Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Plano de control de Kubernetes
El plano de control de Kubernetes consta del servidor API de Kubernetes, el administrador del controlador de Kubernetes, el programador y otros componentes necesarios para que Kubernetes funcione. Los límites de escalabilidad de estos componentes varían según lo que se ejecute en el clúster, pero las áreas que tienen un mayor impacto en la escalabilidad incluyen la versión de Kubernetes, la utilización y el escalado de nodos individuales.
Limite la carga de trabajo y la sobrecarga de nodos
importante
Para evitar alcanzar los límites de las API en el plano de control, debe limitar los picos de escalado que aumentan el tamaño del clúster en porcentajes de dos dígitos a la vez (por ejemplo, de 1000 nodos a 1100 nodos o de 4000 a 4500 pods a la vez).
El plano de control de EKS se ampliará automáticamente a medida que el clúster crezca, pero hay límites en cuanto a la rapidez con la que se escalará. Al crear un clúster de EKS por primera vez, el plano de control no podrá ampliarse inmediatamente a cientos de nodos o miles de módulos. Para obtener más información sobre cómo EKS ha realizado mejoras de escalado, consulte esta entrada de blog
El escalado de aplicaciones de gran tamaño requiere que la infraestructura se adapte y esté completamente preparada (por ejemplo, calentar los balanceadores de carga). Para controlar la velocidad de escalado, asegúrese de escalarlo en función de las métricas correctas para su aplicación. Es posible que el escalado de la CPU y la memoria no prediga con precisión las limitaciones de la aplicación, por lo que utilizar métricas personalizadas (por ejemplo, las solicitudes por segundo) en el escalador automático de módulos horizontales (HPA) de Kubernetes puede ser una mejor opción de escalado.
Para usar una métrica personalizada, consulta los ejemplos de la documentación de Kubernetes.
Escale nodos y módulos de forma segura
Sustituya las instancias de ejecución prolongada
La sustitución periódica de los nodos mantiene el clúster en buen estado, ya que evita desviaciones en la configuración y problemas que solo se producen después de un tiempo de actividad prolongado (por ejemplo, pérdidas lentas de memoria). El reemplazo automatizado le proporcionará buenos procesos y prácticas para actualizar los nodos y aplicar parches de seguridad. Si todos los nodos del clúster se sustituyen con regularidad, se necesitará menos esfuerzo para mantener procesos separados para el mantenimiento continuo.
Usa la configuración de tiempo de vida (TTL) de Karpenter para reemplazar las instancias después de que hayan estado ejecutándose durante un período de tiempo específico. Los grupos de nodos autogestionados pueden usar esta max-instance-lifetime configuración para realizar ciclos de nodos automáticamente. Los grupos de nodos gestionados no disponen actualmente de esta función, pero puedes realizar un seguimiento de la solicitud aquí GitHub
Elimine los nodos infrautilizados
Puede eliminar los nodos cuando no tengan cargas de trabajo en ejecución utilizando el umbral de reducción del escalador automático de clústeres de Kubernetes con la configuración del aprovisionador --scale-down-utilization-thresholdttlSecondsAfterEmpty
Utilice los presupuestos para la interrupción de los módulos y el cierre seguro de los nodos
Para eliminar los pods y los nodos de un clúster de Kubernetes, es necesario que los controladores realicen actualizaciones en varios recursos (por ejemplo). EndpointSlices Hacerlo con frecuencia o demasiado rápido puede provocar una ralentización del servidor de API e interrupciones en las aplicaciones a medida que los cambios se propaguen a los controladores. Los presupuestos relacionados con las interrupciones de los
Usa la caché del lado del cliente cuando ejecutes Kubectl
El uso ineficiente del comando kubectl puede añadir carga adicional al servidor de API de Kubernetes. Debes evitar ejecutar scripts o automatizaciones que usen kubectl de forma repetida (por ejemplo, en un bucle for) o ejecutar comandos sin una caché local.
kubectltiene una caché del lado del cliente que almacena en caché la información de descubrimiento del clúster para reducir la cantidad de llamadas a la API necesarias. La caché está habilitada de forma predeterminada y se actualiza cada 10 minutos.
Si ejecutas kubectl desde un contenedor o sin una caché del lado del cliente, es posible que tengas problemas de limitación de la API. Se recomienda conservar la caché del clúster montando el para evitar realizar llamadas innecesarias a la --cache-dir API.
