sobre por qué era necesaria la CGroup V2, consulte la presentación
Afortunadamente, Kubernetes ahora tiene el concepto de «tener» y «menos». memory.min memory.high requests.memory Esto nos da la opción de liberar agresivamente esta memoria en caché para que la usen otros contenedores. Una vez que el contenedor alcanza el límite máximo de memoria, el núcleo puede recuperar la memoria de ese contenedor de forma agresiva hasta el valor establecido en. memory.min Esto nos da más flexibilidad cuando un nodo está bajo presión de memoria.
La pregunta clave es: ¿qué valor memory.min establecer? Aquí es donde entran en juego las métricas de bloqueo de la presión de la memoria. Podemos usar estas métricas para detectar la «pérdida de memoria» a nivel de contenedor. Luego, podemos usar controladores como fbtaxmemory.min acumulación de memoria y establecer el memory.min valor de forma dinámica en esta configuración.
Resumen
Para resumir la sección, es fácil combinar los siguientes conceptos:
-
Utilización y saturación
-
Reglas de rendimiento de Linux con la lógica del programador de Kubernetes
Se debe tener mucho cuidado de mantener estos conceptos separados. El rendimiento y la escala están relacionados en un nivel profundo. El escalado innecesario crea problemas de rendimiento, lo que a su vez crea problemas de escalado.