Inhabilita la compresión kubectl
Si inhabilitas la compresión kubectl en tu archivo kubeconfig, puedes reducir el uso de la API y la CPU del cliente. De forma predeterminada, el servidor comprimirá los datos enviados al cliente para optimizar el ancho de banda de la red. Esto añade una carga de CPU al cliente y al servidor por cada solicitud y, si se dispone de un ancho de banda adecuado, se pueden reducir la sobrecarga y la latencia si se dispone de un ancho de banda adecuado. Para deshabilitar la compresión, puedes usar el --disable-compression=true indicador o configurarlo disable-compression: true en tu archivo kubeconfig.
apiVersion: v1
clusters:
- cluster:
server: serverURL
disable-compression: true
name: cluster
Escalador automático de clústeres compartidos
El escalador automático de clústeres de Kubernetes se ha probado para escalar hasta 1000 nodos
ClusterAutoscaler-1
autoscalingGroups: - name: eks-core-node-grp-20220823190924690000000011-80c1660e-030d-476d-cb0d-d04d585a8fcb maxSize: 50 minSize: 2 - name: eks-data_m1-20220824130553925600000011-5ec167fa-ca93-8ca4-53a5-003e1ed8d306 maxSize: 450 minSize: 2 - name: eks-data_m2-20220824130733258600000015-aac167fb-8bf7-429d-d032-e195af4e25f5 maxSize: 450 minSize: 2 - name: eks-data_m3-20220824130553914900000003-18c167fa-ca7f-23c9-0fea-f9edefbda002 maxSize: 450 minSize: 2
ClusterAutoscaler-2
autoscalingGroups: - name: eks-data_m4-2022082413055392550000000f-5ec167fa-ca86-6b83-ae9d-1e07ade3e7c4 maxSize: 450 minSize: 2 - name: eks-data_m5-20220824130744542100000017-02c167fb-a1f7-3d9e-a583-43b4975c050c maxSize: 450 minSize: 2 - name: eks-data_m6-2022082413055392430000000d-9cc167fa-ca94-132a-04ad-e43166cef41f maxSize: 450 minSize: 2 - name: eks-data_m7-20220824130553921000000009-96c167fa-ca91-d767-0427-91c879ddf5af maxSize: 450 minSize: 2
Prioridad e imparcialidad de la API
Descripción general
Para evitar sobrecargarse durante los períodos de aumento de solicitudes, el servidor de API limita el número de solicitudes a bordo que puede tener pendientes en un momento dado. Cuando se supere este límite, el servidor de API empezará a rechazar las solicitudes y devolverá a los clientes un código de respuesta HTTP 429 para indicar «Demasiadas solicitudes». Es preferible que el servidor descarte las solicitudes y haga que los clientes lo intenten más tarde a no establecer límites en el número de solicitudes por parte del servidor y sobrecargar el plano de control, lo que podría provocar una disminución del rendimiento o una falta de disponibilidad.
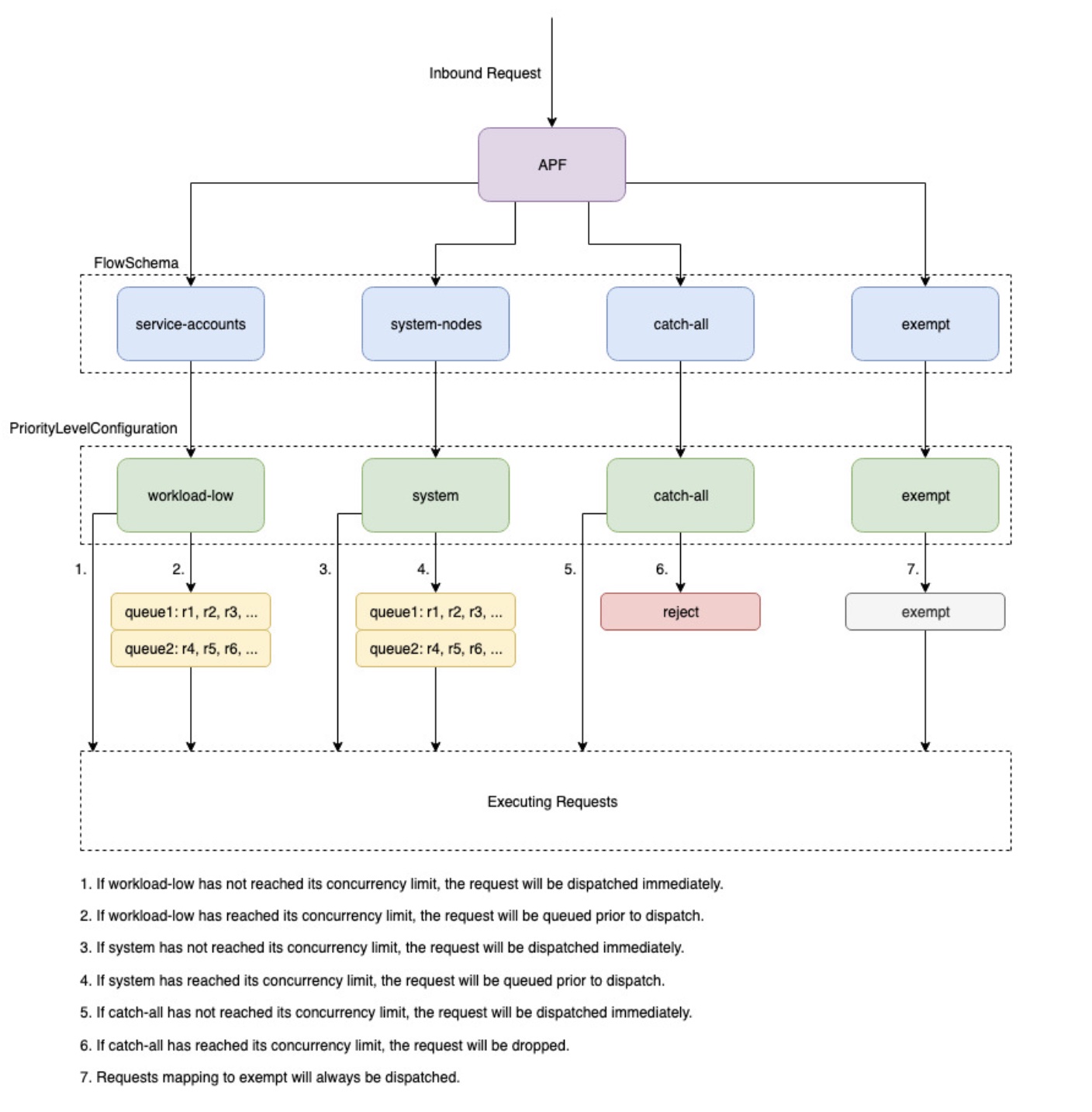
El mecanismo que utiliza Kubernetes para configurar cómo se dividen estas solicitudes entrantes entre los distintos tipos de solicitudes se denomina API Priority and Fairness.--max-requests-inflight --max-mutating-requests-inflight EKS utiliza los valores predeterminados de 400 y 200 solicitudes para estos indicadores, lo que permite enviar un total de 600 solicitudes en un momento dado. Sin embargo, a medida que amplía el plano de control para adaptarlo a tamaños más grandes en respuesta al aumento de la utilización y la pérdida de carga de trabajo, también aumenta la cuota de solicitudes durante el vuelo hasta 2000 (sujeto a cambios). La APF especifica cómo se subdivide esta cuota de solicitudes durante el vuelo entre los distintos tipos de solicitudes. Tenga en cuenta que los planos de control EKS tienen una alta disponibilidad y cuentan con al menos 2 servidores API registrados en cada clúster. Esto significa que el número total de solicitudes en vuelo que tu clúster puede gestionar es el doble (o superior si se amplía aún más horizontalmente) de la cuota de vuelo establecida por kube-apiserver. Esto equivale a varios miles en los clústeres de EKS más grandes. requests/second
Hay dos tipos de objetos de Kubernetes, llamados PriorityLevelConfigurations y FlowSchemas configuran cómo se divide el número total de solicitudes entre los distintos tipos de solicitudes. El servidor API mantiene estos objetos automáticamente y EKS usa la configuración predeterminada de estos objetos para la versión secundaria de Kubernetes en cuestión. PriorityLevelConfigurations representan una fracción del número total de solicitudes permitidas. Por ejemplo, a la carga de trabajo máxima PriorityLevelConfiguration se le asignan 98 de un total de 600 solicitudes. La suma de las solicitudes asignadas a todas PriorityLevelConfigurations será igual a 600 (o ligeramente superior a 600, ya que el servidor API redondeará si a un nivel determinado se le concede una fracción de la solicitud). Para comprobar PriorityLevelConfigurations el número de solicitudes asignadas a cada uno de tu clúster, puedes ejecutar el siguiente comando. Estos son los valores predeterminados en EKS 1.32:
$ kubectl get --raw /metrics | grep apiserver_flowcontrol_nominal_limit_seats apiserver_flowcontrol_nominal_limit_seats{priority_level="catch-all"} 13 apiserver_flowcontrol_nominal_limit_seats{priority_level="exempt"} 0 apiserver_flowcontrol_nominal_limit_seats{priority_level="global-default"} 49 apiserver_flowcontrol_nominal_limit_seats{priority_level="leader-election"} 25 apiserver_flowcontrol_nominal_limit_seats{priority_level="node-high"} 98 apiserver_flowcontrol_nominal_limit_seats{priority_level="system"} 74 apiserver_flowcontrol_nominal_limit_seats{priority_level="workload-high"} 98 apiserver_flowcontrol_nominal_limit_seats{priority_level="workload-low"} 245
El segundo tipo de objeto es. FlowSchemas Las solicitudes del servidor API con un conjunto determinado de propiedades se clasifican en la misma categoría FlowSchema. Estas propiedades incluyen el usuario autenticado o los atributos de la solicitud, como el grupo de API, el espacio de nombres o el recurso. A FlowSchema también especifica a qué se debe asignar PriorityLevelConfiguration este tipo de solicitud. Los dos objetos juntos dicen: «Quiero que este tipo de solicitudes se tengan en cuenta para este porcentaje de solicitudes a bordo». Cuando una solicitud llegue al servidor de API, comprobará cada una de ellas FlowSchemas hasta que encuentre una que coincida con todas las propiedades requeridas. Si varios FlowSchemas coinciden con una solicitud, el servidor de API elegirá la FlowSchema que tenga la menor prioridad coincidente, que se especifique como propiedad en el objeto.
El mapeo de FlowSchemas a se PriorityLevelConfigurations puede ver con este comando:
$ kubectl get flowschemas NAME PRIORITYLEVEL MATCHINGPRECEDENCE DISTINGUISHERMETHOD AGE MISSINGPL exempt exempt 1 <none> 7h19m False eks-exempt exempt 2 <none> 7h19m False probes exempt 2 <none> 7h19m False system-leader-election leader-election 100 ByUser 7h19m False endpoint-controller workload-high 150 ByUser 7h19m False workload-leader-election leader-election 200 ByUser 7h19m False system-node-high node-high 400 ByUser 7h19m False system-nodes system 500 ByUser 7h19m False kube-controller-manager workload-high 800 ByNamespace 7h19m False kube-scheduler workload-high 800 ByNamespace 7h19m False kube-system-service-accounts workload-high 900 ByNamespace 7h19m False eks-workload-high workload-high 1000 ByUser 7h14m False service-accounts workload-low 9000 ByUser 7h19m False global-default global-default 9900 ByUser 7h19m False catch-all catch-all 10000 ByUser 7h19m False
PriorityLevelConfigurations puede tener un tipo de cola, rechazo o exención. Para los tipos Queue y Reject, se aplica un límite al número máximo de solicitudes en vuelo para ese nivel de prioridad; sin embargo, el comportamiento varía cuando se alcanza ese límite. Por ejemplo, Workload-high PriorityLevelConfiguration usa el tipo Queue y tiene 98 solicitudes disponibles para el controlador-administrador, el controlador de punto final, el programador, los controladores relacionados con eks y desde los pods que se ejecutan en el espacio de nombres del sistema kube. Como se utiliza el tipo Queue, el servidor de API intentará mantener las solicitudes en la memoria y esperará que el número de solicitudes en vuelo baje a menos de 98 antes de que se agote el tiempo de espera. Si se agota el tiempo de espera de una solicitud determinada o si ya hay demasiadas solicitudes en cola, el servidor API no tiene más remedio que descartar la solicitud y devolver al cliente un 429. Ten en cuenta que la puesta en cola puede impedir que una solicitud reciba un 429, pero esto conlleva el inconveniente de aumentar la end-to-end latencia de la solicitud.
Ahora consideremos el catch-all FlowSchema que se asigna al catch-all con el tipo Reject PriorityLevelConfiguration . Si los clientes alcanzan el límite de 13 solicitudes durante el vuelo, el servidor de API no hará cola y las descartará al instante con un código de respuesta de 429. Por último, las solicitudes asignadas a un PriorityLevelConfiguration tipo Exento nunca recibirán un 429 y siempre se enviarán de forma inmediata. Se usa para las solicitudes de alta prioridad, como las solicitudes healthz o las solicitudes que provienen del grupo system:masters.
Supervisión de las APF y de las solicitudes descartadas
Para confirmar si se está descartando alguna solicitud debido a la APF, se apiserver_flowcontrol_rejected_requests_total pueden monitorear las métricas del servidor de API para comprobar qué solicitudes se ven afectadas FlowSchemas y. PriorityLevelConfigurations Por ejemplo, esta métrica muestra que se FlowSchema descartaron 100 solicitudes de las cuentas de servicio debido a que se agotó el tiempo de espera de las solicitudes en las colas con poca carga de trabajo:
% kubectl get --raw /metrics | grep apiserver_flowcontrol_rejected_requests_total
apiserver_flowcontrol_rejected_requests_total{flow_schema="service-accounts",priority_level="workload-low",reason="time-out"} 100
Para comprobar qué tan cerca PriorityLevelConfiguration está una determinada persona de recibir 429 segundos o de experimentar un aumento de la latencia debido a las colas, puedes comparar la diferencia entre el límite de simultaneidad y la simultaneidad en uso. En este ejemplo, tenemos un búfer de 100 solicitudes.
% kubectl get --raw /metrics | grep 'apiserver_flowcontrol_nominal_limit_seats.*workload-low' apiserver_flowcontrol_nominal_limit_seats{priority_level="workload-low"} 245 % kubectl get --raw /metrics | grep 'apiserver_flowcontrol_current_executing_seats.*workload-low' apiserver_flowcontrol_current_executing_seats{flow_schema="service-accounts",priority_level="workload-low"} 145
Para comprobar si algunas solicitudes están PriorityLevelConfiguration en cola pero no necesariamente se descartan, se apiserver_flowcontrol_current_inqueue_requests puede hacer referencia a la métrica de:
% kubectl get --raw /metrics | grep 'apiserver_flowcontrol_current_inqueue_requests.*workload-low'
apiserver_flowcontrol_current_inqueue_requests{flow_schema="service-accounts",priority_level="workload-low"} 10
Otras métricas útiles de Prometheus incluyen:
-
apiserver_flowcontrol_dispatched_requests_total
-
apiserver_flowcontrol_request_execution_seconds
-
apiserver_flowcontrol_request_wait_duration_seconds
Consulte la documentación preliminar para obtener una lista completa de las métricas de la APF.
Evitar solicitudes rechazadas
Evite los 429 modificando su carga de trabajo
Cuando la APF cancela solicitudes por PriorityLevelConfiguration superar el número máximo permitido de solicitudes durante el vuelo, los clientes de la zona afectada FlowSchemas pueden reducir el número de solicitudes que se están ejecutando en un momento dado. Esto se puede lograr reduciendo el número total de solicitudes realizadas durante el período en el que se están produciendo 429 solicitudes. Tenga en cuenta que las solicitudes de larga duración, como las costosas llamadas a listas, son especialmente problemáticas porque se consideran solicitudes en vuelo durante todo el tiempo que se estén ejecutando. Reducir el número de estas costosas solicitudes u optimizar la latencia de estas llamadas de lista (por ejemplo, reduciendo la cantidad de objetos recuperados por solicitud o pasando a utilizar una solicitud de vigilancia) puede ayudar a reducir la simultaneidad total que requiere la carga de trabajo determinada.
Evita los 429 segundos cambiando la configuración del APF
aviso
Cambie la configuración de APF predeterminada únicamente si sabe lo que está haciendo. Los ajustes de APF mal configurados pueden provocar la interrupción de las solicitudes del servidor API y provocar importantes interrupciones en la carga de trabajo.
Otro enfoque para evitar que se rechacen las solicitudes consiste en cambiar la configuración predeterminada FlowSchemas o PriorityLevelConfigurations instalada en los clústeres de EKS. EKS instala la configuración inicial predeterminada para FlowSchemas y PriorityLevelConfigurations para la versión secundaria de Kubernetes en cuestión. El servidor API reconciliará automáticamente estos objetos con sus valores predeterminados si se modifican, a menos que la siguiente anotación en los objetos esté configurada como falsa:
metadata:
annotations:
apf.kubernetes.io/autoupdate-spec: "false"
A un nivel alto, la configuración del APF se puede modificar de la siguiente manera:
-
Asigne más capacidad a bordo a las solicitudes que le interesen.
-
Aísle las solicitudes costosas o que no sean esenciales y que puedan agotar la capacidad de otros tipos de solicitudes.
Esto se puede lograr cambiando el valor predeterminado FlowSchemas PriorityLevelConfigurations o creando nuevos objetos de estos tipos. Los operadores pueden aumentar los valores de los PriorityLevelConfigurations objetos relevantes assuredConcurrencyShares para aumentar la fracción de solicitudes durante el vuelo que se les asignan. Además, el número de solicitudes que se pueden poner en cola en un momento dado también se puede aumentar si la aplicación puede gestionar la latencia adicional provocada por las solicitudes que se ponen en cola antes de enviarse.
Como alternativa, se pueden crear PriorityLevelConfigurations objetos FlowSchema y objetos nuevos que sean específicos de la carga de trabajo del cliente. Tenga en cuenta que si se asigna más assuredConcurrencyShares a los ya existentes PriorityLevelConfigurations o a los nuevos PriorityLevelConfigurations , se reducirá el número de solicitudes que pueden gestionar otros grupos, ya que el límite general se mantendrá en 600 en vuelo por servidor API.
Al realizar cambios en los valores predeterminados de APF, estas métricas deben supervisarse en un clúster que no sea de producción para garantizar que los cambios en la configuración no provoquen 429 errores imprevistos:
-
Todos
apiserver_flowcontrol_rejected_requests_totaldeberían monitorizar la métrica para garantizar que ningún FlowSchemas grupo comience a descartar solicitudes. -
Los valores correspondientes a
apiserver_flowcontrol_nominal_limit_seatsyapiserver_flowcontrol_current_executing_seatsdeben compararse para garantizar que la simultaneidad utilizada no corra el riesgo de superar el límite de ese nivel de prioridad.
Un caso de uso común para definir una nueva FlowSchema y PriorityLevelConfiguration es el aislamiento. Supongamos que queremos aislar las llamadas a eventos de listas de larga duración procedentes de los pods para incluirlas en su propia cuota de solicitudes. Esto evitará que las solicitudes importantes de los pods que utilizan las cuentas FlowSchema de servicio existentes reciban 429 y se queden sin capacidad de solicitudes. Recuerde que el número total de solicitudes a bordo es limitado; sin embargo, en este ejemplo se muestra que la configuración del APF se puede modificar para dividir mejor la capacidad de solicitudes para una carga de trabajo determinada:
Ejemplo de FlowSchema objeto para aislar las solicitudes de eventos de la lista:
apiVersion: flowcontrol.apiserver.k8s.io/v1
kind: FlowSchema
metadata:
name: list-events-default-service-accounts
spec:
distinguisherMethod:
type: ByUser
matchingPrecedence: 8000
priorityLevelConfiguration:
name: catch-all
rules:
- resourceRules:
- apiGroups:
- '*'
namespaces:
- default
resources:
- events
verbs:
- list
subjects:
- kind: ServiceAccount
serviceAccount:
name: default
namespace: default
-
Esto FlowSchema captura todas las llamadas a eventos de la lista realizadas por las cuentas de servicio en el espacio de nombres predeterminado.
-
La prioridad coincidente 8000 es inferior al valor de 9000 utilizado por las cuentas de servicio existentes, por FlowSchema lo que estas llamadas a eventos de la lista coincidirán con list-events-default-service las cuentas de servicio y no con las cuentas de servicio.
-
Estamos utilizando el catch-all PriorityLevelConfiguration para aislar estas solicitudes. Este grupo solo permite que estas llamadas a eventos de lista de larga duración utilicen 13 solicitudes en vuelo. Los pods empezarán a recibir 429 en cuanto intenten emitir más de 13 de estas solicitudes de forma simultánea.
Recuperando recursos en el servidor de API
Obtener información del servidor de API es un comportamiento esperado para clústeres de cualquier tamaño. A medida que se amplía la cantidad de recursos del clúster, la frecuencia de las solicitudes y el volumen de datos pueden convertirse rápidamente en un obstáculo para el plano de control y provocar latencia y lentitud de la API. Dependiendo de la gravedad de la latencia, si no se tiene cuidado, se producirán tiempos de inactividad inesperados.
Saber qué es lo que se solicita y con qué frecuencia es el primer paso para evitar este tipo de problemas. Esta es una guía para limitar el volumen de consultas en función de las mejores prácticas de escalado. Las sugerencias de esta sección se proporcionan por orden, empezando por las opciones que mejor escalan.
Utilice informadores compartidos
Al crear controladores y sistemas de automatización que se integren con la API de Kubernetes, a menudo necesitará obtener información de los recursos de Kubernetes. Si buscas estos recursos con regularidad, se puede producir una carga significativa en el servidor de la API.
Si utilizas un informador
Los controladores deben evitar sondear los recursos de todo el clúster sin etiquetas ni selectores de campo, especialmente en clústeres grandes. Cada encuesta sin filtrar requiere que etcd envíe una gran cantidad de datos innecesarios a través del servidor API para que el cliente los filtre. Al filtrar en función de las etiquetas y los espacios de nombres, puedes reducir la cantidad de trabajo que el servidor de API debe realizar para cumplir con las solicitudes y los datos enviados al cliente.
Optimiza el uso de la API de Kubernetes
Cuando llames a la API de Kubernetes con controladores personalizados o automatizados, es importante que limites las llamadas solo a los recursos que necesitas. Sin límites, puedes provocar una carga innecesaria en el servidor de la API, etc.
Se recomienda utilizar el argumento watch siempre que sea posible. Sin argumentos, el comportamiento predeterminado es enumerar los objetos. Para usar watch en lugar de list, puedes añadirlo ?watch=true al final de tu solicitud de API. Por ejemplo, para colocar todos los pods en el espacio de nombres predeterminado con un reloj, usa:
/api/v1/namespaces/default/pods?watch=true
Si publicas objetos, debes limitar el alcance de lo que publicas y la cantidad de datos devueltos. Puedes limitar los datos devueltos añadiendo limit=500 argumentos a las solicitudes. El fieldSelector argumento y la /namespace/ ruta pueden ser útiles para asegurarte de que tus listas tengan un alcance tan limitado como sea necesario. Por ejemplo, para enumerar solo los pods en ejecución en el espacio de nombres predeterminado, usa la siguiente ruta de API y los argumentos siguientes.
/api/v1/namespaces/default/pods?fieldSelector=status.phase=Running&limit=500
O haz una lista de todos los pods que se ejecutan con:
/api/v1/pods?fieldSelector=status.phase=Running&limit=500
Otra opción para limitar las llamadas de vigilancia o los objetos de la lista es utilizarla resourceVersions, que puedes consultar en la documentación de KubernetesresourceVersion argumento, recibirá la versión más reciente disponible, que requiere una lectura de quórum etcd, que es la lectura más cara y lenta de la base de datos. La ResourceVersion depende de los recursos que esté intentando consultar y se encuentra en el campo. metadata.resourseVersion Esto también se recomienda en caso de utilizar llamadas de vigilancia y no solo llamadas de lista
Hay una opción especial resourceVersion=0 disponible que devolverá los resultados de la caché del servidor de la API. Esto puede reducir la carga de etcd, pero no admite la paginación.
/api/v1/namespaces/default/pods?resourceVersion=0
Se recomienda usar watch con una ResourceVersion configurada como el valor conocido más reciente recibido de la lista o visualización anterior. Esto se gestiona automáticamente en client-go. Sin embargo, se sugiere verificarlo dos veces si está utilizando un cliente k8s en otros idiomas.
/api/v1/namespaces/default/pods?watch=true&resourceVersion=362812295
Si llamas a la API sin ningún argumento, será la que requiera más recursos para el servidor de la API y etcd. Esta llamada incluirá todos los pods de todos los espacios de nombres sin paginar ni limitar el alcance y requerirá que se lea quórum desde etcd.
/api/v1/pods
Evita el estruendo de las manadas DaemonSet
A DaemonSet garantiza que todos los nodos (o algunos) ejecuten una copia de un pod. A medida que los nodos se unen al clúster, el daemonset-controller crea pods para esos nodos. A medida que los nodos abandonan el clúster, esos pods se recolectan como basura. Al eliminar un DaemonSet , se limpiarán los pods que haya creado.
Algunos usos típicos de a DaemonSet son:
-
Ejecutar un daemon de almacenamiento en clúster en cada nodo
-
Ejecutar un daemon de recopilación de registros en cada nodo
-
Ejecutar un daemon de monitoreo de nodos en cada nodo
En clústeres con miles de nodos, la creación de uno nuevo DaemonSet, la actualización de uno o el aumento del número de nodos puede provocar una carga elevada en el plano de control. DaemonSet Si los DaemonSet pods emiten costosas solicitudes de servidor API al arrancar el pod, pueden provocar un uso elevado de los recursos en el plano de control debido a la gran cantidad de solicitudes simultáneas.
En condiciones normales de funcionamiento, puedes usar RollingUpdate a para garantizar el despliegue gradual de nuevos DaemonSet pods. Con una estrategia de RollingUpdate actualización, tras actualizar una DaemonSet plantilla, el mando elimina las DaemonSet cápsulas antiguas y crea nuevas DaemonSet cápsulas automáticamente y de forma controlada. Se DaemonSet ejecutará como máximo un pod en cada nodo durante todo el proceso de actualización. Puede realizar una implementación gradual maxUnavailable configurando 1, maxSurge 0 y minReadySeconds 60. Si no especificas una estrategia de actualización, Kubernetes utilizará de forma predeterminada la creación de a RollingUpdate con maxUnavailable 1, maxSurge 0 y 0. minReadySeconds
minReadySeconds: 60
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 0
maxUnavailable: 1
A RollingUpdate garantiza el despliegue gradual de los nuevos DaemonSet pods si el ya DaemonSet está creado y tiene el número esperado de Ready pods en todos los nodos. En determinadas condiciones, las estrategias no contemplan problemas de rebaño estrepitosos. RollingUpdate
Evita que las manadas atronen sobre la creación DaemonSet
De forma predeterminada, independientemente de la RollingUpdate configuración, el daemonset-controlador del nodo kube-controller-manager creará cápsulas para todos los nodos coincidentes de forma simultánea al crear uno nuevo. DaemonSet Para forzar el despliegue gradual de los pods después de crear un DaemonSet, puedes usar una o. NodeSelector NodeAffinity Esto creará un nodo DaemonSet que no coincida con ningún nodo y, a continuación, podrás actualizarlos gradualmente para que puedan ejecutar un pod desde allí DaemonSet a una velocidad controlada. Puedes seguir este enfoque:
-
Añada una etiqueta a todos los nodos para
run-daemonset=false.
kubectl label nodes --all run-daemonset=false
-
Crea la tuya DaemonSet con una
NodeAffinityconfiguración que coincida con cualquier nodo sinrun-daemonset=falseetiqueta. Al principio, esto hará DaemonSet que no tengas los pods correspondientes.
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: run-daemonset
operator: NotIn
values:
- "false"
-
Quita la
run-daemonset=falseetiqueta de tus nodos a una velocidad controlada. Puedes usar este script bash como ejemplo:
#!/bin/bash
nodes=$(kubectl get --raw "/api/v1/nodes" | jq -r '.items | .[].metadata.name')
for node in ${nodes[@]}; do
echo "Removing run-daemonset label from node $node"
kubectl label nodes $node run-daemonset-
sleep 5
done
-
Si lo desea, elimine la
NodeAffinityconfiguración de su DaemonSet objeto. Ten en cuenta que esto también activaráRollingUpdatey reemplazará gradualmente todos los DaemonSet módulos existentes a medida que la DaemonSet plantilla haya cambiado.
Evite el estruendo de las manadas al escalar los nodos
Al igual que en DaemonSet la creación, la creación de nuevos nodos a un ritmo rápido puede provocar el inicio simultáneo de un gran número de DaemonSet módulos. Deberías crear nuevos nodos a una velocidad controlada para que el controlador cree nodos DaemonSet a la misma velocidad. Si esto no es posible, puedes hacer que los nuevos nodos inicialmente no sean aptos para los existentes DaemonSet utilizandoNodeAffinity. A continuación, podéis añadir gradualmente una etiqueta a los nuevos nodos para que el daemonset-controlador cree cápsulas a una velocidad controlada. Puedes seguir este enfoque:
-
Añada una etiqueta a todos los nodos existentes para
run-daemonset=true
kubectl label nodes --all run-daemonset=true
-
Actualiza tu DaemonSet
NodeAffinityconfiguración para que coincida con cualquier nodo que tenga unarun-daemonset=trueetiqueta. Ten en cuenta que esto también activaráRollingUpdatey reemplazará gradualmente todos los DaemonSet pods existentes debido a un cambio en la DaemonSet plantilla. Debes esperarRollingUpdatea que se complete antes de continuar con el siguiente paso.
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: run-daemonset
operator: In
values:
- "true"
-
Cree nuevos nodos en el clúster. Tenga en cuenta que estos nodos no tendrán la
run-daemonset=trueetiqueta, por lo que no coincidirán con esos nodos. DaemonSet -
Añada la
run-daemonset=trueetiqueta a sus nuevos nodos (que actualmente no tienen larun-daemonsetetiqueta) a una velocidad controlada. Puedes usar este script bash como ejemplo:
#!/bin/bash
nodes=$(kubectl get --raw "/api/v1/nodes?labelSelector=%21run-daemonset" | jq -r '.items | .[].metadata.name')
for node in ${nodes[@]}; do
echo "Adding run-daemonset=true label to node $node"
kubectl label nodes $node run-daemonset=true
sleep 5
done
-
Si lo desea, elimine la
NodeAffinityconfiguración de su DaemonSet objeto y elimine larun-daemonsetetiqueta de todos los nodos.
Evita que las actualizaciones se apoderen de las multitudes DaemonSet
Una RollingUpdate política solo respetará la maxUnavailable configuración de los DaemonSet pods que estén configurados. Ready Si a DaemonSet tiene solo NotReady pods o un gran porcentaje de NotReady ellos y actualizas su plantilla, el daemonset-controlador creará nuevos pods simultáneamente para todos los pods. NotReady Esto puede provocar problemas con el ruido de las manadas si hay un número importante de ellas, por ejemplo, si las NotReady cápsulas se bloquean continuamente o no obtienen imágenes.
Para forzar el despliegue gradual de los pods cuando actualizas a DaemonSet y los hay, puedes cambiar temporalmente la estrategia de actualización de los NotReady pods de a. DaemonSet RollingUpdate OnDelete De este modoOnDelete, después de actualizar una DaemonSet plantilla, el mando crea nuevos pods tras eliminar manualmente los antiguos para que puedas controlar el lanzamiento de nuevos pods. Puedes seguir este enfoque:
-
Compruebe si tiene
NotReadycápsulas en su DaemonSet. -
Si no, puedes actualizar la DaemonSet plantilla de forma segura y la
RollingUpdateestrategia garantizará una implementación gradual. -
En caso afirmativo, primero debes actualizar la tuya DaemonSet para usar la
OnDeleteestrategia.
updateStrategy: type: OnDelete
-
A continuación, actualiza tu DaemonSet plantilla con los cambios necesarios.
-
Tras esta actualización, puedes eliminar los DaemonSet pods antiguos emitiendo solicitudes de eliminación de pods a un ritmo controlado. Puedes usar este script bash como ejemplo en el que el DaemonSet nombre es fluentd-elasticsearch en el espacio de nombres del sistema kube:
#!/bin/bash
daemonset_pods=$(kubectl get --raw "/api/v1/namespaces/kube-system/pods?labelSelector=name%3Dfluentd-elasticsearch" | jq -r '.items | .[].metadata.name')
for pod in ${daemonset_pods[@]}; do
echo "Deleting pod $pod"
kubectl delete pod $pod -n kube-system
sleep 5
done
-
Por último, puedes volver a la estrategia anterior. DaemonSet
RollingUpdate
